

少し前に論文だけ出ていたLive2D用のレイヤー分けを自動で行ってくれるツール「see-through」が公開されていたので、試してみたいと思います。
過去にVtuberモデルやゲーム向けの立ち絵などでLive2Dを触っていた経験があるので、それを踏まえて感想も書いていこうと思います。
現在、see-throughは本家とComfyUI用があります。本家の方の導入手順がLinux用となっており、windowsでインストールする場合は修正箇所がいくつか出てきてしまうので、この記事ではComfyUI版を導入していきます。
ComfyUIの導入は以下の記事で解説しています。
それではどうぞ!
公開先リポジトリ
本家のリポジトリは以下。
Linuxを使っている方や、windows用に修正出来る方はこちらを利用するのが良いでしょう。
今回導入するComfyUI用カスタムノードのリポジトリは以下。
それでは、導入方法を解説していきます。
導入方法
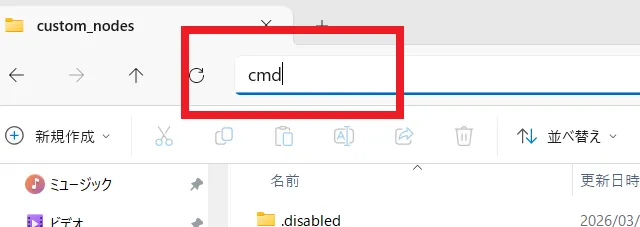
まず、以下のパスのフォルダへアクセスします。
.ComfyUI\custom_nodesアクセスしたら、アドレスバーに「cmd」と入力しエンターキーを押しコマンドプロンプトを開きます。
コマンドプロンプトを開いたら、以下のコマンドを入力し、ComfyUI版のsee-throughをインストールします。
git clone https://github.com/jtydhr88/ComfyUI-See-through.gitインストールが終わったら、必要に応じて依存関係をインストールします。
まずは以下のコマンドで「ComfyUI-See-through」へ移動します。
cd ComfyUI-See-through依存関係のインストールコマンドですが、ComfyUIで使用している環境によって実行するコマンドが異なります。
ここでは、以下の記事で導入したポータブル版ComfyUI用の環境でのコマンドを紹介します。
まず、ComfyUIのフォルダを開き、「python_embeded」フォルダを開きます。
開いたら、そのフォルダまでのパスをコピーしてコマンドプロンプトへ貼り付けます。
Cドライブ直下に保存していた場合、今の状態では以下のようになっていると思います。
C:ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\python_embeded次に、上記のコマンドの後ろの方に「\python.exe」と追記し、以下のようにします。
C:ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\python_embeded\python.exeここまで来たら、後はインストール用のコマンドを追加するだけです。上記のコマンドの後ろに半角スペースを空けて「-m pip install -r requirements.txt」と追記してエンターキーを押して実行します。
コマンドは以下のようになっています。
C:ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\python_embeded\python.exe -m pip install -r requirements.txt上記のコマンドをコピペすれば使えます。インストールフォルダが違う場合は適宜変更してください。
しばらく待てばインストールが終わります。
インストールが終わったらコマンドプロンプトは閉じて、ComfyUIを実行してください。
使用方法
それでは実際に1枚絵からLive2D用にレイヤー分けされたPSDファイルを出力していきます。
まずは、サンプルワークフローが以下のフォルダに入っているので、フォルダを開き「seethrough-basic.json」をComfyUIで読み込みます。
.ComfyUI\custom_nodes\ComfyUI-See-through\workflows読み込まれたワークフローは以下。
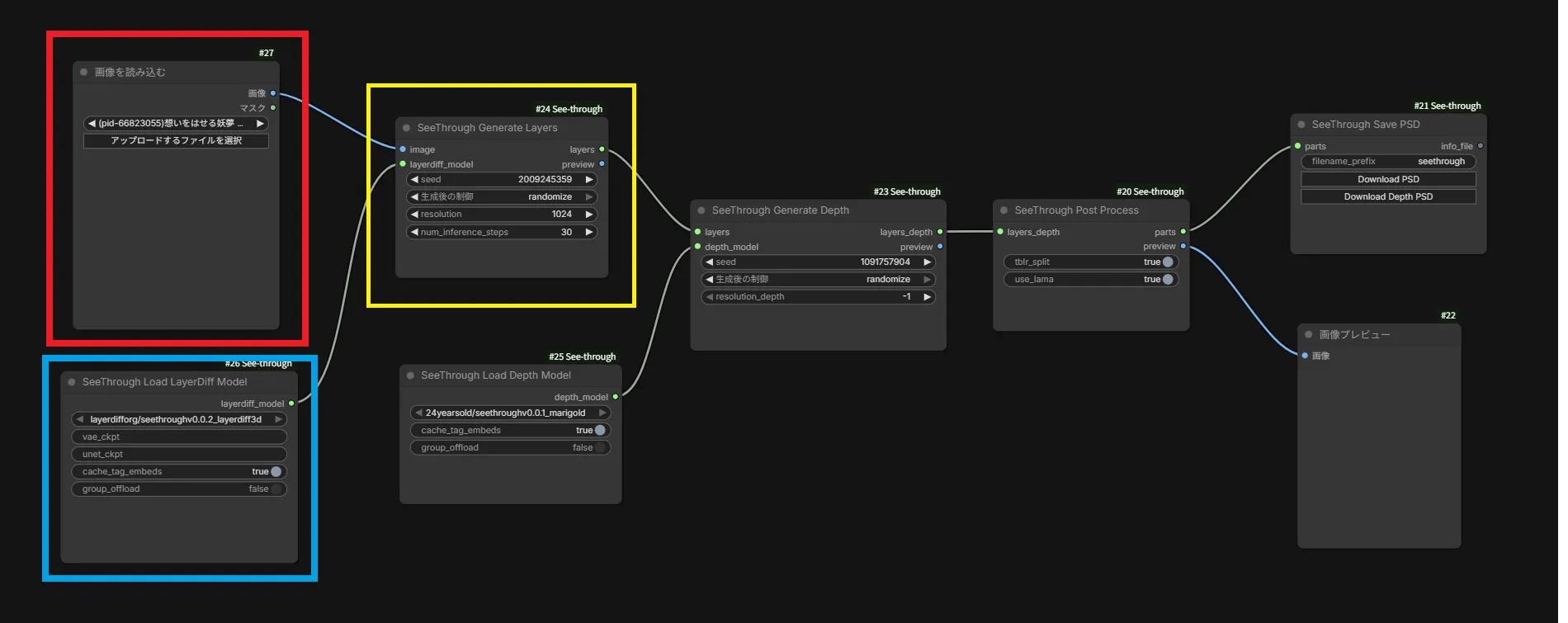
変更を加える部分は基本的には赤枠で囲ったノードのみです。使用しているPCスペックによっては青や黄色で囲ったノードも変更する必要があります。
赤、青、黄で囲ったノードについて簡単に説明していきます。
・画像を読み込む (赤枠)
このノードにレイヤー分けをしたい画像を読み込ませます。「アップロードするファイルを選択」ボタンを押すか、ノードに画像をドラッグ&ドロップしてください。
・SeeThrough Load LayerDiff Model (青枠)
使用しているGPUのVRAMが8~12GBと少ない場合は、このノードの”group_offload” をtrueに変更してください。これでVRAMの使用量を削減できます。ただし速度は大幅に低下します。
この機能を利用する場合、バージョンが0.37.0以上のdiffusersが必要になるので、以下のコマンドで使用している環境に合わせてインストールしてください。
pip install diffusers>=0.37.0・SeeThrough Generate Layers (黄枠)
使用しているGPUのVRAMが16GBある場合は、このノードの”resolution”を1280に、24GB以上あるのなら2048に変更してみても良いかもしれません。
“num_inference_steps”の数値を上げると画質が向上します。
簡単にまとめると
VRAMが16GB以上であれば画像の読み込みのみ行い、他はデフォルト設定でOK。VRAMが8~12GBの場合は、画像の読み込みと各種設定を行う必要がある。
VRAMが多いなら、解像度の設定を1280や2048にしても良い。
という感じです。
それでは、画像を読み込んで「実行する」ボタンを押して実行していきましょう。
私は以下の画像を使用しました。

初回実行時のみ、必要なモデルのダウンロードがあるので時間がかかります。
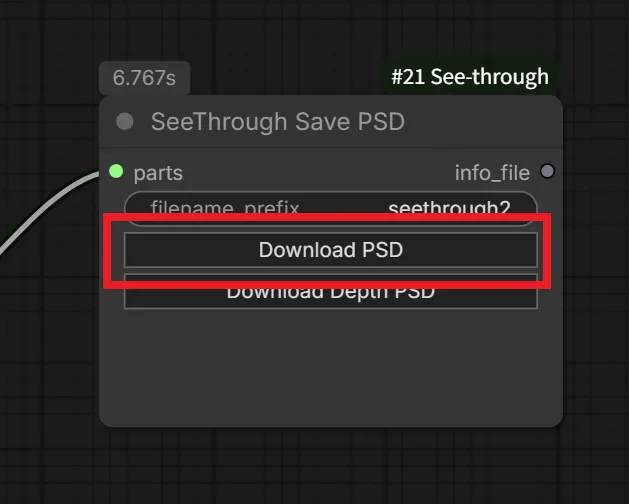
処理が終わったら、「SeeThrough Save PSD」ノードの”Download PSD”ボタンからレイヤー分けされたPSDをダウンロードできます。
それでは、レイヤー分けされたPSDを見ていきましょう。
レイヤー分けされたPSDを確認
Live2Dに読み込んで、テクスチャアトラスを作成した結果はこのような感じでした。

背景は自動で取り除かれたものがPSDとして出力されるようです。
スポンサーリンク
このまま販売出来るかどうか
レイヤー分けされたPSDを見て、このまま販売出来るかどうかについて個人的な見解です。
解像度が低すぎるという点は除いて話します。
だいぶ大雑把な分け方になってはいますが、Live2D対応自体は出来そうです。
ただ、このレイヤー分けのまま作成したLive2Dモデルを販売しようというのはおすすめしません。あくまでも自分の動画やゲームなどに組み込むようです。
というのも、販売レベルとして見るとレイヤー分けが不十分です。
多くの販売されているLive2DモデルはVtuber用のモデルなので、Vtuberモデル作成を前提として話します。
まず、Live2Dの講座記事や動画、もしくはnizimaのイラスト作品カテゴリで販売されている多くの作品のサンプル画像に、部位ごとに分けられたレイヤー一覧かテクスチャアトラスの画像が載っているので見てみてください。
販売されているPSDファイルでは髪パーツだけ見ても、最低でも前髪、横髪(右)、横髪(左)、後髪の4レイヤーに分かれています。ですが、see-throughでのレイヤー分けでは前髪と後髪の2レイヤーにしか分かれていません。
自然な動きを付けるなら、最低でも4レイヤーは必要です。
腕パーツも、販売されている多くのPSDファイルでは上腕と前腕で分かれていますが、see-throughでは右腕と左腕でしか分かれていません。この分け方では手を振るという動作が出来ません。
あとは口パーツですね。see-throughはあくまで読み込んだ画像から各部位を認識し、それをレイヤー分けするというツールなのでsee-throughの機能不足という訳ではないですが、このままだと口パクが出来ないので一般的なVtuberモデルとしては絶対に使えません。
口パクする為のレイヤー分けとしては、上唇、下唇、口内の最低3つが必要です。ですが、see-throughでは全て統合された1つのレイヤーとなっています。読み込む画像を変えて、口を開いている画像でPSDを出力させても結果は同じでした。
他にも、画像を変えてリボンなど装飾のある衣装を着たキャラの画像でPSDを出力させてみましたが、リボンが衣装にくっ付いたままレイヤーが分かれていました。
こういった小物も細かくレイヤー分けされているのが基本的な作りです。
こういった理由からVtuber用のモデルとして販売出来るレベルではありません。力業で作成出来たとしても、そのクオリティは数千円という安価で売られているモデルにも劣る事でしょう。
もし、このままの状態でLive2D化して販売したいというのであれば、Live2Dを用いたアニメーション作品として販売するのが良いと思います。
どういった用途に向いているか
どういった用途で使えるのかですが、
本家リポジトリに載っている「trailer.mp4」という動画のように、口パクが必要のない用途であれば使えそうです。
例えば、放置少女というゲームのタイトル画面のようなものです。
see-throughで分けたままの状態で使う場合は、画面を少し豪華にしたい程度の用途で使うのが一番かと思います。
Vtuberモデルやゲームの会話パート、イベントCGなどで使用する場合は大幅な加筆または修正が必要になることでしょう。
Vtuber用モデルとしては使えないのか
Vtuberモデルとして絶対に使えないのか。
まず結論から言います。セルフ受肉というのであれば問題ありません。
先述したのはあくまで販売できるレベルではないという話であり、Vtuberモデルが作れないという訳ではありません。
ただ、最低でも口パクは出来るように修正が必要でしょう。
修正せずにそのままでも作成出来ますが、ゆっくり実況やボイロ実況などで使われる立ち絵と変わりありません。ゆっくり実況などで使われる立ち絵には口パク用の差分があるものがほとんどなので、それよりも劣ります。
なので最低でも口パクが出来るようにはしたいですね。
あとは、可能であれば髪パーツも前髪と左横髪、右横髪、後ろ髪くらいには分けたいところですね。
Live2Dのおすすめ参考書
私が実際にLive2Dモデルを作成するときに役に立ったと思った書籍を紹介します。
まず1冊目が『VTuberキャラクターデザイン&Live2D超入門―わかるLive 2D動画解説付き』です。
この1冊でVtuberモデルの作成が出来るようになります。
サンプルとしてモデルデータやイラストデータなども付属しており、レイヤー分けの参考にもなります。また、他の入門系の書籍と違い、この書籍に付属するサンプルではアクセサリーや揺れものなども多く、その動かし方も非常に参考になります。
Vtuberモデルを作成したいのであれば、この1冊で決まりです。
次に紹介したいのが『Live2Dの教科書 改訂版 静止画イラストからつくる本格アニメーション』です。
Live2Dの入門書のほとんどはVtuberモデルの作成ですが、この書籍ではLive2Dの書籍では珍しく、ゲームの会話シーンなどで使える立ち絵モデルや、待機、攻撃、被ダメージのアニメーションの作成方法を解説しています。
最後に紹介する書籍が『Live2D モデリング&アニメーションTips』です。
この書籍は入門書ではないのですが、Live2Dの様々なテクニックが載っているので、Live2Dに慣れてきてもっとステップアップしたいという方におすすめです。
スポンサーリンク
最後に
このツールだけで本格的なLive2D対応!とは現状いきませんが、こういったツールは出た後の進化が速いのでこれからに期待ですね。
それでは!

コメント