

26/3/28 : 学習時に発生するエラーについて、対処法を記載しました。
今回はRTX5070やRTX5080、5090などBlackwell環境で音声生成AIの「Style-Bert-VITS2」の導入から使用、学習したモデルを外部ツールのAivisSpeechで動かすまでを書いていきます。
リポジトリは以下です。
バージョンは2.7.0を導入します。また、リポジトリに書いてある通りに導入しようとしてもエラーになり導入出来なかったり学習途中でエラーになるので、その対処法も書いていきます。
また、今回は(Blackwell環境を想定している為、CUDAのバージョンは12.8を使用します。RTX40xxシリーズでも問題なく動作すると思いますが、もし動作しなければ別なバージョンのCUDAを使用してみてください。
Style-Bert-VITS2の導入
それでは導入していきます。まずはStyle-Bert-VITS2のリポジトリへアクセスします。
zipフォルダのダウンロード
下へスクロールするとインストールと書かれた項目に.zipフォルダをダウンロードするリンクがあるので、そちらをクリックします。

ダウンロードした.zipフォルダをパスに日本語や空白が含まれていない任意の場所で展開します。
エディター起動に必要な修正箇所
展開したら中に入っているsbv2フォルダの中にある「Install-Style-Bert-VITS2.bat」右クリックし編集からメモ帳などで開き中身を編集していきます。
メモ帳を開いたら、以下の部分を編集していきます。
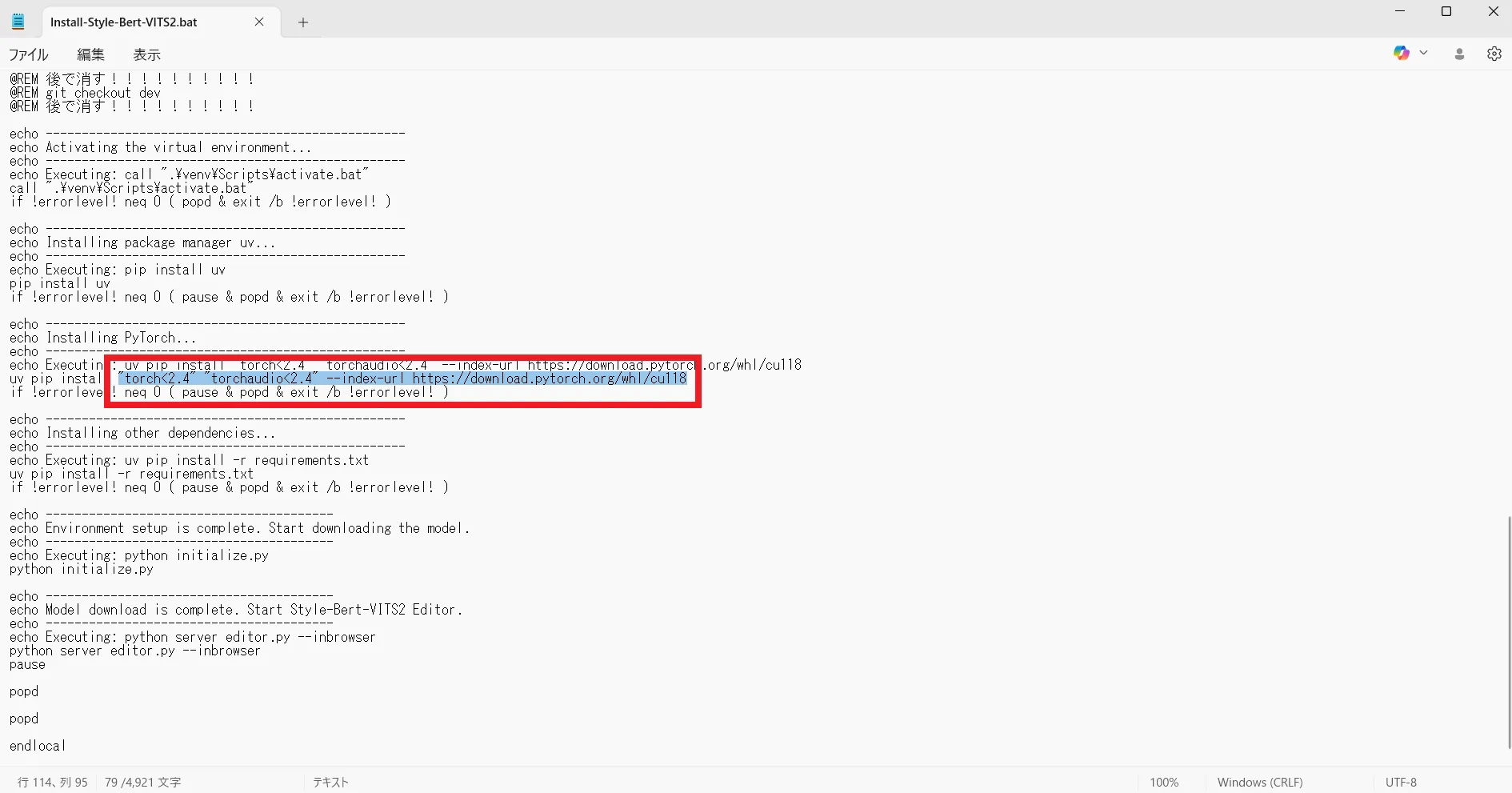
114行目の「uv pip install “torch<2.4” “torchaudio<2.4” –index-url https://download.pytorch.org/whl/cu118」という部分です。
uv pip install "torch<2.4" "torchaudio<2.4" --index-url https://download.pytorch.org/whl/cu118この行を「uv pip install “torch==2.7.1” “torchaudio==2.7.1” –index-url https://download.pytorch.org/whl/cu128」へ変更します。
uv pip install "torch==2.7.1" "torchaudio==2.7.1" --index-url https://download.pytorch.org/whl/cu128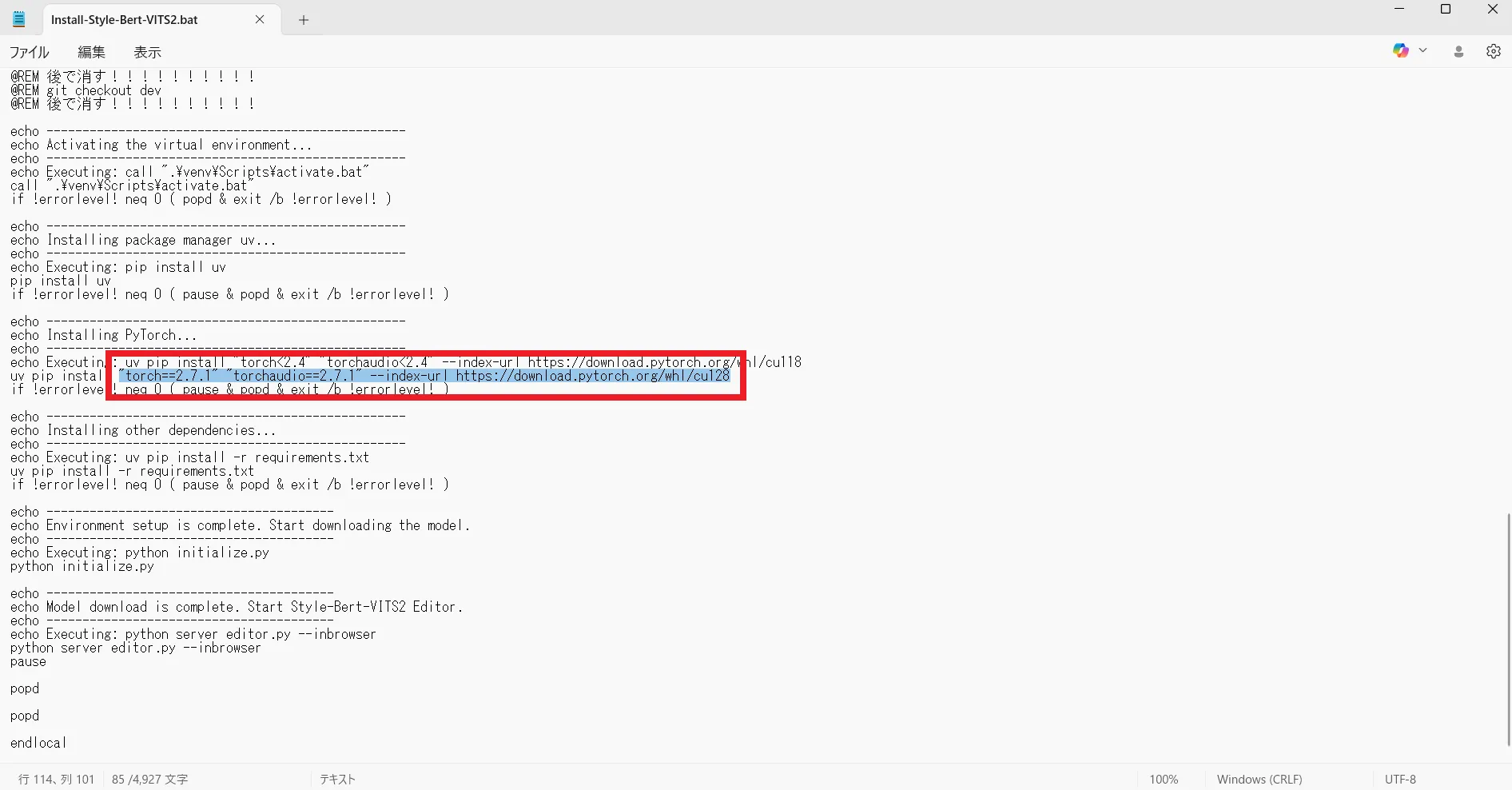
その上の行の「echo Executing: …」と書かれている部分は、画面に文字を表示するためのコマンドなので変更しなくて大丈夫です。
ここまで出来たらメモ帳は閉じて「Install-Style-Bert-VITS2.bat」を起動します。
スポンサーリンク
起動するとコマンドプロンプトが開き必要なものが自動でダウンロードされ始めます。
ですが、途中でエラーが発生し終了してしまうので、修正していきます。
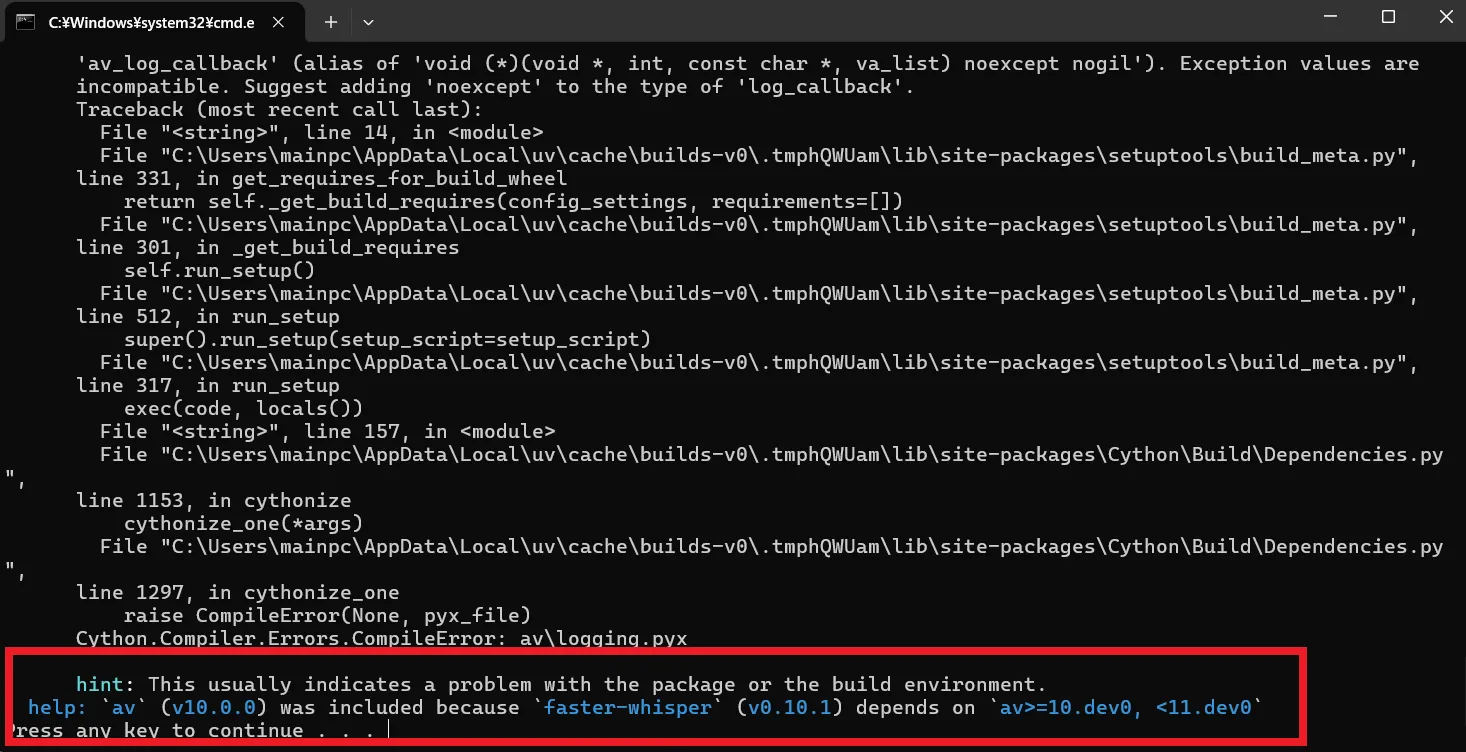
この画面から続行することは出来ないので、書いてある通りに適当なキーを押すか右上のバツからコマンドプロンプトを終了させてください。
次にsbv2フォルダに戻ります。
「Style-Bert-VITS2」というフォルダが追加されているので、こちらを開きます。
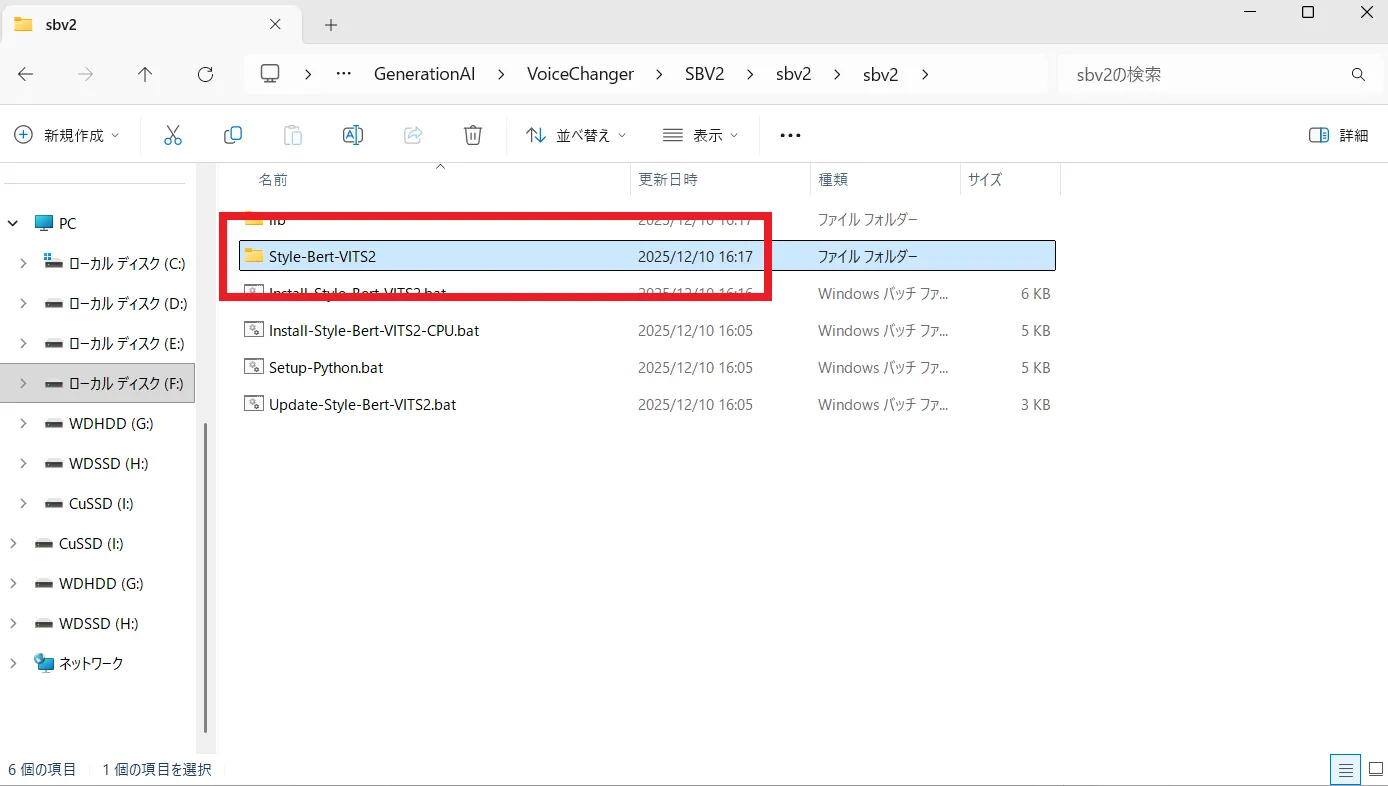
中に入っている「requirements.txt」を編集していきます。
デフォルトでは以下のようになっているとい思います。
accelerate
cmudict
cn2an
faster-whisper==0.10.1
g2p_en
GPUtil
gradio>=4.32
jieba
librosa==0.9.2
loguru
nltk<=3.8.1
num2words
numpy<2
onnx
onnxconverter-common
onnxruntime
onnxruntime-directml; sys_platform == 'win32'
onnxruntime-gpu; sys_platform != 'darwin'
onnxsim-prebuilt
protobuf==4.25
psutil
punctuators
pyannote.audio>=3.1.0
pyloudnorm
pyopenjtalk-dict
pypinyin
pyworld-prebuilt
stable_ts
tensorboard
torch<2.4
torchaudio<2.4
transformers
umap-learnこちらをすべて消して、以下をコピーして貼り付けてください。 インストールされるライブラリの最新バージョンが対応していないため、以下のものではエラーが発生します。
26/4/4 追記の方をお使いください。
accelerate
faster-whisper
g2p_en
GPUtil
gradio==5.34.0
jieba
librosa==0.9.2
loguru
nltk<=3.8.1
num2words
numpy<2
onnx
onnxconverter-common
onnxruntime
onnxruntime-directml; sys_platform == 'win32'
onnxruntime-gpu; sys_platform != 'darwin'
onnxsim-prebuilt
protobuf==4.25
psutil
punctuators
pyannote.audio>=3.1.0
pyloudnorm
pyopenjtalk-dict
pypinyin
pyworld-prebuilt
stable_ts
tensorboard
transformers
umap-learn
soxr26/4/4 追記
上記のリストでインストールされるバージョンにより、エラーが出てしまうので以下のリストを張り付けてください。正常に動作している環境からpip freezeで出力したものなので動くはずです。
accelerate==1.12.0
faster-whisper==1.2.1
g2p-en==2.1.0
GPUtil==1.4.0
gradio==5.34.0
jieba==0.42.1
librosa==0.9.2
loguru==0.7.3
num2words==0.5.14
numpy==1.26.4
onnx==1.17.0
onnxconverter-common==1.16.0
onnxruntime==1.23.2
onnxruntime-directml==1.23.0
onnxruntime-gpu==1.23.2
onnxsim-prebuilt==0.4.36.post1
protobuf==4.25.0
psutil==7.1.3
punctuators==0.0.7
pyannote.audio==3.4.0
pyloudnorm==0.1.1
pyopenjtalk-dict
pypinyin==0.55.0
pyworld-prebuilt==0.3.5.post2
setuptools==80.9.0
soxr==1.0.0
stable-ts==2.19.1
tensorboard==2.20.0
transformers==4.57.3
umap-learn==0.5.9.post2貼り付けたらもう一度「Install-Style-Bert-VITS2.bat」を右クリックし編集を押してメモ帳を開きます。
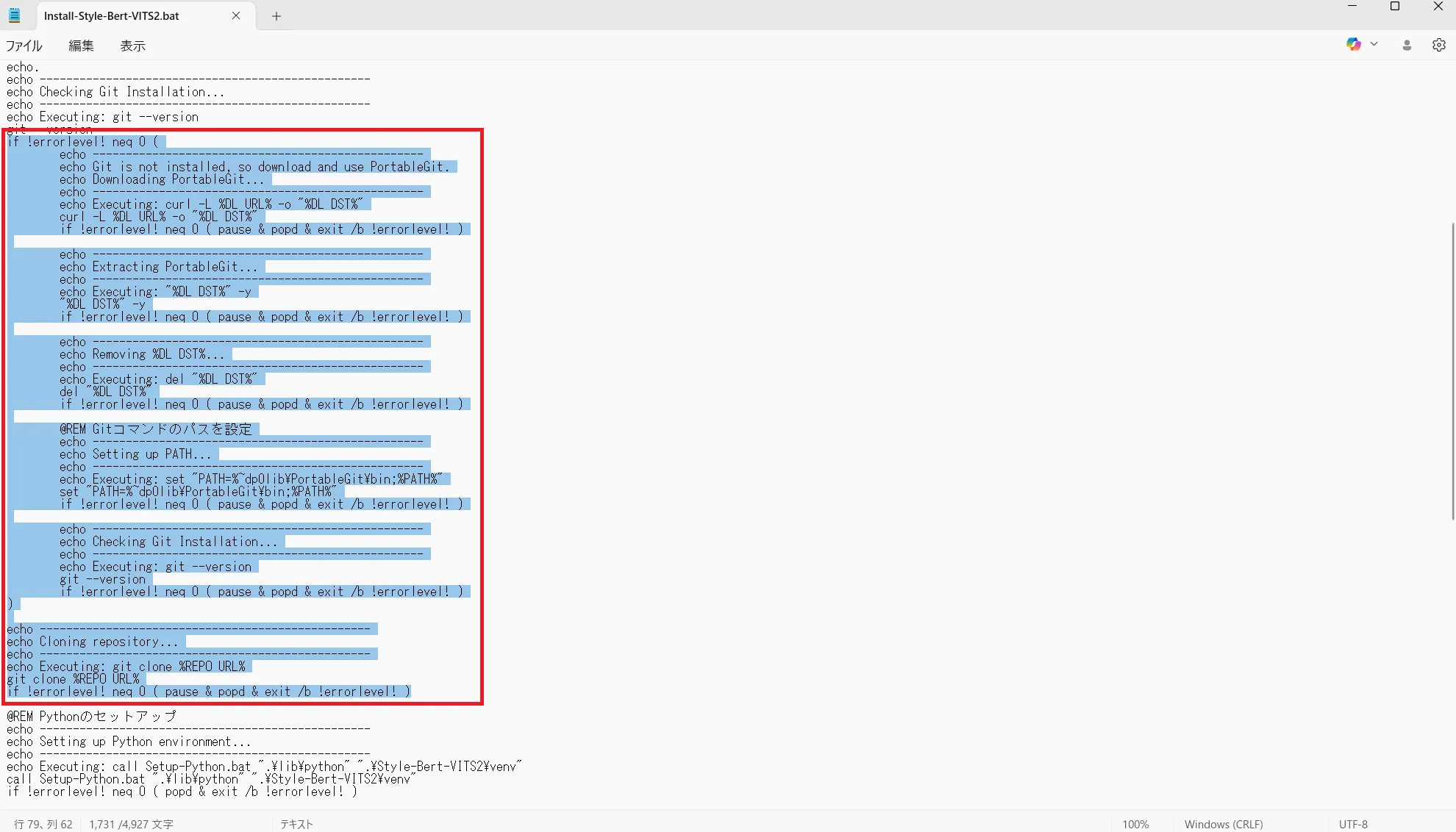
35~79行目の赤で囲った部分を削除します。
削除したら「Install-Style-Bert-VITS2.bat」を起動します。
しばらくすると以下のようなエディター画面が起動します。
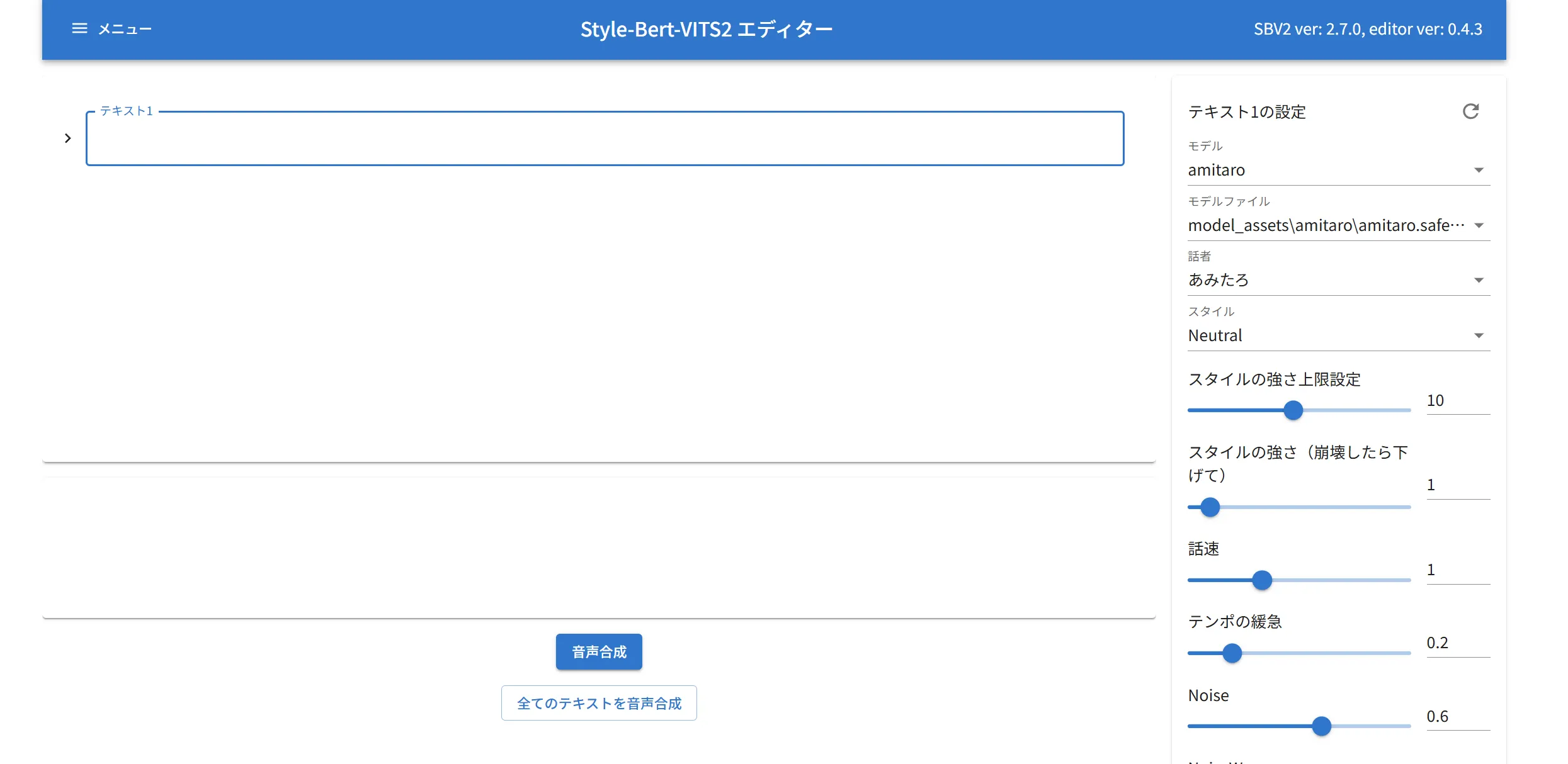
これで喋らすことが出来るようになります。
エディターのみの使用であればこれで終わりですが、学習も行う場合は他にも修正箇所があります。
次からはそちらを解説していきます。
スポンサーリンク
学習に必要な修正箇所
まず「Style-Bert-VITS2」フォルダを開き、中に入っている「style_gen.py」をメモ帳などで開きます。
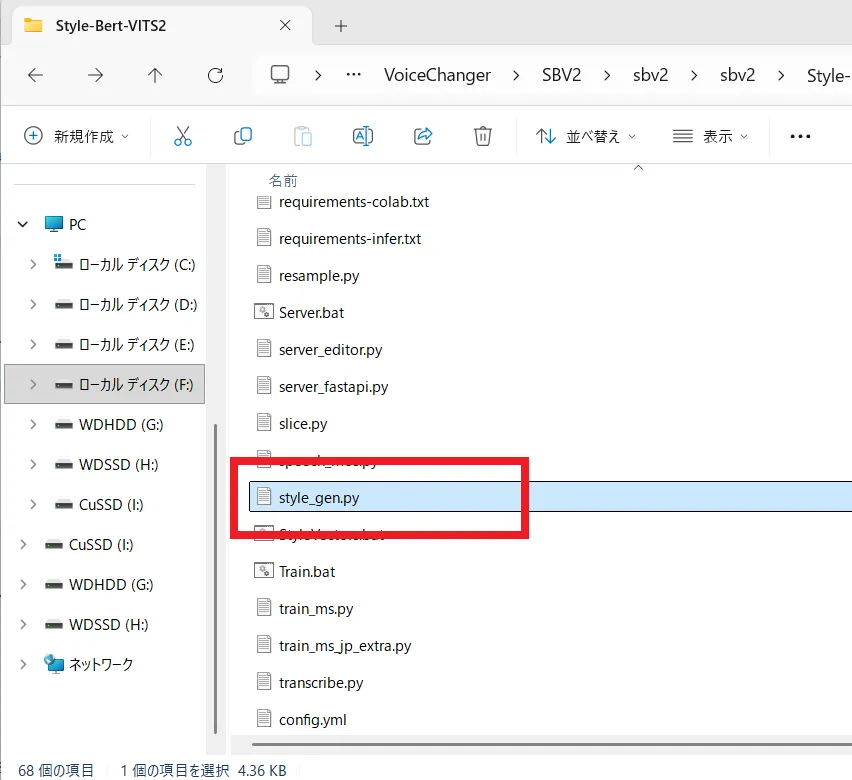
開いたら以下の赤枠で囲った箇所をコメントアウトします。
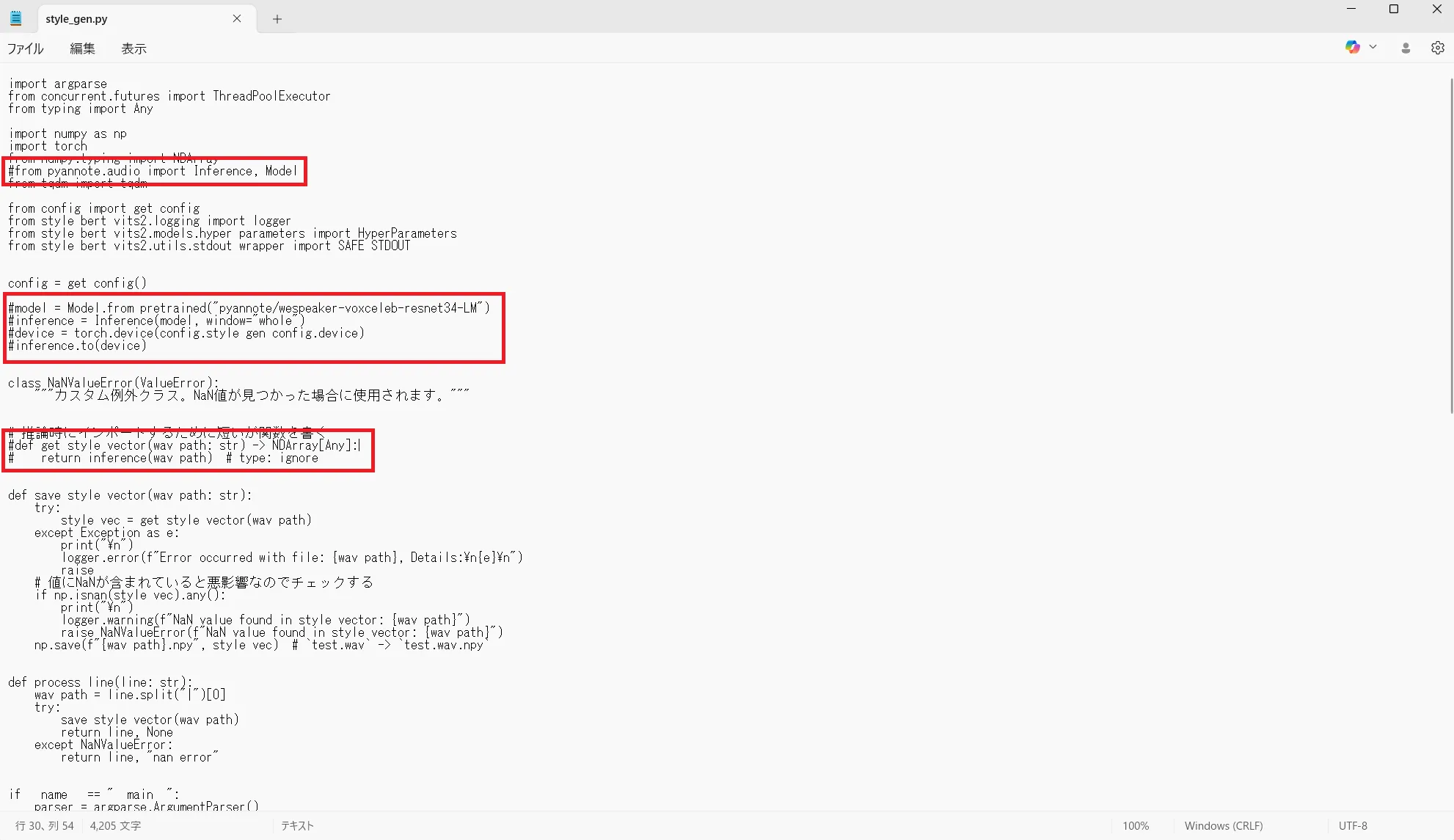
コメントアウトするには、行の先頭に「#」を付けます。
8行目
#from pyannote.audio import Inference, Model
19~22行目
#model = Model.from_pretrained("pyannote/wespeaker-voxceleb-resnet34-LM")
#inference = Inference(model, window="whole")
#device = torch.device(config.style_gen_config.device)
#inference.to(device)
30~31行目
#def get_style_vector(wav_path: str) -> NDArray[Any]
#return inference(wav_path) # type: ignore該当箇所をコメントアウトしたら33行目あたりに以下のコードを追加します。
def get_style_vector(wav_path: str) -> NDArray[Any]:
style_vec = torch.zeros(256, dtype=torch.float32)
return style_vec.numpy()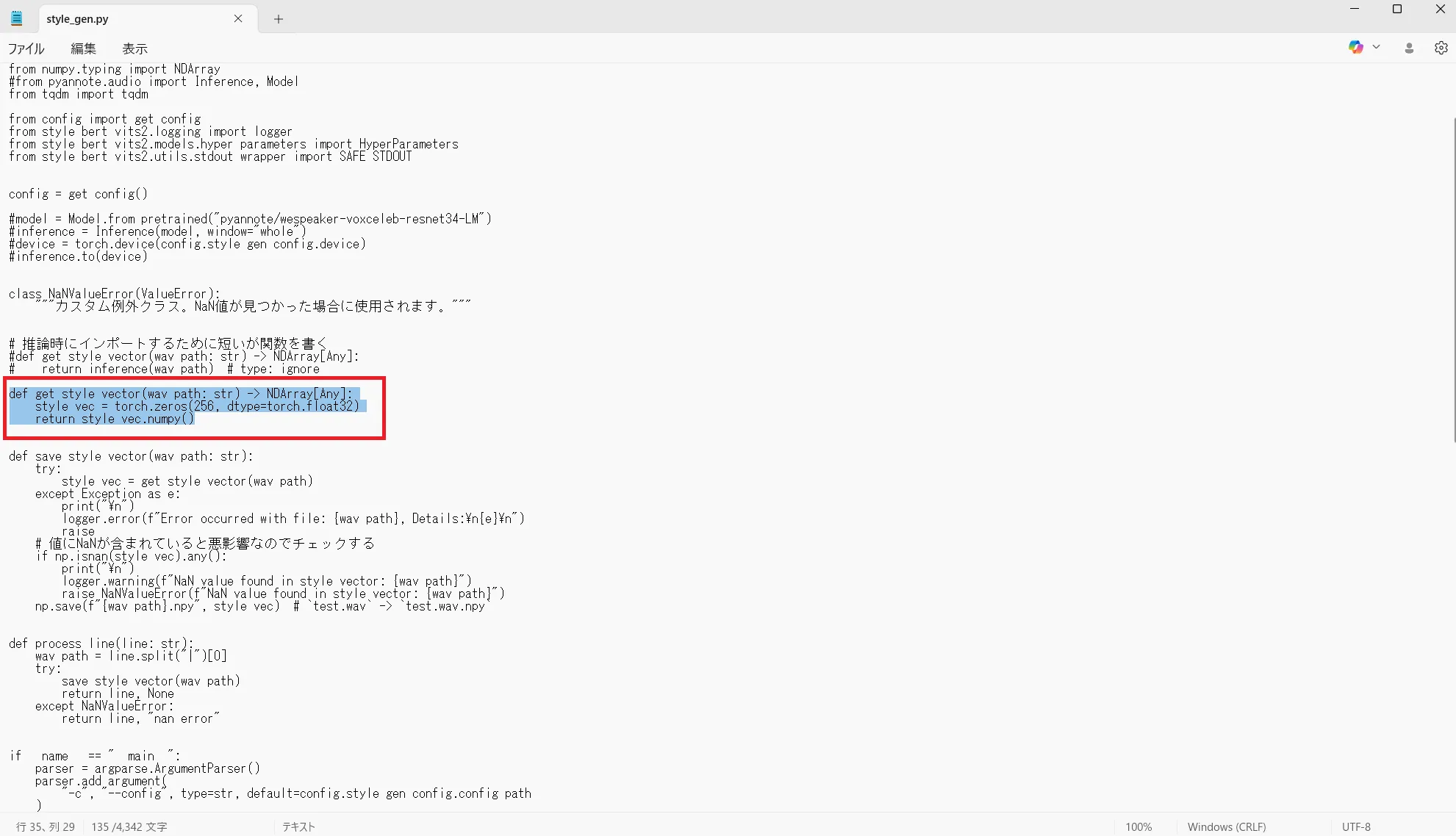
これで学習時に必要な変更箇所の修正は完了です。
スポンサーリンク
Style-Bert-VITS2での音声学習
それでは、ここからはStyle-Bert-VITS2で声の学習を行っていきます。
学習データは各自で用意してください。
音声データはセリフごとに分かれているファイルでも、長時間の1つのファイルでも問題ありません。
それでは、手順を解説していきます。
まず、「Style-Bert-VITS2」フォルダにある「input」フォルダを開きます。
開いたら、このフォルダの中に音声ファイルを入れていきます。
私は1時間強の音声ファイルを1つ入れました。
音声ファイルを入れたら、「Style-Bert-VITS2」フォルダへ戻り、「App.bat」ファイルを起動します。
しばらく待てばWebUIが起動します。
ちなみに、喋らすのは最初に起動したエディターだけでなく、今回起動した画面の「音声合成」タブからも行えます。
ですが、エディターの方が使いやすいかもと書かれているので、この記事ではエディター画面で喋らせます。
それでは、実際に学習を行っていきましょう。
まずは「データセット作成」タブを開きます。
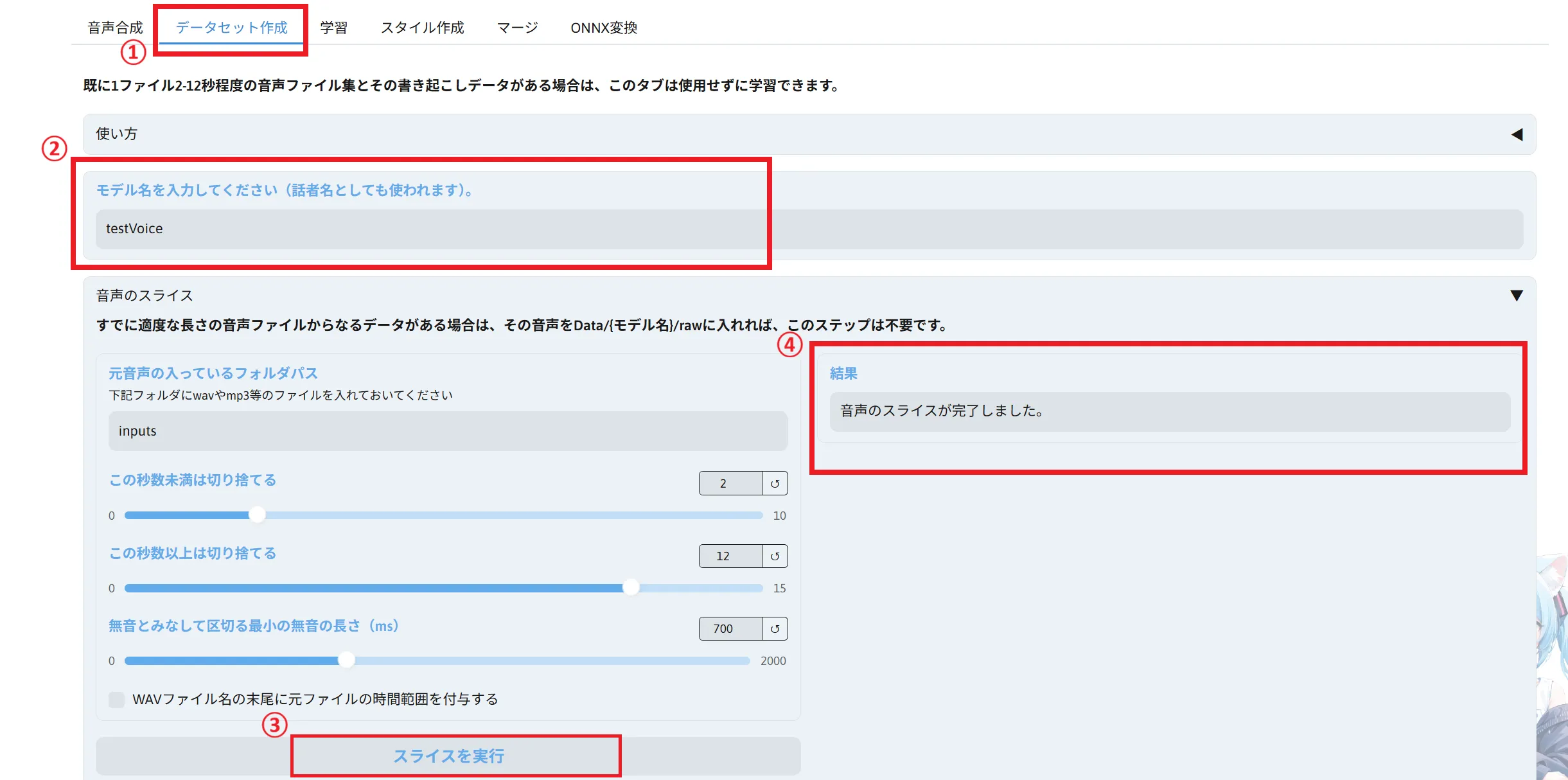
次にモデル名を入力します。キャラ名などが決まっている場合は、その名前を入力すると良いでしょう。
モデル名を決めたら「スライスを実行」をクリックし「音声のスライスが完了しました」と表示されるまで待ちます。
スライスの設定はデフォルトでも問題ないと思いますが、場合によっては変更すると良いでしょう。
スライスが完了したら下へスクロールし文字起こしを行います。
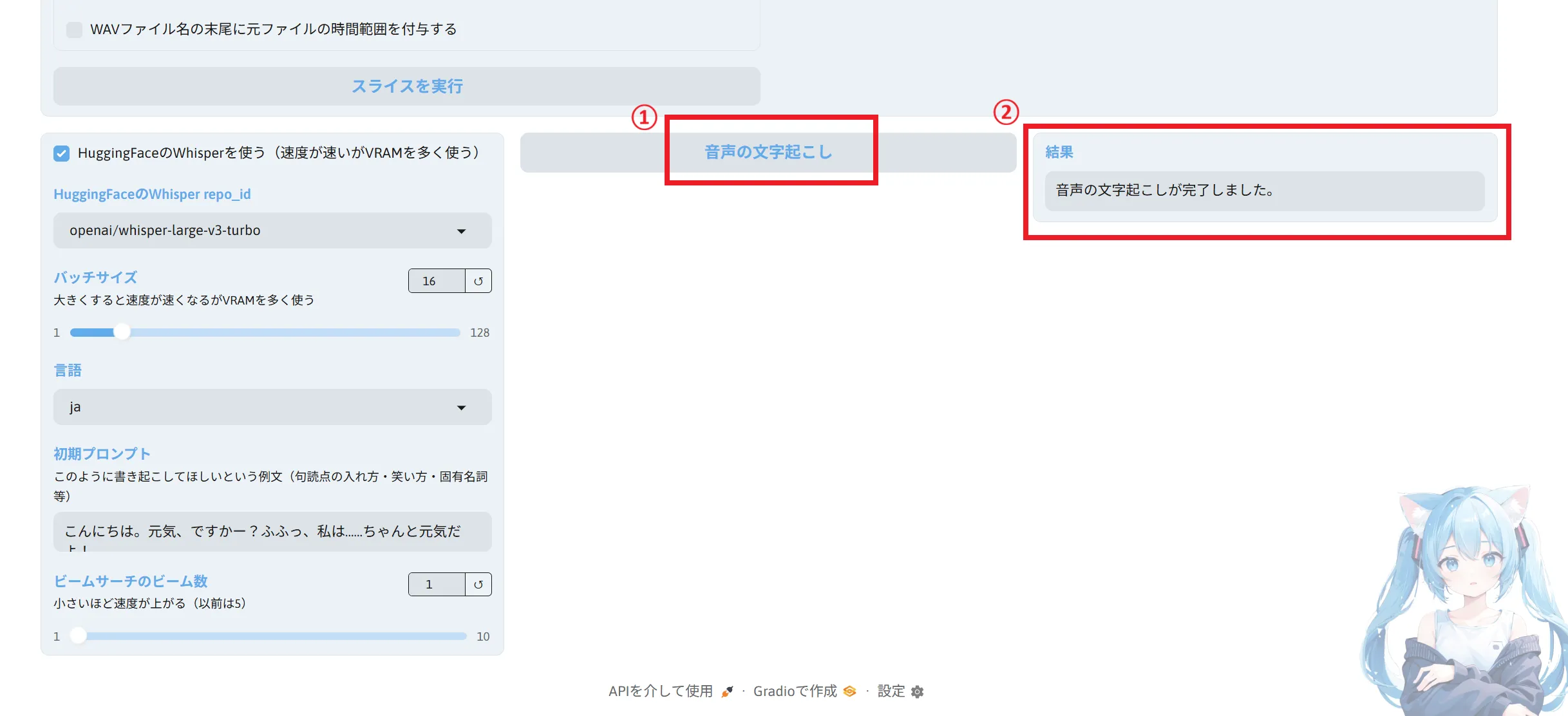
設定はデフォルトでも問題ありません。VRAMの使用率は多くなりますが、HuggingFaceのWhisperを使うにチェックを入れると速度が上がるようです。
設定が済んだら「音声の文字起こし」をクリックし、先ほどと同じように完了と出るまで待ちます。
処理されたデータは「Style-Bert-VITS2」フォルダの「Data」フォルダに入っています。
スライスされた音声の文字起こしの結果が入っています。もし文字起こしの結果が間違っていても学習は可能なので今回は修正せずに行います。
それでは、「学習」タブを開きます。
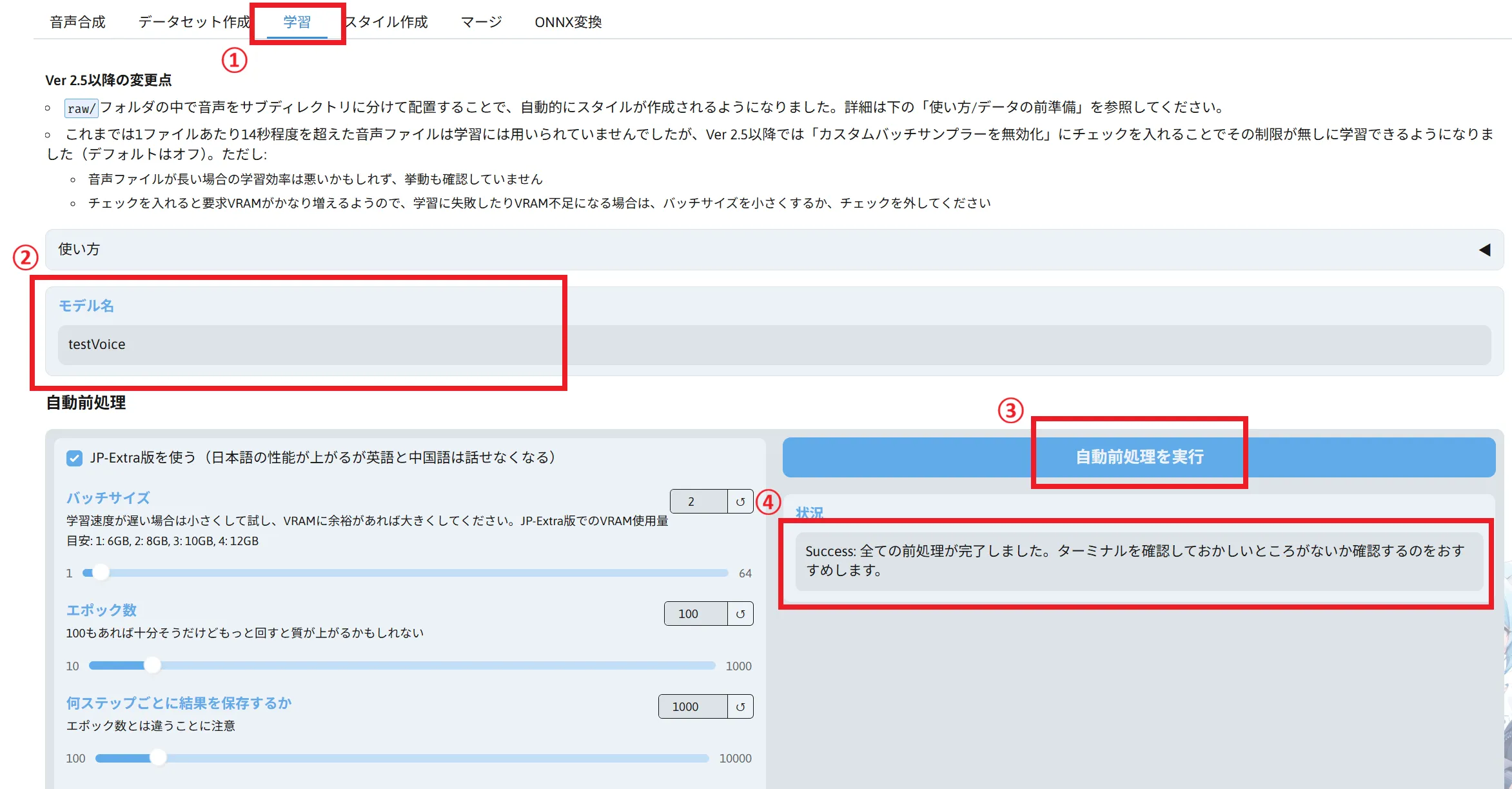
モデル名には先ほどの「データセット作成」タブで入力したものを入れてください。
こちらの設定もデフォルトで問題ありまので、そのまま「自動前処理を実行」をクリックして完了メッセージが表示されるまで待ちます。
そのまま下へスクロールして「学習を開始する」をクリックして完了まで待ちます。
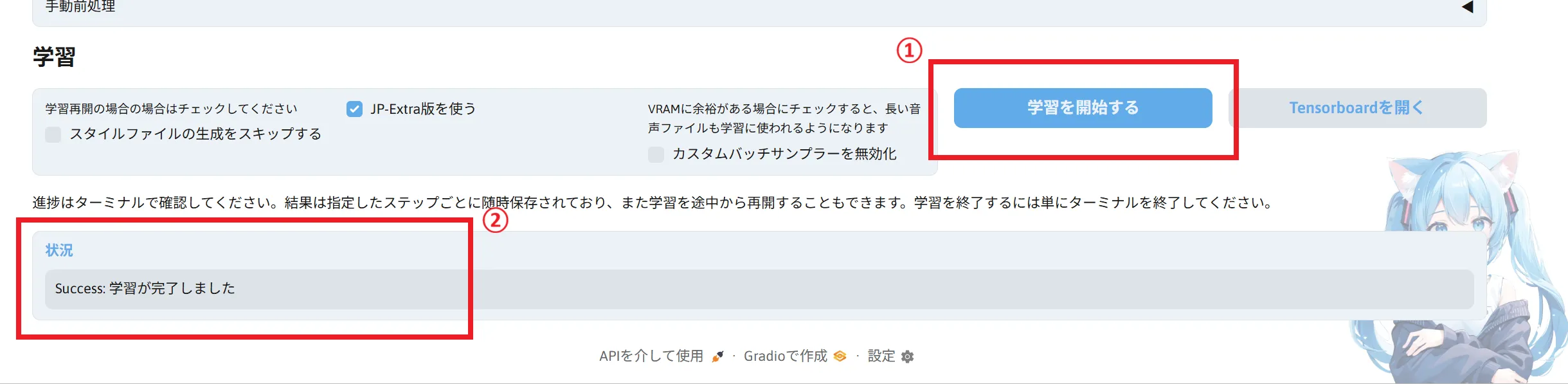
学習したモデルデータは「Style-Bert-VITS2」フォルダの「model_assets」フォルダに入っています。
これで学習は完了です。次に学習したモデルで音声合成を行っていきます。
スポンサーリンク
学習した声を喋らせる
「Editor.bat」を起動してエディターを起動します。
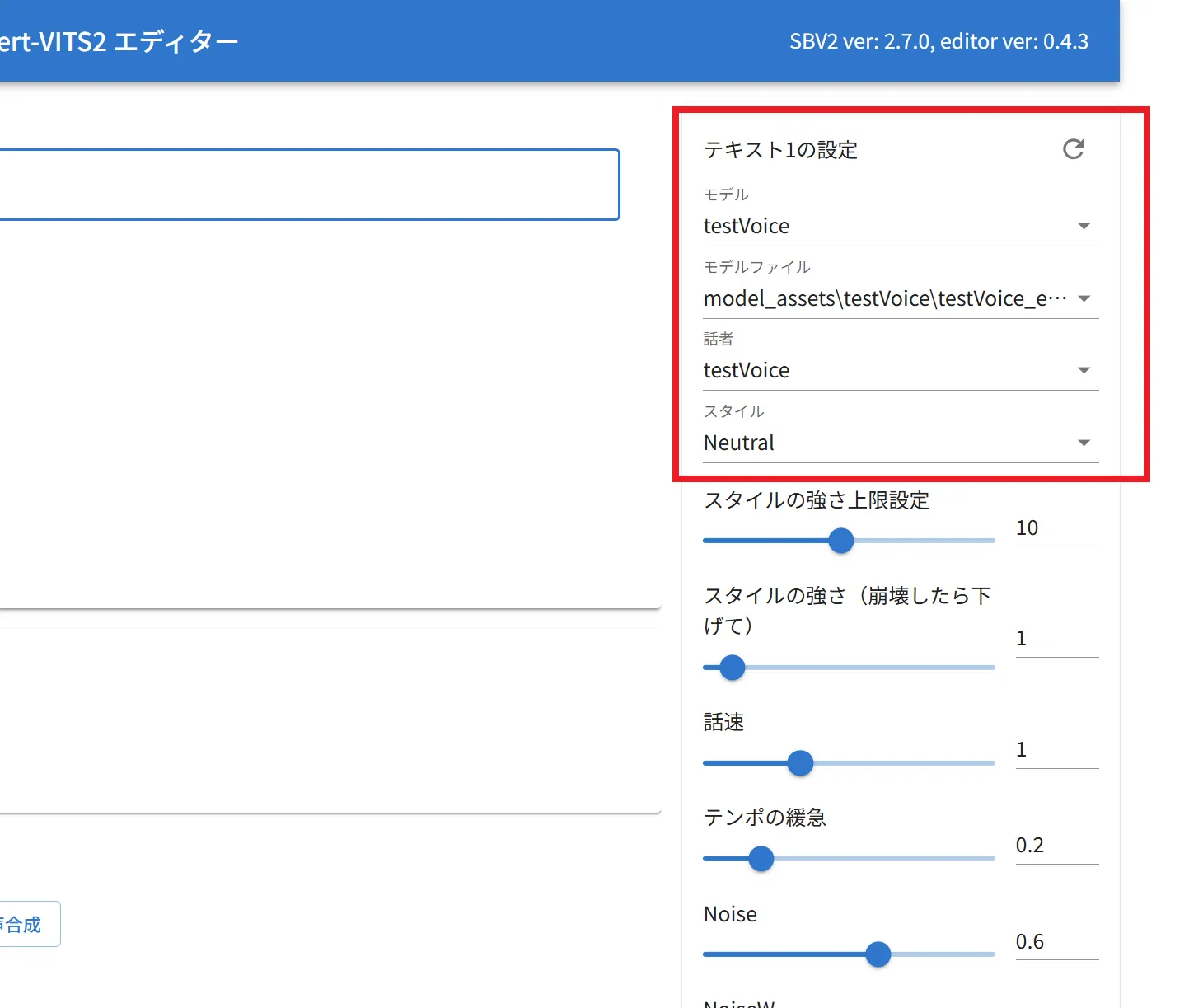
エディターが起動したら、右側にある設定から学習したモデルファイルを選択し、あとはテキストを入力して生成するだけです。
これで音声合成の説明は終わりです。
次はAivisSpeechで動かす手順を解説していきます。
AivisSpeechで学習した音声を使用する
それでは、学習したモデルをAivisSpeechで使えるようにしていきます。
学習時にも使用した「App.bat」を起動してください。
起動したら「ONNX変換」タブを開きます。
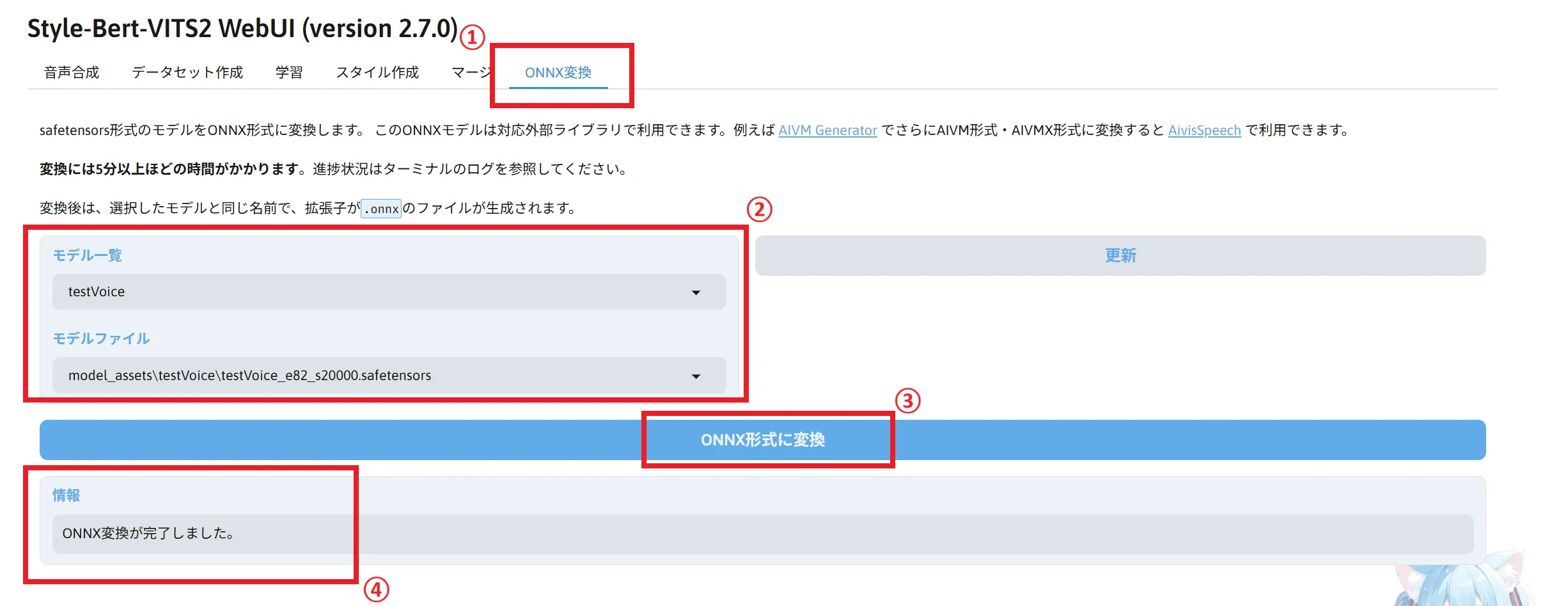
モデル一覧から変換したいモデル名を選択し、モデルファイルから変化したいモデルデータを選択します。
モデルの選択が終わったら「ONNX形式に変換」をクリックし、完了メッセージが出るまで待ちます。
変換が完了したらAIVM Generatorを開きます。
下の方へスクロールすると「各ファイルから新規生成」タブがあります。
この箇所を設定していきます。
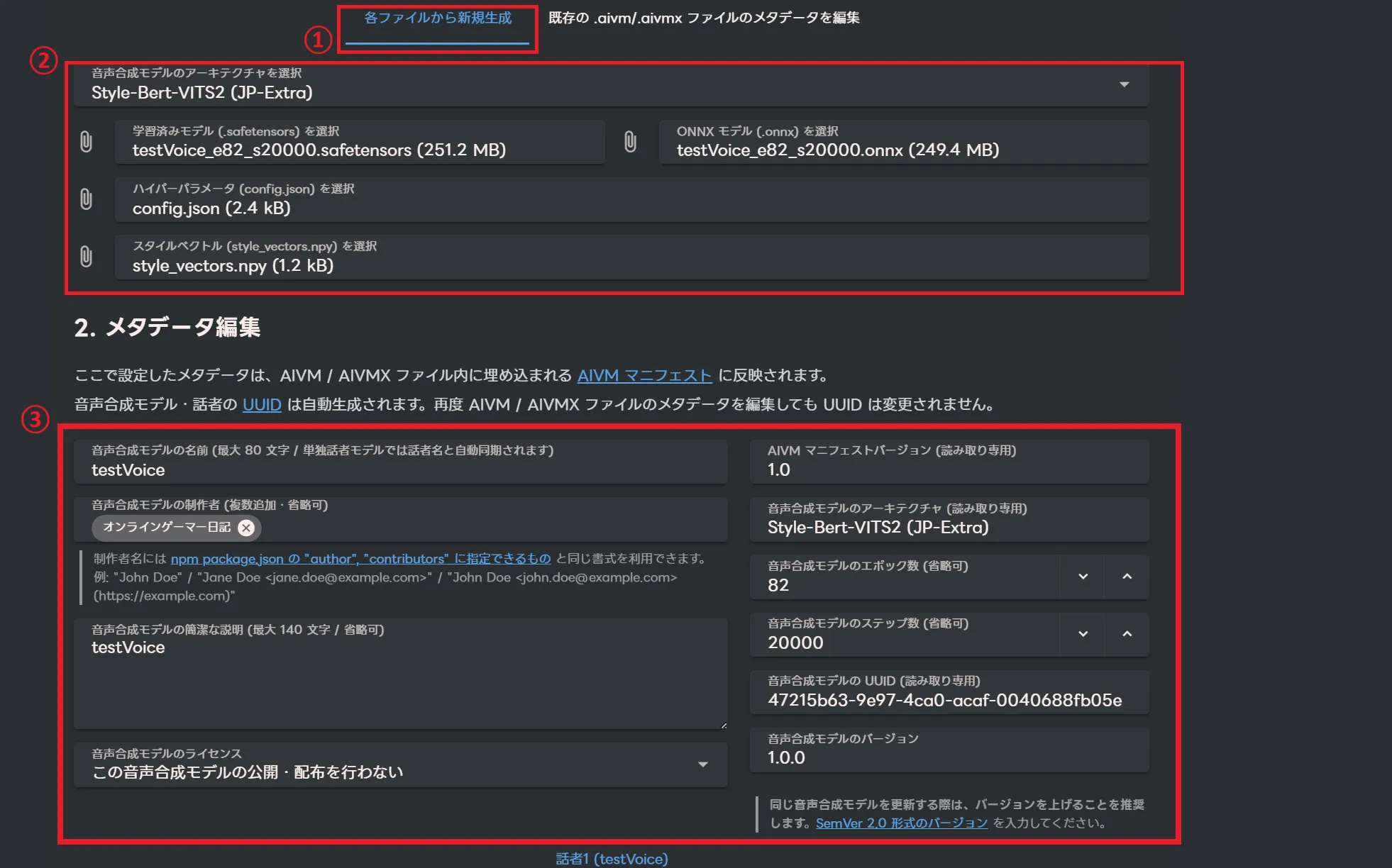
学習済みモデルに学習したモデルファイルを選択します。
ハイパーパラメータに「config.json」ファイルを選択。
スタイルベクトルに「style_vectors.npy」ファイルを選択。
ONNXモデルに先ほど変換した.ONNX ファイルを選択。
メタデータ編集ではモデルの名前と製作者の名前やモデルの説明などを記入できます。
ここで入力するモデル名にはキャラ名などを入力すると良いでしょう。
下にスクロールすると話者の設定が出来ます。
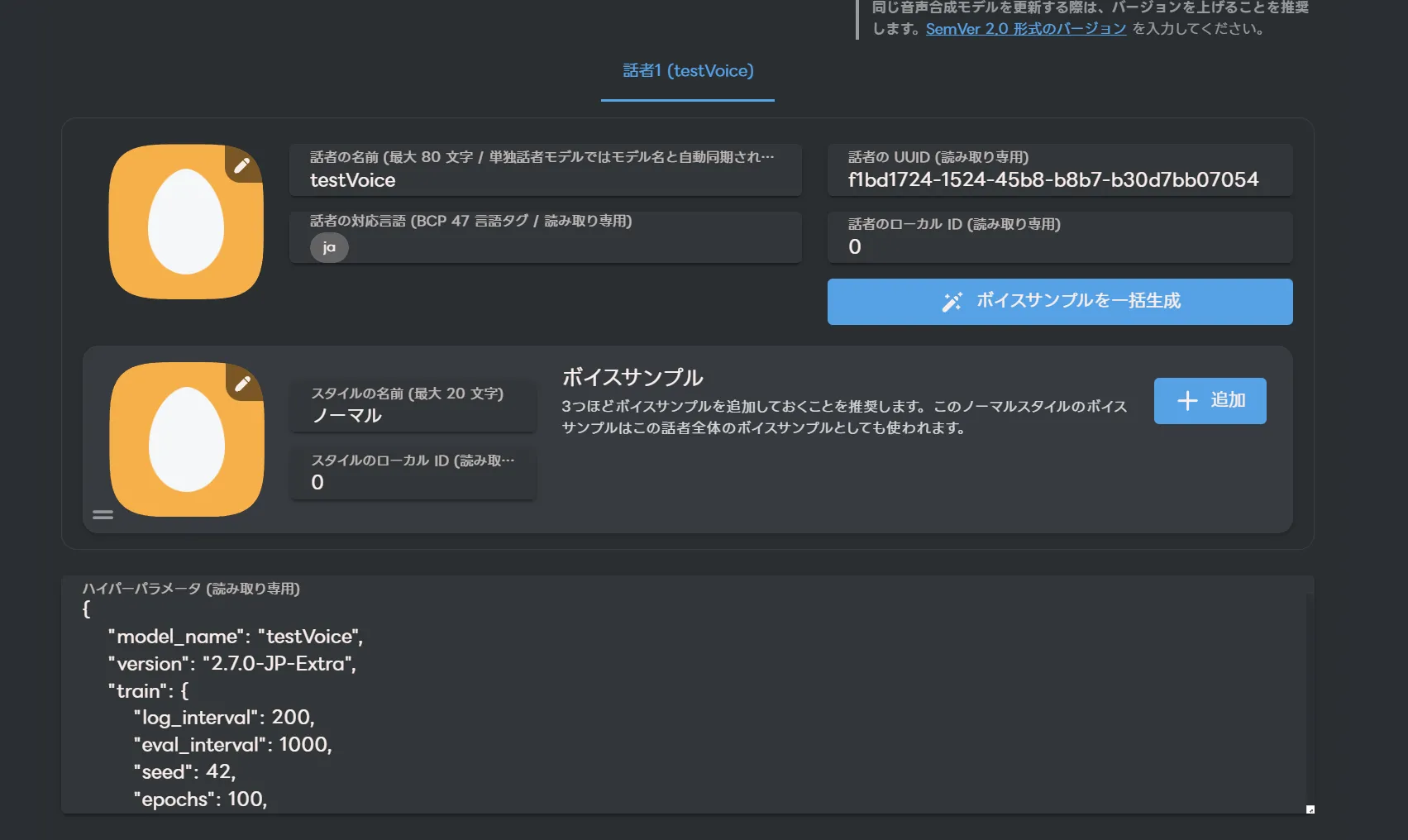
ここではアイコンなどを設定できます。キャラ画像などを設定すると良いでしょう。
最後に「上記メタデータで AIVM / AIVMX ファイル (.aivm / .aivmx) を生成」をクリックします。
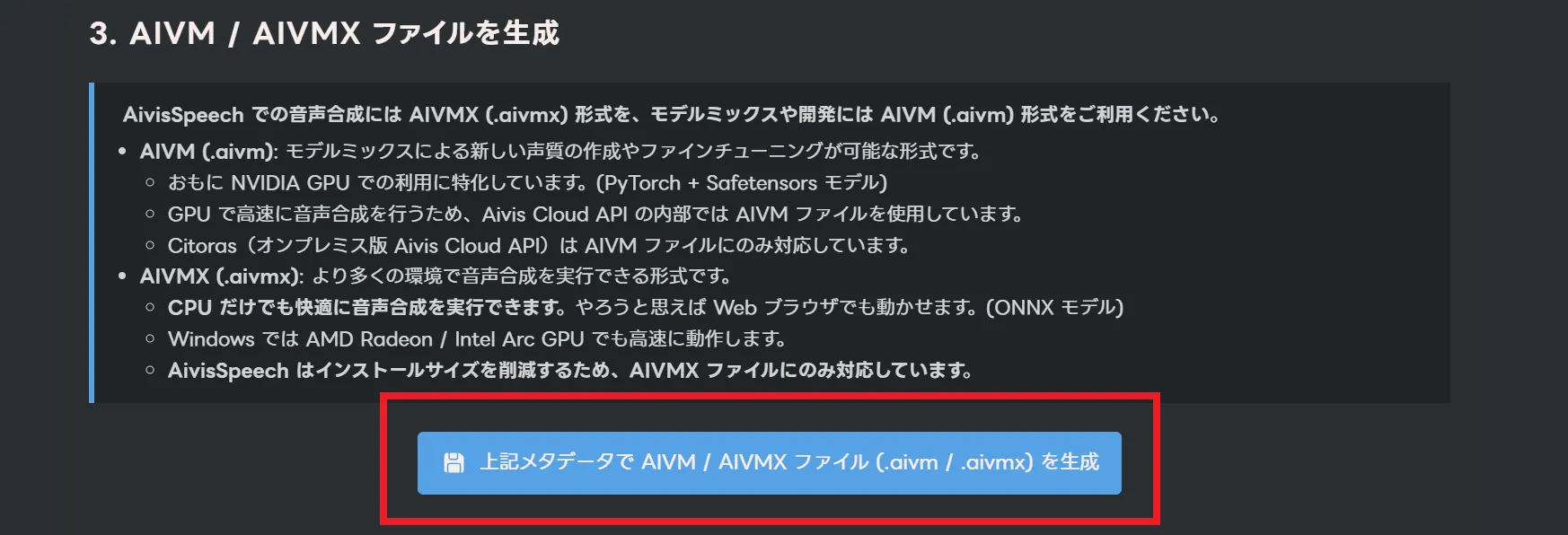
これで.aivmファイルと.aivmxファイルを2つをダウンロード出来ます。
※ブラウザの設定によっては複数ファイルのダウンロードがブロックされる場合があるので、その時は複数ファイルのダウンロードを許可してください。
あとはAivisSpeechでダウンロードしたモデルを読み込むだけです。それでは「AivisSpeech」を起動しましょう。
起動したら、上部メニューバーの「音声合成モデル」から「音声合成モデルのインストール・管理」をクリックします。
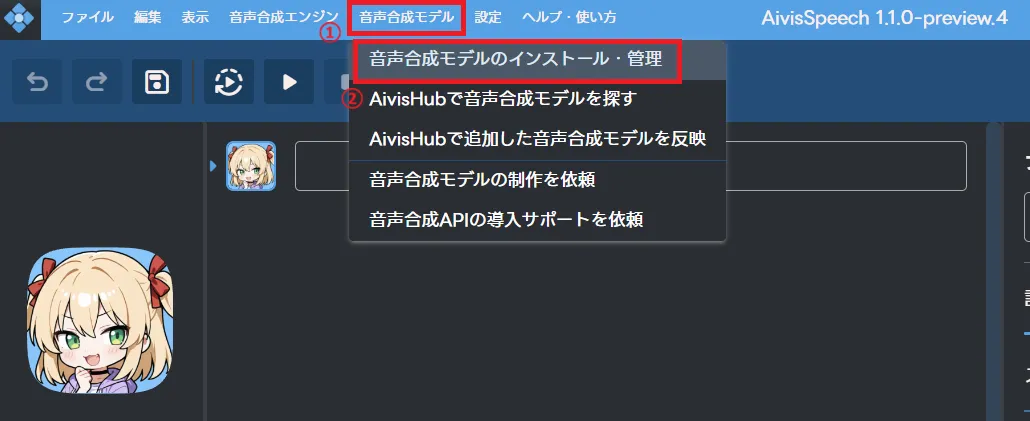
次に「ファイルからインストール」を選択し、ダウンロードした.aivmxファイルを選択します。
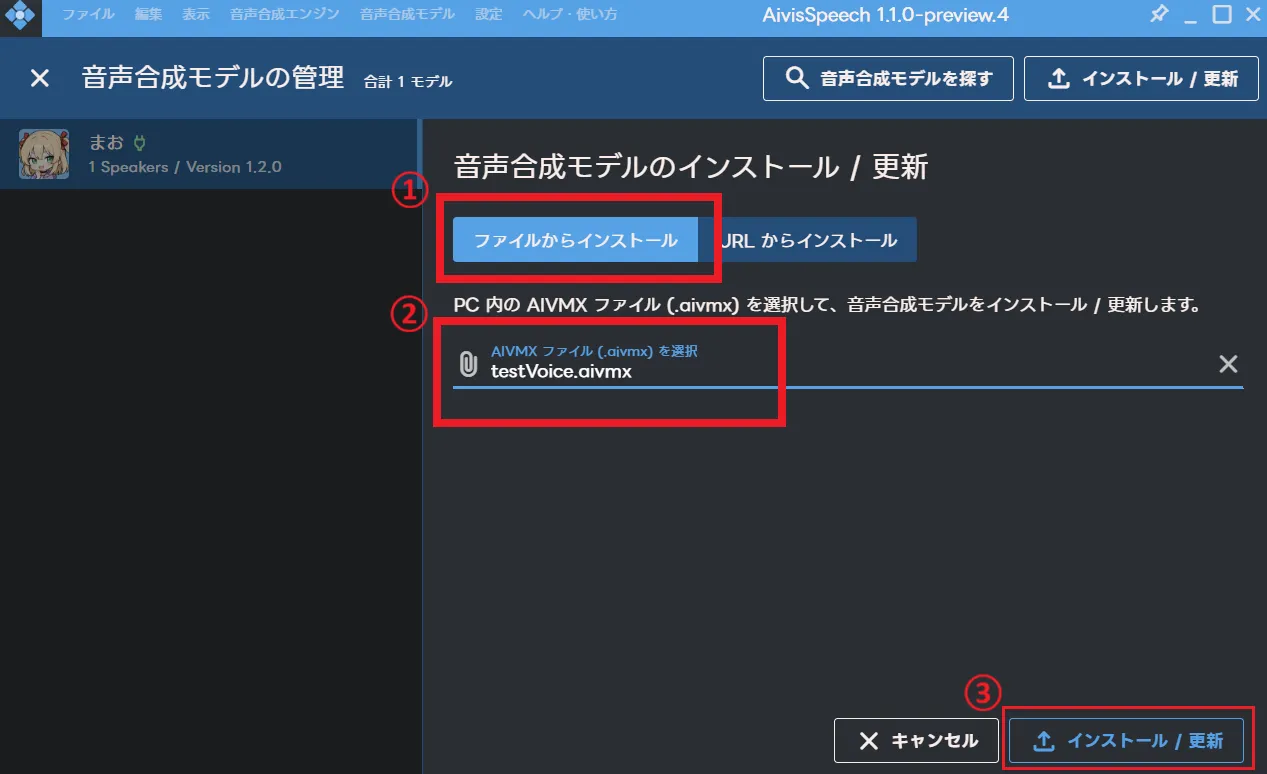
選択し終えたら、右下にある「インストール / 更新」をクリックします。
インストール完了まで待ちます。
この画面が出れば成功です。
あとは、モデルを切り替えてテキストを入力して喋らせるだけです。
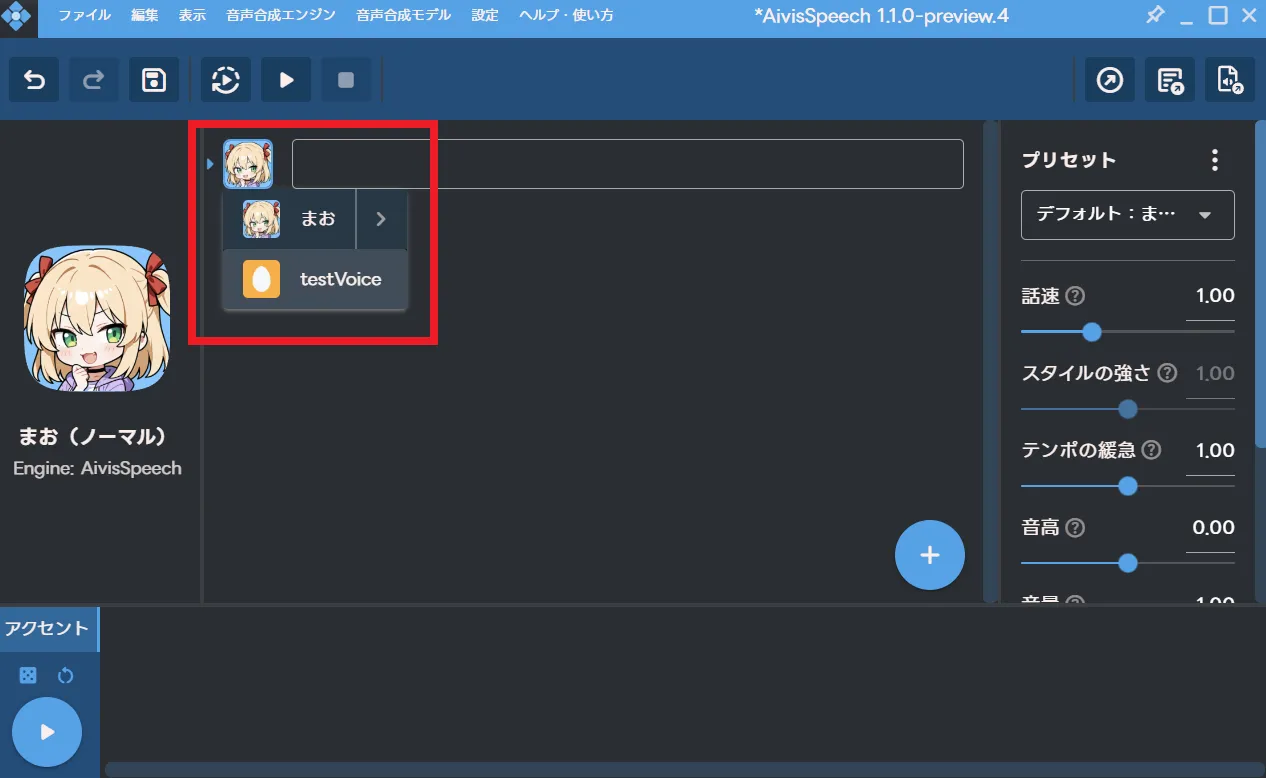
これで学習したモデルをAivisSpeechで使用する方法の解説は完了です。
スポンサーリンク
最後に
少し手間な部分もありましたが、これで好きな声でテキストの読み上げを行えるようになりました。
ゲームのセリフやナレーションなど、いろいろな事に使用して活動の幅を広げることが出来ますね!
それでは!



コメント
神すぎる
RTX5070Tiで5時間格闘しましたが解決できずここにたどり着きました
ありがとう!
自分もRTX5070Tiで、RTX50シリーズでStyle-Bert-VITS2を使うための環境構築に難儀していましたが、この生地のお陰で音声の生成・AivisSpeechへの転用までできるようになりました!!
本当にありがとうございます…
ただ、Style-Bert-VITS2の導入のInstall-Style-Bert-VITS2.batの中身を書き換える過程ですが、変更すべき文字列をこのサイトから直接コピペして貼り付けたとき、「”」が全角になっていたり、「–index-url」とすべき部分が「-index-url」となっていて構文エラーが発生してました。
以下の文をコピペして、置き換えれば上手くいくと思います。
uv pip install “torch==2.7.1” “torchaudio==2.7.1” –index-url https://download.pytorch.org/whl/cu128
RTX5090使いですが、上記の通りやってもStyle-Bert-VITS2が一部モジュールの最新版に対応していない関係でインストールと音声合成が失敗します。
原因と思われるsetuptoolsのバージョンを下げてブラウザが起動し、transformersもバージョンを下げて何とか音声合成に成功しました。
エラーの原因調査に時間を割いたため音声学習は未着手ですが、いずれそちらも試そうと思います。
こちらに書かれていることを全て試してみたんですか動かないですね
二ヶ月前は使えていたのに急に使えなくなって不思議です
こちらの記事を参考にStyle-Bert-VITS2の導入を行いましたが下記のエラーが出ます
Traceback (most recent call last):
File “D:\Style-Bert-VITS2\sbv2\Style-Bert-VITS2\server_editor.py”, line 44, in
from style_bert_vits2.nlp import bert_models, onnx_bert_models
File “D:\Style-Bert-VITS2\sbv2\Style-Bert-VITS2\style_bert_vits2\nlp\bert_models.py”, line 17, in
from transformers import (
File “D:\Style-Bert-VITS2\sbv2\Style-Bert-VITS2\venv\lib\site-packages\transformers\utils\import_utils.py”, line 2320, in __getattr__
raise ModuleNotFoundError(
ModuleNotFoundError: Could not import module ‘DebertaV2Model’. Are this object’s requirements defined correctly?
もし可能であればご教授いただければ幸いです
自動でインストールされるsetuptoolsのバージョンが新しいとエラーが出るようです。記事を修正し、インストールされるバージョンを固定しました。26/4/4 追記 の欄をコピーしてお使いください。
ずっと起動せずに悩んでいましたが、こちらの記事と26/4/4 追記のアドバイスによりStyle-Bert-VITS2を動かすことができました、ありがとうございます。
色々な方法でやってもできなかったのですがこの方法でやったらできました!!ありがとうございます!!
>>35~79行目の赤で囲った部分を削除します。
削除したら「Install-Style-Bert-VITS2.bat」を起動します。
しばらくすると以下のようなエディター画面が起動します。
Install-Style-Bert-VITS2.batをクリックしたら以下のエラーになります。
詳しくないのでどこがどうなのかわかりません。AIに聞いてもポンコツすぎてエラーのループ地獄にはまっています。あきらめるしかないでしょうか?悲
Executing: uv pip install -r requirements.txt
Using Python 3.10.11 environment at: venv
x No solution found when resolving dependencies:
`-> Because there are no versions of lightning and pyannote-audio==3.4.0 depends on lightning>=2.0.1, we can
conclude that pyannote-audio==3.4.0 cannot be used.
And because you require pyannote-audio==3.4.0, we can conclude that your requirements are unsatisfiable.
Press any key to continue . . .
私の方でも新しくzipをダウンロードし、uvのキャッシュも削除して行いましたが、特にエラーが出ることなくエディター画面が起動しました。
違う行を削除していないかなど、手順をもう一度確認して実行してみてください。
早速の返信ありがとうございます。こちらの勘違いでグラフィックボードがついていないパソコンでしたので勘違いしておりました。Install-Style-Bert-VITS2-CPUのほうで同じ手順でできました。お手数をおかけしました。参考になりました。ありがとうございました。
5060tiです
>>35~79行目の赤で囲った部分を削除します。
削除したら「Install-Style-Bert-VITS2.bat」を起動します。
しばらくすると以下のようなエディター画面が起動します。
この手順の後、下記エラーがでます
Traceback (most recent call last):
File “C:\StayleBert\sbv2\Style-Bert-VITS2\server_editor.py”, line 196, in
bert_models.load_model(Languages.JP, device_map=device)
File “C:\StayleBert\sbv2\Style-Bert-VITS2\style_bert_vits2\nlp\bert_models.py”, line 106, in load_model
__loaded_models[language] = AutoModelForMaskedLM.from_pretrained(
File “C:\StayleBert\sbv2\Style-Bert-VITS2\venv\lib\site-packages\transformers\models\auto\auto_factory.py”, line 604, in from_pretrained
return model_class.from_pretrained(
File “C:\StayleBert\sbv2\Style-Bert-VITS2\venv\lib\site-packages\transformers\modeling_utils.py”, line 277, in _wrapper
return func(*args, **kwargs)
File “C:\StayleBert\sbv2\Style-Bert-VITS2\venv\lib\site-packages\transformers\modeling_utils.py”, line 5048, in from_pretrained
) = cls._load_pretrained_model(
File “C:\StayleBert\sbv2\Style-Bert-VITS2\venv\lib\site-packages\transformers\modeling_utils.py”, line 5316, in _load_pretrained_model
load_state_dict(checkpoint_files[0], map_location=”meta”, weights_only=weights_only).keys()
File “C:\StayleBert\sbv2\Style-Bert-VITS2\venv\lib\site-packages\transformers\modeling_utils.py”, line 508, in load_state_dict
check_torch_load_is_safe()
File “C:\StayleBert\sbv2\Style-Bert-VITS2\venv\lib\site-packages\transformers\utils\import_utils.py”, line 1647, in check_torch_load_is_safe
raise ValueError(
ValueError: Due to a serious vulnerability issue in `torch.load`, even with `weights_only=True`, we now require users to upgrade torch to at least v2.6 in order to use the function. This version restriction does not apply when loading files with safetensors.
See the vulnerability report here
https://nvd.nist.gov/vuln/detail/CVE-2025-3243406-03 20:50:00 | DEBUG | __init__.py:147 | pyopenjtalk worker server terminated
Press any key to continue . . .
原因分かりますでしょうか・・・?
脆弱性により、古いバージョンのPyTorchでは起動できなくなっています。本記事の「エディター起動に必要な修正箇所」にて、そのバージョンを避けたPyTorchをインストールしているはずなのでそのエラーは出ないはずなのですが、念のため使用しているバージョンを以下の方法で確認してください。
1. .sbv2\Style-Bert-VITS2 フォルダをコマンドプロンプトなどで開き以下のコマンドで仮想環境をアクティブにする。
「venv\Scripts\activate」
2.以下のコマンドでバージョンを確認する
「python -c “import torch; print(torch.__version__)”」
記事通りの手順で行っていれば “2.7.1+cu128” と表示されるはずです。もしご自身で別なバージョンを入れていたら、指定したバージョンが表示されていればOK。
このとき表示されるPyTorchのバージョンが、2.6以下だと脆弱性の関係で使用できないので、2.6以上にバージョンアップしてください。
Style-Bert-VITS2の導入で困ってます
最初に↓のように修正した後、
uv pip install “torch==2.7.1” “torchaudio==2.7.1” –index-url https://download.pytorch.org/whl/cu128
Install-Style-Bert-VITS2.batを起動し↓のエラーが出たのでrequirements.txtを記載の通りに書き換えました
hint: `av` (v10.0.0) was included because `faster-whisper` (v0.10.1) depends on `av>=10.dev0, <11.dev0`
hint: Build failures usually indicate a problem with the package or the build environmentPress any key to continue . . .
再度Install-Style-Bert-VITS2.batをメモ帳で開き35~79行目の赤で囲った部分を削除し、Install-Style-Bert-VITS2.batを起動するとエディター画面が開かず↓の文章がでてしまいます
Executing: git clone https://github.com/litagin02/Style-Bert-VITS2
fatal: destination path 'Style-Bert-VITS2' already exists and is not an empty directory.
Press any key to continue . . .
その後もう一度起動しても開かずにループする状態です
かなり初心者なので分かることがあれば教えていただきたいです
git cloneする際に、「Style-Bert-VITS2」が存在している為エラーが出ています。
ですが、git cloneコマンドは削除する35~79行目に含まれているので、そのエラーが出ることはないはずです。削除部分をもう一度確認してみてください。