
23/1/26 18:00更新 ※Hugging faceへのアップロード手順にフォルダパスの確認方法を追加しました。
22/12/20 15:00 更新 ※googleドライブからファイルをダウンロードする方法とHugging Faceへファイルをアップロードする方法を方法を追加しました。合わせてgoogleドライブのリンクを変更してあります。最新版をダウンロードするか、googleドライブからダウンロードする方法とHugging Faceへアップロードする方法からコードをコピペして追加してください。
22/12/14 11:00 更新 ※ Extensions(拡張機能)をインストールするためのコードを追加しました。
更新内容 : 拡張機能をインストールする際に”AssertionError: extension access disabled because of command line flags“とエラーが出てインストールできない問題を解決しました。合わせてgoogleドライブのリンクを変更してあります。更新前にダウンロードしている方は再ダウンロード、またはExtensionsのインストールの項目からコードをコピペしてください。
22/12/10 22:00 更新 ※一部コードが間違っていたので修正しました。
更新内容:3.web-uiを最新バージョンに更新するの部分のコードを修正しました。合わせてgoogleドライブのリンクを変更してあります。更新前にダウンロードしている方はダウンロードしなおすか、3.web-uiを最新バージョンに更新するの項目からコードを追記してください。
今回は、paperspaceを使いAIイラストの生成、HyperNetworkやDreamBoothなどの学習をAUTOMATIC1111版のweb uiを使い、クラウド上で行う方法を行う為の、paperspaceへのweb-uiの導入方法を書いていきます。
前回、【Novel AI】HyperNetworkをcolabの無料枠で行う方法【waifu diffusion】にて、Colabの無料枠でHyperNetworkを行う方法を書きました。
しかし、colabはランタイムを切断してしまうと環境が全て消えてしまうので、学習毎にweb-uiのインストールから始めなければいけません。無料枠では利用できる時間が短いため無駄な時間は過ごしたくありません。しかも、colabの月額プランは内容が変わっており、今までは定額で使い放題でしたが、新しい内容では、更新日にポイントが付与され、1時間の利用でポイントが消費されていき、そのポイントが無くなったら使えなくなるとのこと(ポイントの追加購入は可能)。
なのでDreamBoothやHyperNetworkなどで長時間学習させたい場合には不向きになってしまいました。
他のクラウドGPUも見てみましたが、時間単位での課金のものが多く、定額制のものは少ないです。
そこで見つけたのがpaperspaceです。こちらはプランがFree(無料)、Pro(8ドル)、Growth(39ドル)の3つ用意されており、それぞれ使えるGPUが違います。無料プランでもVRAM8GBのGPUを使うことができます。ProプランではVRAM16GBのGPUを使えるので、学習するだけならProプランでも可能。ちなみに、GrowthプランでVRAM80GBのGPUがあります。
もちろん、学習用ではなく、単純にAIイラストの生成用として使っても問題ありません。
また、支払いにVプリカを使えるので、海外サービスにクレジットカードを登録したくないという方でも安心です。
kohya版LoRAをpaperspaceで動かす方法を書きました → 【AIイラスト】kohya版LoRAをpaperspaceで動かす方法【LoRA】
ローカルで学習する為のPCは以下の記事を参考にしてください。
SDXL 1.0も動かせる!AIイラストの生成・学習におすすめのPCを紹介【Stable Diffusion】
paperspaceに登録する
まずはpaperspaceのページへいきましょう。
ちなみに下記のリンクから登録すると10ドル分のクレジットを入手できるようです。

それでは登録していきましょう。といっても登録なんて基本どのサイトも同じなので、登録ボタンの場所を説明して終わります。
右上のSIGN UP FREEから登録できます。登録するときにgradientとCOREの2つ選べると思いますが、gradientを選択してください。
ちなみに、COREはPCを遠隔操作するサービスのようです。VRChatとかMMDを動かしてる人がいるので、クラウドゲーミングPCが必要な方は調べてみると良いかもしれません。
スポンサーリンク
環境構築
それでは!みんな大好きAUTOMATIC1111版のweb uiの環境を作成していきましょう。
といっても、必要なものはこちらで用意しているので、あとはポチポチやるだけです。
以下のgoogleドライブから必要なファイルをダウンロードしてください。

ファイル名は”paperspace_web-ui_onlinegamernikki.ipynb“です。
それでは必要なファイルをダウンロードできたので次に進んでいきます。
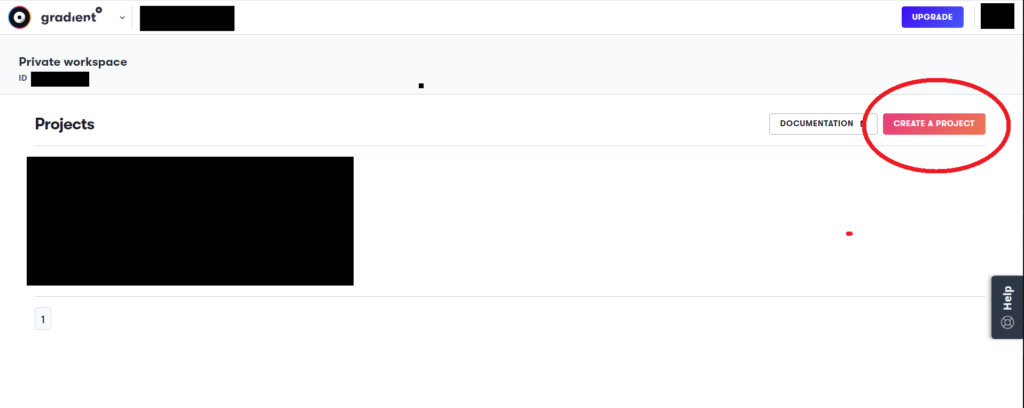
赤丸で囲ったCREATE A PROJECTから新しいプロジェクトを作成します。
すると、プロジェクト名を入力するか聞かれるので、適当に名前を付けてCREATEをクリックしましょう。名前なんて気にしない!というのであればデフォルトで付いている名前でもOK。
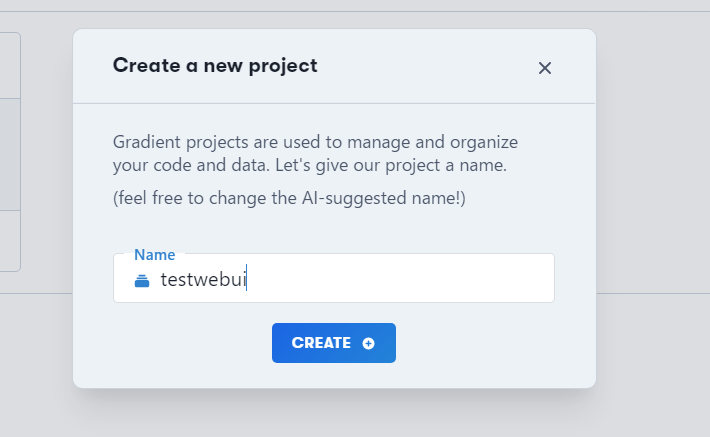
ここでは”testwebui”としました。
CREATEを押したら以下のような画面になるので、CREATEをクリックしてノートブックの作成に入ります。
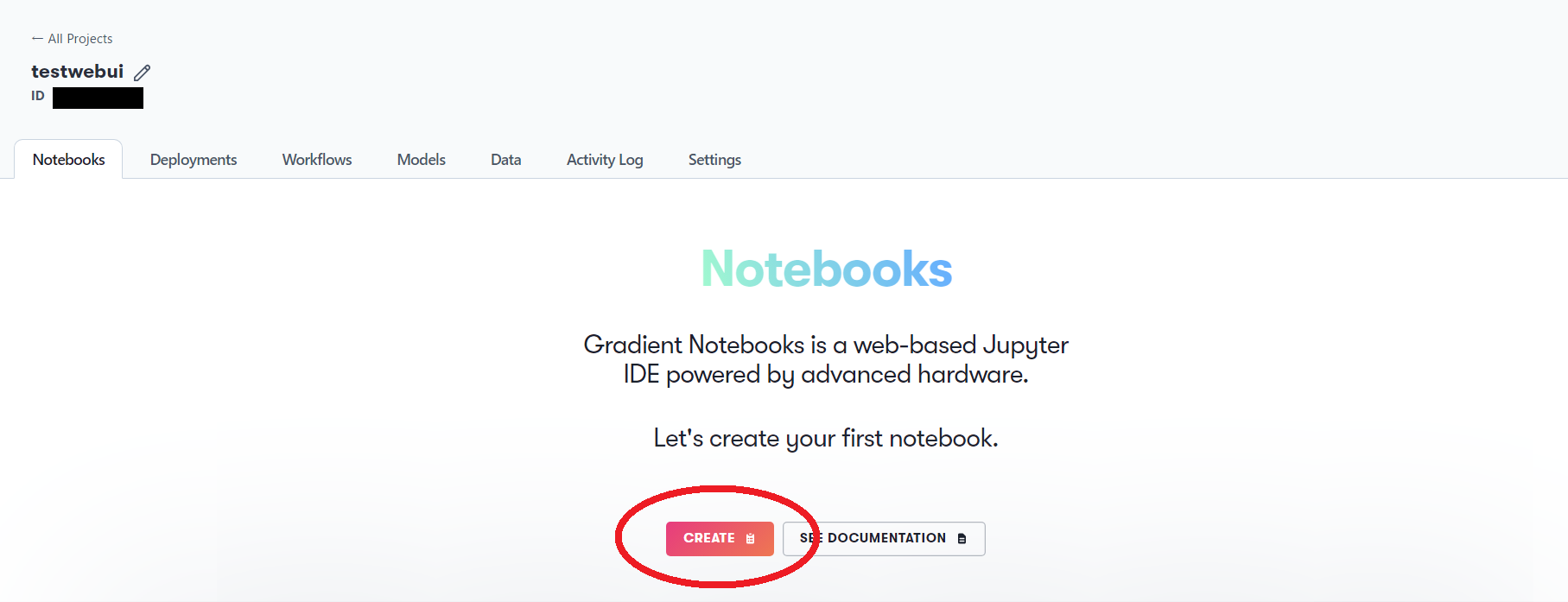
選択する項目を最初に説明します。
1.Select a runtime : Start from Scratch
2.Select a machine : 使いたいGPU (Freeと書いてあるGPUは定額で使い放題。$0.51/hrなどと値段が書いてあるのは、1時間単位で課金されるGPUです。グレーになっているGPUは空きがない状態なので、時間をおいて再アクセスすれば使えるようになっているかもしれません。)
3.Auto-shutdown timeout : 6Hours (自動で切断する時間。特に理由がなければ最大の6時間でOK)
Advanced optionsはいじらなくて大丈夫です。

隣にStable Diffusionとありますが、それは選択しないでください。
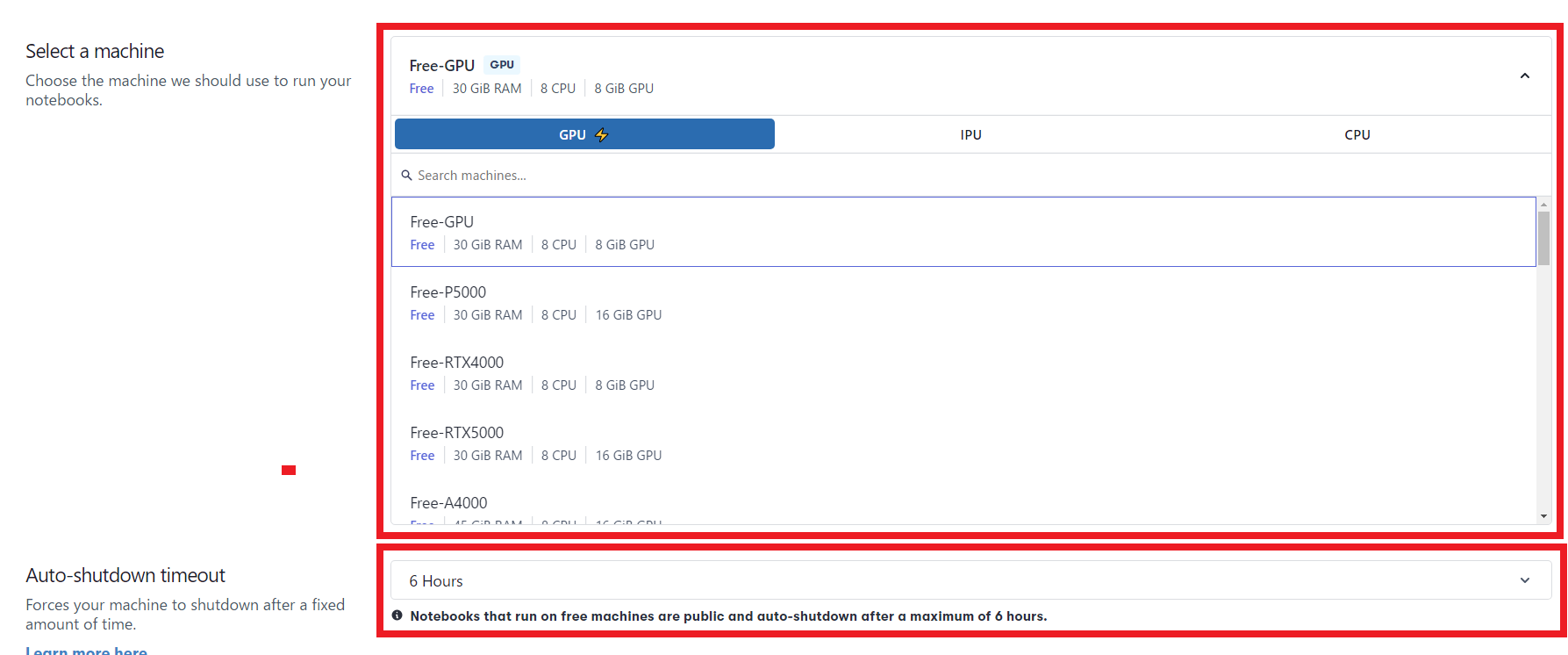
GPUとシャットダウンタイムはお好みで。
終わったらSTART NOTEBOOKをクリックしましょう。
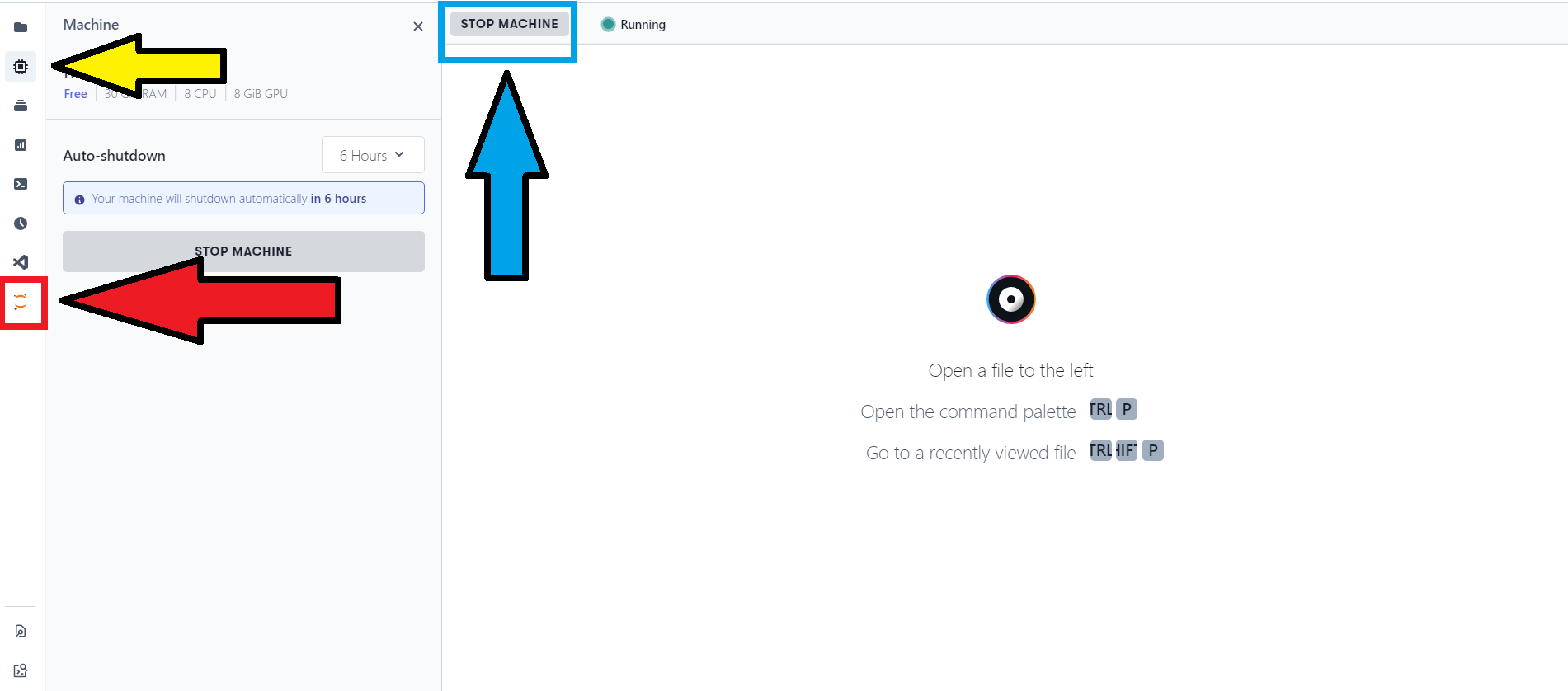
起動するためには赤矢印のアイコンをクリックしJupyterLabを立ち上げます。
また、青矢印で指している部分は、現在はSTOP MACHINEとなっていますが、ノートブックを切断したあと、再度起動する場合にはSTART MACHINEとなっているので、それをクリックして起動してあげなければなりません。
また、再度起動する場合、前回起動時に使っていたGPUに空きがなく使えない場合があるので、その場合は黄色矢印のアイコンからGPUを変更するか、前回使ってたGPUが使えるようになるまで待機してください。
スポンサーリンク
それではJupyterLabを立ち上げましょう。

JupyterLabを立ち上げると、このような画面になります。先ほど、googleドライブからダウンロードしたファイルを、赤枠で囲った部分へドラック&ドロップでアップロードしてください。
アップロードが完了したら、そのファイルをダブルクリックで開いてください。
ちなみに、自分でipynbファイルを作成する場合はNotebook欄のPython 3ボタンをクリックすると作れます。その場合”Untitled.ipynb”というファイルが作成されているので、ファイルを右クリックしRenameから名前を変更しておくと良いでしょう。
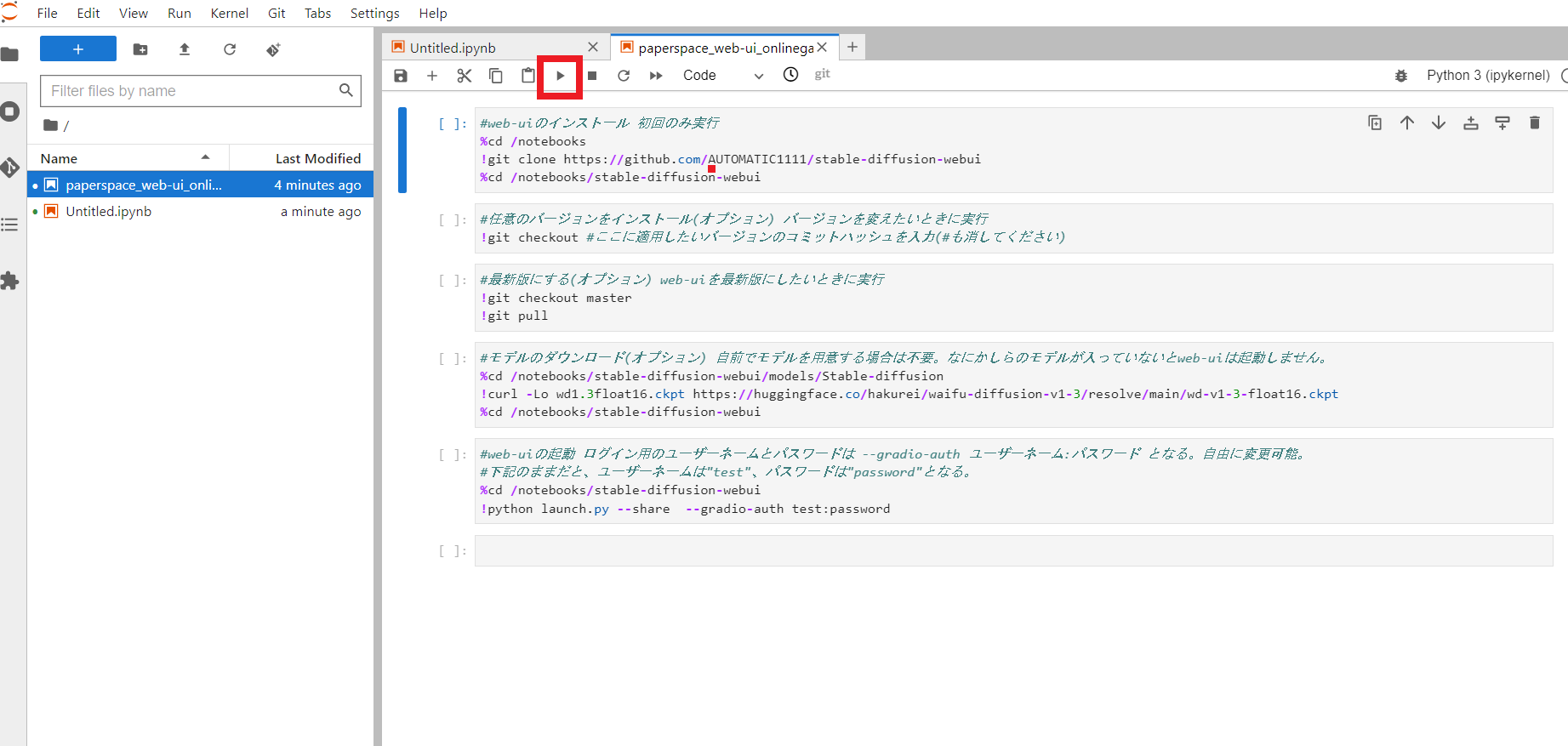
基本的にはこのセルを上から順番に実行すればOKです。
実行方法は、実行したいセルをクリックし、画面上の再生ボタンをクリックです。
セルの内容を上から順に説明していくと
1.web-uiをインストールします(初回のみ実行。2回目以降は無視してOK)
2.web-uiのバージョンを変更する。
3.web-uiを最新バージョンに更新する。(コードが間違っていたので修正)
4.モデルをダウンロードする。(このセルを実行するとwaifu diffusionがダウンロードされます)
5.web-uiの起動。
となっています。
※3.のコードが間違っていたので修正してください。 ※最新のpaperspace_web-ui_onlinegamernikki.ipynbをダウンロードした方は不要です。
<修正前>
#最新版にする(オプション) web-uiを最新版にしたいときに実行
!git checkout master
!git pull上記のコードを以下のように修正してください。
<修正後>
#最新版にする(オプション) web-uiを最新版にしたいときに実行
%cd /notebooks/stable-diffusion-webui
!git checkout master
!git pullそれぞれ細かい説明をすると、1.のインストールはそのままの意味です。
2.のバージョン変更は、1.のインストールだと、実行時の最新版がインストールされるので、ローカルで動かしていたバージョンと合わせたいという場合にはバージョンを落とす必要があります。
その為にはこのセルの実行が必要です。以下の文字を該当するバージョンのcommit hashに置き換えてください。
#ここに適用したいバージョンのコミットハッシュを入力(#も消してください)3.はweb-uiのバージョンを最新版にします。
4.はweb-uiはモデルデータが入っていないとエラーが出て起動しないので、なんでも良いのでモデルを入れる必要があります。自前でモデルを用意しているなら実行しなくても良いです。
5.はweb-uiの起動です。
それでは上から順に実行していきましょう。実行中は、セルの隣にある[ ]:という部分が[*]:となります。この部分が[1]:のように数字が書かれたら完了したという合図です。時間がかかるので気長に待ちましょう。
web-uiの起動を実行したら、ログが以下のようになるまで待ちましょう。
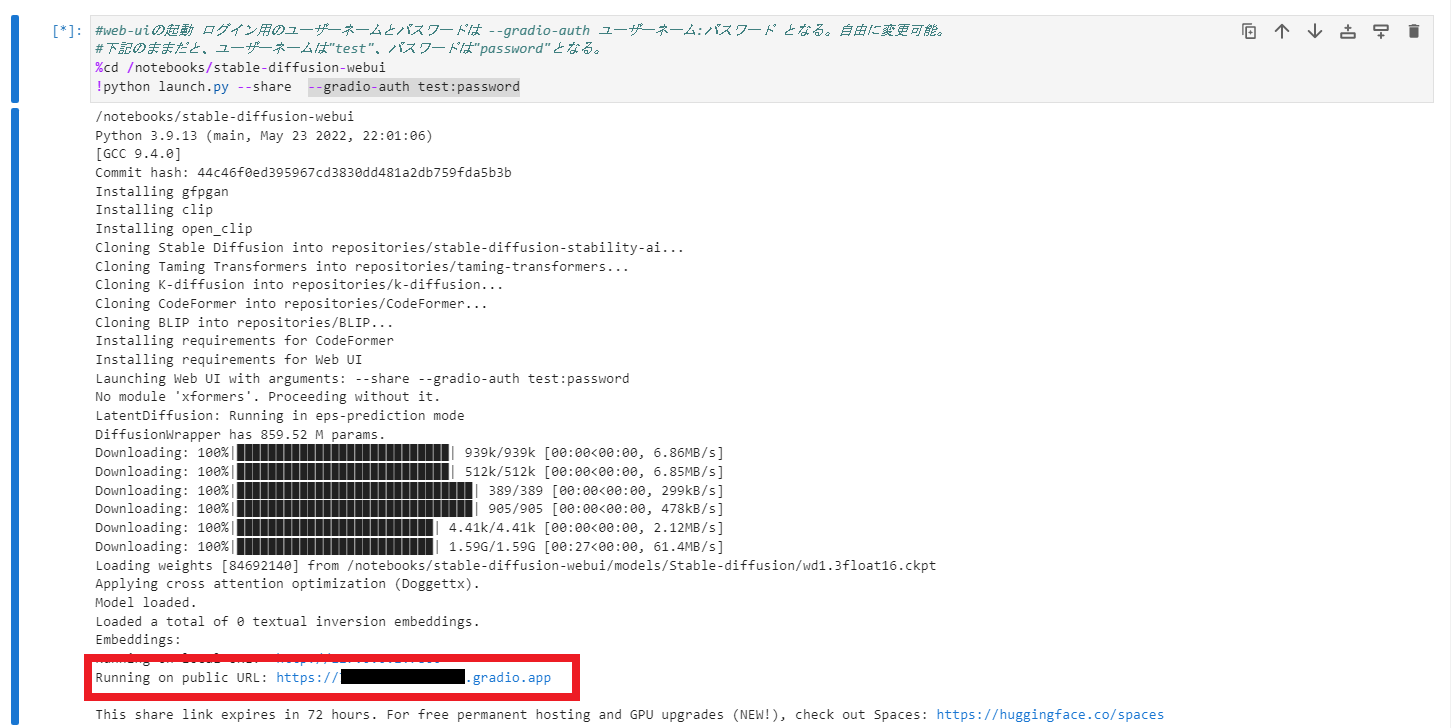
web-uiを起動するにはRunning on public URL : に書かれたURLをクリックしてください。ログが出てすぐクリックするとページが表示されない事があるので、数秒程待ってからクリックすると良いかもしれません。
注意点としては、このセルはURLが表示されても終了表記にはなりません。そもそもこのセルの実行を止めてしまうと、web-uiが動きません。
ユーザーネームとパスワードは–gradio-auth test:passwordで指定したものを入れましょう。
デフォルトの場合は、ユーザーネームがtestで、パスワードはpasswordになっています。
あとは普通に画像生成なりDreamBoothやHyperNetworkなどで学習していきましょう。
画像生成や学習方法などのやり方は、ローカルで実装しているweb-uiと変わりないので、各自で調べてください。
Extensions(拡張機能)のインストール
上記のweb-uiの起動だとDreamBoothなどのExtensionsをインストールする時に”AssertionError: extension access disabled because of command line flags“とエラーが出てしまいインストールできません。
Extensionsをインストールするには以下のコードを新しいセルにコピペして実行してください。※最新のpaperspace_web-ui_onlinegamernikki.ipynbをダウンロードした方は不要です。
#web-uiの起動(Extensionsインストール用) 必要なExtensionsをインストールしたらあとは必要なし。ログイン用のIDとパスワードは --gradio-auth ID:パスワード となる。自由に変更可能。
%cd /notebooks/stable-diffusion-webui
!python launch.py --share --gradio-auth test:password --enable-insecure-extension-access要は–enable-insecure-extension-accessを引数に追加するだけです。なので新しいセルを作らなくても、既存の起動用のセルに、上記の引数を追加するだけもいけるはずです。
以上でpaperspaceでweb-uiを起動する手順の説明を終わります。
スポンサーリンク
Googleドライブからファイルをダウンロードする方法
テキストファイルなど、容量の軽いデータであればpaperspaceへ直接アップロードしても問題ないのですが、ckptなど容量の多いデータをアップロードしようとすると時間がかかります。
なので大容量のデータはGoogleドライブからダウンロードしましょう。
ではやり方です。
まずは以下のコードを実行してください。
#googleドライブからダウンロードするのに必要なものをインストールする 初回のみ実行
!pip install gdown
!pip install --upgrade gdownこれでGoogleドライブからダウンロードするのに必要なgdownのインストールとアップグレードが始まります。
あとは、以下のコードを編集して実行すればGoogleドライブからダウンロードが始まります。
#googleドライブからファイルをダウンロードする "[ここにファイルIDを入力]"をファイルIDに置き換えてから実行
%cd /notebooks/stable-diffusion-webui/models/Stable-diffusion
!gdown "https://drive.google.com/uc?export=download&id=[ここにファイルIDを入力]"
%cd /notebooks/stable-diffusion-webui[ここにファイルIDを入力]と書かれているところをダウンロードしたいファイルのIDに書き換えます。
ファイルIDはドライブに保存しているファイルの共有用のリンクをコピーして適当なところに張り付けて確認します。/file/d/ と /view? の間の部分がIDになります。

また、注意点ですが、ダウンロードしたいファイルの共有設定は「リンクを知っている全員」に設定しておかなければなりません。
Hugging Faceへアップロードする方法
paperspaceから直接ダウンロードでも良いですが、寝る前にDreamBoothなどで出力されたモデルファイルをダウンロードしようとすると、時間がかかってしまい寝ることが出来なくなってしまいます。(PC付けっぱなしでも問題ないという方には関係ありませんが)
そんなときはHugging Faceへアップロードするコードを実行して、あとからHugging Faceからローカルにダウンロードするのをおすすめします。
コードは以下の通りです。
#huggingfaceのリポジトリにファイルをアップロードする。
#アップロードしたいファイルが/notebooks/testfolderにある"test.txt"である場合、以下の[アップロードするファイル名]を /notebooks/testfolder/test.txt に置き換える。
#huggingfaceに保存される名前をmain.txtにしたい場合、以下の[HFでのファイル名]を main.txt に置き換える。
#アップロード先が testuser/test である場合、以下の[ユーザー名/リポジトリ名]を testuser/test に置き換える。
#トークンは書き込み用(WRITE)のを使用すること。
from huggingface_hub import upload_file
upload_file(path_or_fileobj="[アップロードするファイル名]", path_in_repo="[HFでのファイル名]", repo_id="[ユーザー名/リポジトリ名]", token="[トークン]")上記のコメント部分に書いてある通りにコードを書き換えた場合は以下のようになります。
from huggingface_hub import upload_file
upload_file(path_or_fileobj="/notebooks/testfolder/test.txt", path_in_repo="main.txt", repo_id="testuser/test", token="書き込み用トークン")それでは、それぞれ書き換える部分の説明とHuggingFaceでのリポジトリの作成方法とトークンの発行方法を書いていきます。
・[アップロードするファイル名]ですが、これはpaperspace上で確認できます。アップロードしたいファイルの拡張子を含めたフォルダパスを入力するだけです。
・[HFでのファイル名]、こちらはHuggingFaceに保存されるときの名前になるので自由に設定してください。注意点としては拡張子も入力することです。
・[ユーザー名/リポジトリ名]は、HuggingFaceでのリポジトリのパスになります。
・[トークン]は書き込み用のトークンを入力します。
フォルダパスの確認方法
paperspaceでのモデルパスは、この記事で導入した場合は全てのデータが”/notebooks“という階層に作成されています。
なので、この記事通りにweb-uiを導入した場合、モデルの保存場所は “/notebooks/stable-diffusion-webui/models/Stable-diffusion” になっているので、[アップロードするファイル名]に入力するパスは “/notebooks/stable-diffusion-webui/models/Stable-diffusion/モデル名.ckpt(又は.safetensors)” となります。
また、以下のやり方でパスをコピーすることができます。(以下のやり方でのモデルデータの場所は “/notebooks/models/モデル.ckpt“ となっています)
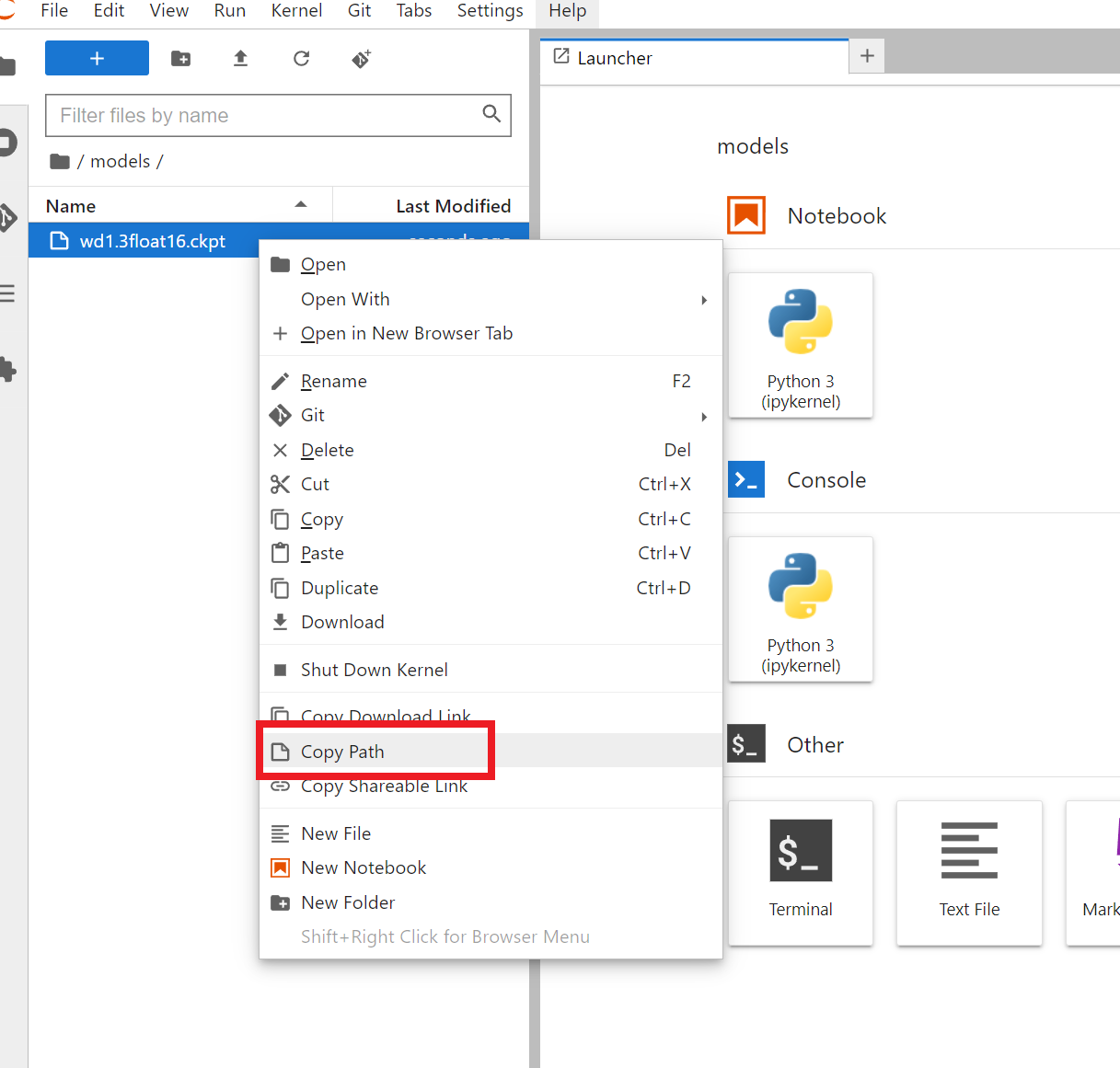
JupyterLab左側のファイル一覧から、アップロードしたいモデルデータが保存されてるフォルダを開いて、そのモデルデータを右クリックし、Copy Path をクリックします。
これで以下のようにコピーされます。
models/wd1.3float16.ckptこの頭に/notebooks と追加し以下のようにします。
/notebooks/models/wd1.3float16.ckptこれを[アップロードするファイル名]に張り付ければ完了です。
リポジトリの作成
まずはHuggingFaceのページへいきます。ここでは会員登録とログインは済んでいることを前提に進めていきます。
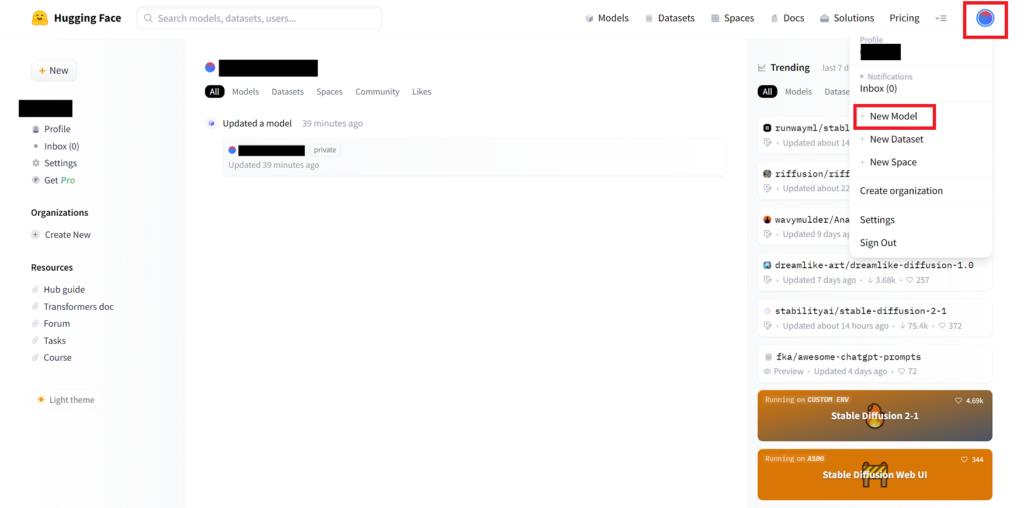
次に、右上のアカウントマークを押して、New Modelをクリックしてください。
リポジトリを作成する画面が表示されます。
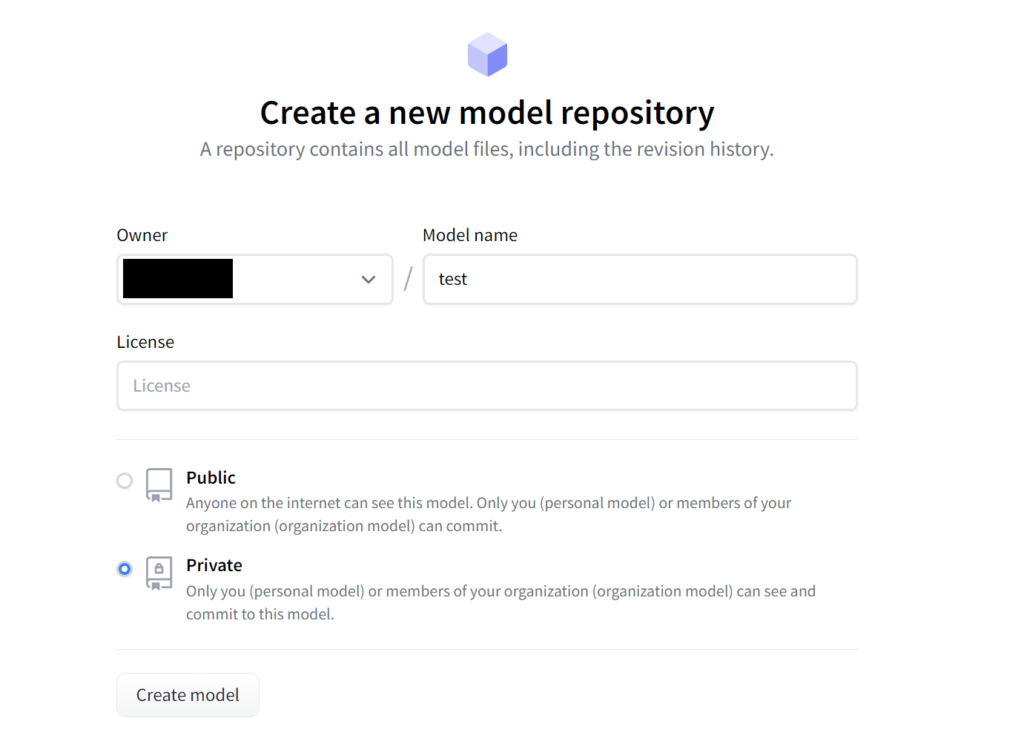
Model Nameは自由に決めてください。ライセンスもpaperspaceからのアップロードやバックアップ用であればどれでも良いと思います。
公開設定もどちらでも。自分の使っているモデルなどを他の人と共有したいのであればPublic、そうでないならPrivateで良いと思います。
入力が終わったらCreate modelをクリックしてください。
これで作成が完了し、以下の画面になると思います。
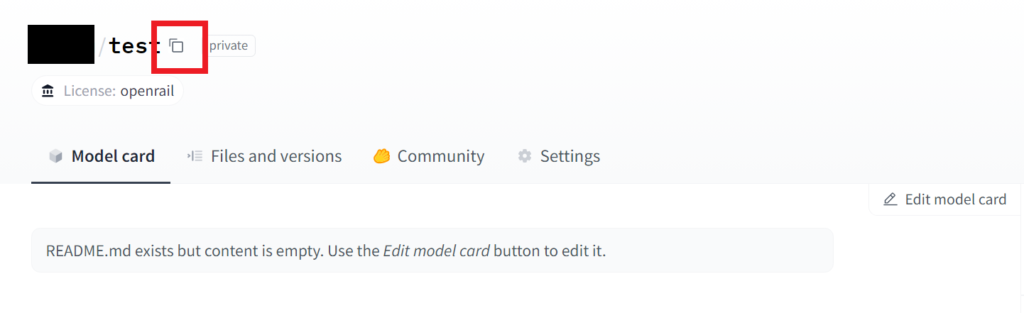
あとは赤枠で囲った部分をクリックし、リポジトリのパスをコピーして、paperspaceのコードの[ユーザー名/リポジトリ名]の部分を書き換えるだけです。
書き込み用トークンの発行
次にトークンの発行です。
右上のアカウントマークをクリックし、settingsをクリックします。
クリックすると以下のような画面が開くと思います。
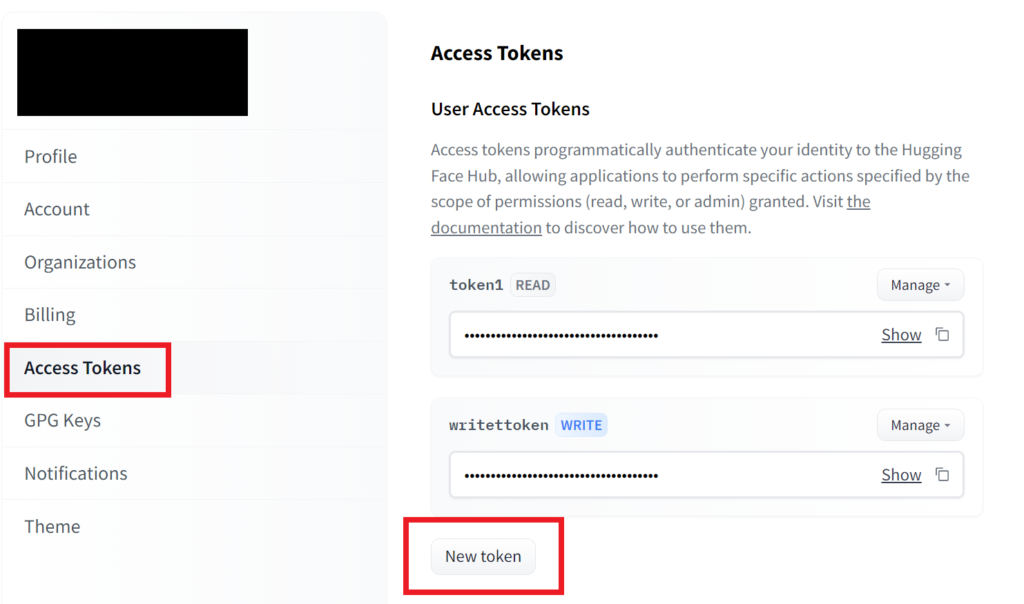
左の一覧からAccess Tokensをクリックし、New tokenをクリックして新しいトークンを発行できます。
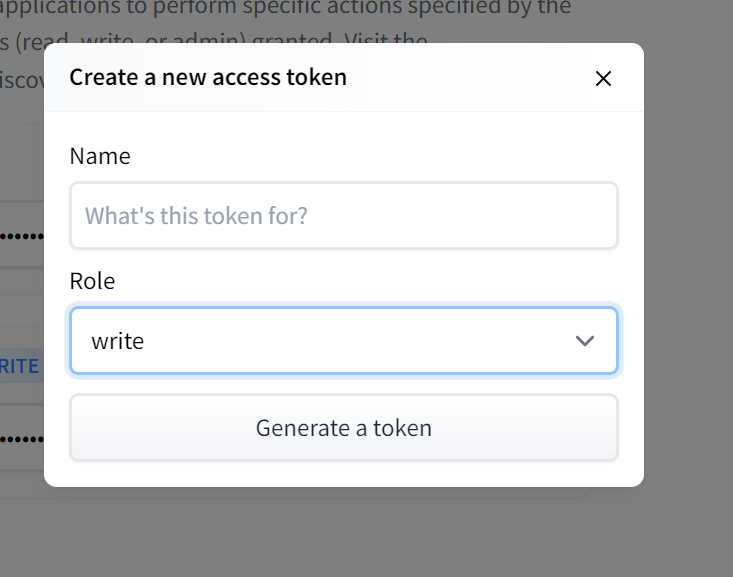
名前は自由に決めてください。Roleの部分はwriteを選択して、Generate a tokenをクリックです。
あとは発行されたトークンをコピーし、paperspaceの[トークン]の部分を書き換えるだけです。
自由にやりたいならやっぱりローカル
やっぱなんの制約もなくイラスト生成や学習をしたいならローカルです!
ローカルで学習する為のPCは以下の記事を参考に!
SDXL 1.0も動かせる!AIイラストの生成・学習におすすめのPCを紹介【Stable Diffusion】
また、おすすめのBTOメーカーについては以下の記事をどうぞ。
サイコムのゲーミングPCをおすすめする理由


コメント
記事参考になりました。現在AIイラストの生成用としては問題なく使用出来ているのですが、DreamBoothでの学習が上手くいきません。アドバイスいただけないでしょうか??
コメントありがとうございます。DBの学習が上手くいかないとのことですが、エラーが出て進まないのか、学習結果に満足できないのか、どちらでしょうか?
エラーの場合はエラーメッセージなどが出ていると思うので、それを見ないとなんとも言えません。学習結果については、使用する画像などでも左右するので、画像の数を増やしてみたり設定を変えてみたり、いろいろ試してみることをおすすめします。
学習がそもそもエラーがでて始まらない感じです。エラーメッセージは何処を確認すれば良いでしょうか?
JupyterLabの画面で、web-uiを起動したセルの下の方にログが出ているので、そこにエラーログも表示されているはずです。
また、開始自体が出来ないというのであれば、GPUのメモリ不足の可能性があるので、xformersの導入を検討してみてください。
xformersの導入は既にしてます
エラーの方は確認出来たんですが自分の知識ではよく分からなくて確認して貰いたいのですが、画像か直接コピペした方がいいですかね?
そうですね。エラー文が長くてコメントの文字数制限に引っ掛かるようならスクショなどを画像共有サイトなどにアップロードしてもらえると助かります。追加でDreamBoothタブの設定などもあると良いかもしれません。
また、私も詳しいわけではないので、期待に沿えないかもしれませんので、ご了承ください。
https://i.imgur.com/eiAar7a.jpg
https://i.imgur.com/8Y2cb8G.jpg
スマホから撮ったので見づらかったらすみません
DreamBoothタブの設定項目や、実際に行った手順などもお願いします。
こちらでも再現できるエラーか試してみます。
こちらでもいろいろ試してみて、たぶん同じ症状を発生できました。エラーメッセージに「CUDA out of memory.~~」という文は書かれていませんか?このメッセージが書かれていたらVRAMが足りていないということなので、GPUを変えてみることで解決できるかもしれません。CUDA out of memory.から続くエラーメッセージはnoriさんの貼ってくれた画像と同じなはずです。
このエラーは以下のGPUと設定で発生しました。
使用GPU:RTX4000、Use 8bit Adam : ON 、Mixed Precision : fp16 、 Memory Attention : xformers
また、GPUをRTX5000に変更して、Use 8bit Adam : ON 、Mixed Precision : fp16 、 Memory Attention : xformers の設定で学習を開始することが出来ました。
わざわざ検証までありがとうございます
DreamBoothタブの設定です
試しでwikiにあった四国めたんの画像でやってます。
https://i.imgur.com/BztwjNT.jpg
https://i.imgur.com/BuDyAWU.jpg
https://i.imgur.com/eFkAdFu.jpg
エラーメッセージに「CUDA out of memory.~~」といった文は無くrtx5000でもダメでした。
タブの設定の部分にミスがありますかね?
画像ありがとうございます。おそらくデータセットのパスの設定が間違っていると思われます。
この記事でipynbファイルをドラッグ&ドロップでコピーしたスペースは、paperspaceでは表記されていませんが「/notebooks/~~」という風に入力しなければならないので、Dataset Directoryに入力するパスの場合は「/notebooks/Folder/skkmtn」となります。他の部分も同様です。
ありがとうございます
GPUをRTX5000にし/notebooksを入れたら無事学習を行う事が出来ました。
記事通りにwebuiを一度だけ実行できましたが、数時間後に再度実行したらRunning on public URL:~の部分が表示されなくなってしまいました。(Running on local URL: ~は表示されます)
おそらく初歩的な設定の問題かと思いますが、位置からnotebookを作ったりなどをしても、解決できずにおります。アドバイスをいただけますと幸いです。
こちらの環境では再現出来なかったので確証はないですが、web-uiのバージョンを下げてみると良いかもしれません。
解決いたしました!ご確認いただいてありがとうございます!
理由はよくわからないのですが、#任意のバージョンをインストール、の部分に最新版ファイルのコミットハッシュを入れて起動した事か、一度wd以外の余計なckptファイルをディレクトリから削除した事でRunning on public URLが表示されるようになりました。
Hugging faceにモデルを入れる方法の記事を読んだのですがイマイチ分からないので・[アップロードするファイル名]ですが、これはpaperspace上で確認できます。アップロードしたいファイルの拡張子を含めたフォルダパスを入力するだけです。の所が理解できないので写真付きであげてもらえますか?
追記しました。
Extensions(拡張機能)でエラーが出て起動できなくなります
dynamic-promptsのインストールすると下のエラーが出てしまいます。
解決方法わかりますでしょうか?
Installing requirements for Web UI
Installing sd-dynamic-prompts requirements.txt
Launching Web UI with arguments: –share –gradio-auth test:0244 –enable-insecure-extension-access
/usr/local/lib/python3.9/dist-packages/torchvision/io/image.py:13: UserWarning: Failed to load image Python extension: /usr/local/lib/python3.9/dist-packages/torchvision/image.so: undefined symbol: _ZN2at4_ops19empty_memory_format4callEN3c108ArrayRefIlEENS2_8optionalINS2_10ScalarTypeEEENS5_INS2_6LayoutEEENS5_INS2_6DeviceEEENS5_IbEENS5_INS2_12MemoryFormatEEE
warn(f”Failed to load image Python extension: {e}”)
free(): invalid pointer
起動時の引数に –reinstall-torch を追加してみてください。
教えて頂きありがとうございます
起動時の引数に追加する方法は以下で良いでしょうか?
やってみたらエラーが出てdynamic-promptsの拡張機能が使えませんでした
#web-uiの起動(Extensionsインストール用) 必要なExtensionsをインストールしたらあとは必要なし。ログイン用のIDとパスワードは –gradio-auth ID:パスワード となる。自由に変更可能。
%cd /notebooks/stable-diffusion-webui
!python launch.py –share –gradio-auth test:password –enable-insecure-extension-access–reinstall-torch
すいません、セキュリティの都合上 “-” ←この記号を2つ連続で使用すると1つになってしまうようです。
起動時の引数に”-“を2つ付けて実行してみてください。
料金の請求で質問ですが、月末までにストレージ容量を減らせば請求される料金は減りますか?
現段階だと、プランの更新タイミングまでに容量を限度以下にしておけばストレージの超過分の請求はされません。
ただし、今後変更される可能性もあるのでその点には注意してください。
親切に教えて頂きありがとうございます
SDと別の話で恐縮ですが
paperspaceでReal-ESRGANを使いたいのですが
下のコードをpaperspaceに入れても動きません
どこを直せば良いか分かりますでしょうか?
https://colab.research.google.com/drive/1k2Zod6kSHEvraybHl50Lys0LerhyTMCo?usp=sharing
paperspaceで動かしたときのエラーメッセージが分からないので憶測で答えますが、colab側のノートブック「2.Upload Images」を無視して「3. Inference」に書かれている実行用コードの引数から”face_enhance”を除いて”-i upload”を”-i inputs”に変更して実行してみてください。
上記のコードで実行する場合、拡大したい画像を”/notebooks/Real-ESRGAN/inputs”に入れてください。出力される画像は”/notebooks/Real-ESRGAN/results”に保存されています。
私の環境ではこのやり方で動きました。
教えて頂きありがとうございます!
フォルダを指定して削除はどうすれば良いでしょうか?
フォルダの中身を空にすれば削除できますが
一つ一つ削除は大変で・・・
マシンを起動していない状態なら中身のあるフォルダでも削除できます。
すぐに教えて頂きありがとうございます!
Running on public URL : が表示されなくなり、1111にログインできなくなりました
Running on local URL: http://127.0.0.1:7860 こちらから先が表示されなくなりました
原因わかりますでしょうか?
エラーメッセージは以下が出ています
ERROR: pip’s dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
torchaudio 0.12.0+cu116 requires torch==1.12.0, but you have torch 1.13.1+cu117 which is incompatible.
Successfully installed torch-1.13.1+cu117 torchvision-0.14.1+cu117
WARNING: Running pip as the ‘root’ user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
エラーとしては 「”torchaudio 0.12.0+cu116 requires torch==1.12.0″が必要だけど、あなたの環境には”torch 1.13.1+cu117″が入っていてこのバージョンに互換性はないよ。」というエラーのようです。
起動時の引数に”reinstall-torch”を指定しているならそれを外せばエラーは出なくなると思いますが、私の環境では上記に記載のエラーが表示されていてもpublic URLが表示されるので、今回のエラーは関係ないかと思われます。
また、今朝方にgradio自体が落ちていたとのことなので、それが原因かもしれません。現在は復旧しているようなので設定などは変えずにもう1度起動してみてください。
教えて頂いてありがとうございます!
大量の画像をpaperspaceからパソコンにダウンロードする時どうやってますでしょうか?
100枚以上をダウンロードする場合です
複数の画像を選択してダウンロードする方法は10枚くらいしか保存できないです
下のリンク先のExport Generationsでダウンロード出来ると聞いたのですが、上手く行かず
https://github.com/Engineer-of-Stuff/stable-diffusion-paperspace/blob/master/StableDiffusionUI_Voldemort_paperspace.ipynb
ブログの運営者様はどうされてますでしょうか?
zipコマンドで.zipにしてダウンロードしています。
notebooksの中のoutputフォルダを.zipにし、その.zipのフォルダ名を”gazou”にしたい場合は以下のコマンドで出来ます。
“!zip -r gazou.zip /notebooks/output”
また.zipの保存場所は最後にcdコマンドで開いた場所になります。
ありがとうございます!お陰さまでダウンロードできました。
しかし、ダウンロードの速度が遅く
200MBの画像をダウンロードするのに1時間ほどかかりました。
ダウンロード速度を早くする方法ありませんでしょうか?
ダウンロードが遅い原因は主に2つです。
1つ目は使っている回線速度に原因がある場合
2つ目はサービス側のサーバー負担が大きい場合です。
前者の場合は回線速度を調べ、遅いようなら回線業者の変更やLANケーブルの変更で対応可能ですが、後者の場合はpaperspaceのサーバーが原因なのでどうしようもありません。
xformersを導入したいのですが、提供してくださってるノートのどこに何を書き換えればいいのかわかりません。契約はproです。ご教示いただけないでしょうか。
!pip install xformers で導入することができます。
Hires.fixの設定内のUpscale byが表示されないですが、原因わかりますでしょうか?
画像サイズを倍にする設定です
最新版にする(オプション)を使ってるのでバージョンは最新だと思うんですが・・・
こちらでも最新版を入れて試してみましたが、問題なく表示されますね。
拡張機能の影響もあるかもしれないので、新しいプロジェクトを作るなどして設定も拡張機能もなにもいじっていない状態で試してみてください。
こちらの記事を参考に、エラーでつまっていた拡張機能のインストールができました。
素晴らしい記事をありがとうございます!
指定したフォルダ内の画像やファイルをすべて消すコードありますでしょうか?
フォルダ内の画像を削除したい場合は以下のコードのように、拡張子含めた該当ファイルまでのパスを指定
import os
os.remove(‘フォルダパス/画像.png’)
フォルダごと削除する場合は以下のようにすれば消せます。
import shutil
shutil.rmtree(‘フォルダパス’)
また、フォルダは残し、中身だけ削除したい場合は以下を
import shutil
fileName=’フォルダパス’
shutil.rmtree(fileName)
os.mkdir(fileName)
厳密に言うと、フォルダを残しているのではなく、一旦フォルダごと削除し、同名のフォルダを同じ階層に作成しているだけですが、特に問題はないと思います。
教えて頂きありがとうございます!
gradioを過去バージョンに戻す方法ありますでしょうか?
下のwikiにやり方ありますが、エラー出てしまいます。
https://wikiwiki.jp/sd_toshiaki/Paperspace%E7%89%88%E5%B0%8E%E5%85%A5#sbfc652d
stable-diffusion-webuiフォルダにあるrequirements.txtの中に”gradio==〇〇”と書かれた行があると思うので、〇〇の部分にバージョン記入でどうでしょうか?
私自身あまりgradioのバージョンを変更したことがないので確証はありませんが、試してみてください。
回答ありがとうございます!
教えて頂いた通りやってみましたが
バージョンを変更できないようです
gradio==3.9に変更してもCommit hashが変わらないです
Commit hash: 4c1ad743e3baf1246db0711aa0107debf036a12bと表示されます
最新版にする(オプション)を実行してもバージョンが最新にならないです
Commit hash:で表示される数値が変わらないです
運営者様は最新版になってますか?
下を実行してます
#最新版にする(オプション) web-uiを最新版にしたいときに実行
%cd /notebooks/stable-diffusion-webui
!git checkout master
!git pull
git pullした時にエラーなど出ていませんか?
また、新しいプロジェクトを作って、拡張機能や設定をなにも弄っていないweb-uiで試してみてください。追加した拡張機能などが原因の場合があります。
paperspaceでgenerate foreverすると止まりやすく
再起動しないと動かなくなります
運営者様は止まらなくさせる対策されてますでしょうか?
私のpaperspaceの使い方は、主にDBやLoRAなどの学習で、生成自体はローカルでやる事が多いので直るかどうかは分かりませんが、起動時の引数に
--gradio-queueを追加すると改善されるかもしれません。Pythonのバ-ジョンを3.10にしたいです
コード分かりますでしょうか?
すいません、こちらでもいくつか試してみたのですが、導入することができませんでした。
参考になりそうなサイトを載せておきますので、参考にしてみてください。
https://qiita.com/S-Shinzi/items/df9cf043164ac86ff5d8
paperspaceの「Restart Kernel」をクリックするとデータ全て消えるのでしょうか?
「Restart Kernel」をクリックしたらデータ消えたみたいです。
こちらでも試してみましたがデータが消えるということはありませんでした。
すみません、
huggingfaceの自分のprivateに載せたモデルをPaperspaceの一時領域にダウンロードして使う場合って、どういうコードにすればいいんでしょうか?
よろしかったらご教示ください。
すいません、私もそのやり方分からないので、ダウンロードする時だけパブリック設定にしてやっています。
ありがとうございます。
https://dvgr.hatenablog.com/entry/2023/02/10/021637#f-67e27bc1
参考にやってたんですけど、コメントアウト付けたらエラー起きたので、消したらピンク色になったけど上手く行きました。
情報ありがとうございます!
エラーが出て拡張機能がインストール出来ず、
エラーメッセージを検索してこちらのサイトにたどり着きました。
お陰様で、無事に拡張機能を入れることができました。
本当にありがとうございました!
paperspaceで画像サイズが2000PXを超える画像を作れますでしょうか?
私は1500PXを超える画像作るとエラーが出て作れないです
エラー内容が分からないのでなんとも言えませんが、画像サイズを大きくした時に出るエラーであれば大抵の場合はVRAM不足によるものなので、GPUを現在使っているのより性能の高い方に変えてみてください。
下のPaperspaceでフレーム補間AIを使う方法が動かないです。
原因わかりますでしょうか?
https://nintech.jp/2023/04/21/%E3%80%90paperspace-gradient%E3%80%91film%E3%81%A7%E5%8B%95%E7%94%BB%E3%81%AE%E8%A3%9C%E9%96%93%E3%82%92%E3%81%97%E3%81%A6%E3%81%BF%E3%81%9F/
すいません、FILMは触った事ないので分からないです。