

みなさん、動画生成AIのWanVideoは使っていますか?
Wan2.2は高ノイズモデルと低ノイズモデルやCLIPやVAE、作りたい動画によってはLoRAなど必要なものが多く、導入を躊躇っている方もいるかと思います。
ですが、そんな悩みを吹き飛ばすようなモデルがあります。
その名も「WAN2.2-14B-Rapid-AllInOne」です。
この記事ではWAN2.2-14B-Rapid-AllInOneの導入方法と私が作成したワークフローの配布まで書いていきます。
WAN2.2-14B-Rapid-AllInOne とは
このモデルを簡単に説明すると、ClipやVAE、高速化LoRAやNSFW系LoRAなどを統合したオールインワン(AIO)モデルです。
※NSFW系LoRAが入っていないバージョンもあります。
ClipやVAEを別で用意する必要がなく、モデルのダウンロードだけで色んなページを開かずに済みます。
導入方法
モデルとAIOモデル作成者が用意しているワークフローは以下のリポジトリからダウンロードできます。

バージョンによる違いなど、モデルの説明も書かれているので読んでから自分の用途にあったものをダウンロードしてください。
ダウンロード先は「checkpoints」フォルダです。
通常バージョンとMEGAバージョンがあります。通常バージョンはモデルもワークフローもT2V用とI2V用で分かれており、I2Vでは開始画像の指定しか出来ません。
対してMEGAバージョンでは、1つのモデルでT2VにもI2Vにも対応しており、開始画像と終了画像の指定が出来ます。
なので、基本的にはMEGAバージョンを選んでおけば間違いないです。
MEGAバージョンのワークフローはリポジトリの説明にも書いてある通り、以下の「Mega-v3」フォルダの中に入っている.jsonファイルとなります。
Mega-v3のフォルダに入っていますが、他のバージョンでも使用できます。
こちらのワークフローの使い方は、リポジトリの説明、またはワークフロー内にも書いてあるので、そちらを確認してください。
スポンサーリンク
ワークフローの配布
それでは、私の作成したワークフローを配布します。AIOのバージョンはMEGAを前提としています。
基本的な生成のみのワークフローと、アップスケールやフレームレート補間、プロンプト自動生成やFaceDetailerなど、後処理を追加したワークフローを用意しました。
基本的な生成のみのワークフローを「通常生成ワークフロー」とし、後処理を追加したワークフローを「後処理追加ワークフロー」として説明していきます。
また、以下のことに注意してください。
・必要なカスタムノードはワークフローを読み込んだ際に不足カスタムノードが出てくると思うので、そちらを確認しながらインストールしてください。
・必要なモデルはワークフロー内に記載していますが、記載漏れがあった場合はモデル名で調べれば出てくるので、各自でダウンロードしてください。
・ワークフローを読み込んだ状態だと、モデルの指定パスが私のフォルダ階層となっているので、全てのモデルを使用している環境に合わせ指定しなおしてください。変更後に保存しておくと次回起動時にこの手順をスキップ出来ます。
ワークフローのダウンロードは以下のリンクから行えます。
通常生成ワークフローのダウンロード

後処理追加ワークフローのダウンロード

配布ワークフローの説明
通常生成ワークフローの説明
まずはワークフローの全体図です。

左側の「設定グループ」でプロンプトが画像の指定を行えます。
右上の「生成グループ」で生成を行い、右下の「結果」に保存用のノードが実行されます。
基本的に数値などを変更するノードは「設定グループ」のみなので、そこに入っているノードについてのみ説明していきます。
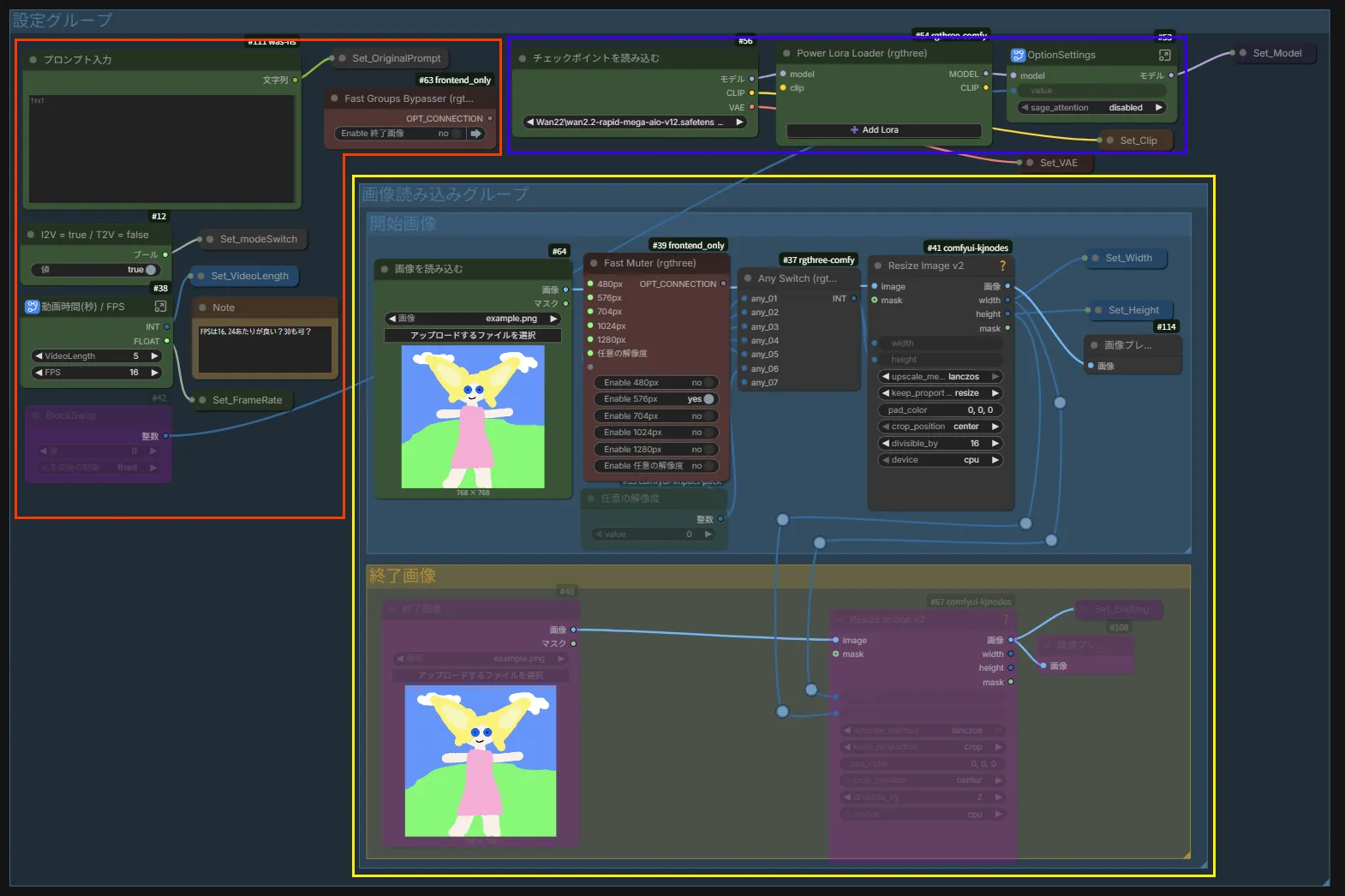
まずは赤で囲った部分のノードから説明していきます。
プロンプト入力 : プロンプトを入力するノードです。
I2V = true / T2V = false :生成モードを変更するノードです。I2Vならtrue、T2Vならfalseにしてください。
動画時間(秒) / FPS: 動画の再生時間とフレームレートを指定します。VideoLengthに再生時間、FPSにフレームレートを入力してください。
BlockSwap : 少ないVRAMでも動作するようにするノードです。VRAM不足のエラーが発生した時に、有効にして使用してください。数値を上げるとより少ないVRAMでも動くようになりますが、生成速度は低下します。
Fast Groups Bypasser (rgthree) : 終了画像を使用するかどうかのスイッチです。終了画像を使用する場合はONにしてください。
以上が赤で囲った部分の説明です。次に青で囲った部分の説明です。
チェックポイントを読み込む : このノードでモデルを選択します。
Power Lora Loader (rgthree) : もし使用したいLoRAがある場合はこのノードで指定します。「Add Lora」ボタンから追加できます。
OptionSettings : sage attentionを使用するかの設定。私の環境ではうまく導入出来なかったのでデフォルトでは使用していません。
最後に、黄色で囲った部分の説明です。
画像を読み込む : ここで開始画像を指定します。
Fast Muter (rgthree) : 動画の解像度を指定します。後に続くResize Image v2ノードで読み込んだ画像を選択した解像度に合わせて自動でリサイズします。また、任意の解像度を選択した場合、このノードの下にある「任意の解像度」ノードに入力された数値が反映されます。
終了画像 : 終了画像を指定します。読み込んだ画像は、自動で開始画像と同じサイズにリサイズされますが、可能な限り開始画像と近いサイズが好ましいです。
以上が通常生成ワークフローの説明となります。
スポンサーリンク
後処理追加ワークフローの説明
ワークフロー全体図です。

使い方は先ほどのワークフローと一緒で、「設定グループ」にあるノードの数値などを変更するだけです。このワークフローで追加されたノードと使い方のみ説明していきます。
手動プロンプト(自動翻訳) : 日本語で入力したプロンプトを、自動で英語に変換してくれるノードです。後述するプロンプト自動生成を使用する場合は「Manual Translate」をtrueで使用してください。
自動生成プロンプト使用 = true / 手動プロンプト使用 = false : プロンプトを自動生成するかどうかの選択です。自動生成するならtrue、しないならfalseを選択してください。
フレーム補間設定 : フレームレート補間の際、目標のフレームレートを指定できます。60FPSにしたいなら60と入力してください。
Fast Groups Bypasser (rgthree) : 選択項目が増えましたが、使い方は同じです。使用する機能をオンにし、使用しない機能をオフにします。前述したプロンプトの自動生成を使用しない場合は「プロンプト自動生成」のスイッチをオフにしてください。オンのままだと自動生成用のモデルが読み込まれ時間が掛かります。
アップスケール設定 : アップスケールで使用するモデルと倍率を設定できます。隣に入力する数値と倍率が書いてありますが、デフォルトで指定してあるモデルが倍率を指定しないと4倍にするモデル用の数値です。使用するモデルにより異なるので、使用するモデルを変更する場合は注意してください。
「設定グループ」に追加されたノードの説明は以上です。
また、動画を保存する際、最初のフレームを削除してから保存するようにしています。1フレーム目のみクオリティが極端に低くなる為です。
次に、追加した後処理機能についても簡単に説明していきます。
プロンプト自動生成の説明
この機能はLLMを使用し、ユーザーが与えたプロンプトに合わせて、動画生成用のプロンプトを生成する機能です。なので、この機能を使用する場合でも「手動プロンプト(自動翻訳)」ノードの入力は必須です。ただし、動画生成用のプロンプトではなく、「ダンスする」というような簡単なプロンプトで構いません。

プロンプト自動生成の中身はこのようになっています。
「Vision Model Loader (Transformers)」ノードでLLMモデルをロードしています。その下にある「指示プロンプト」ノードが、LLMに対する指示です。もし生成されるプロンプトに不都合があるなら、ここの指示を変更してみてください。
また、別にLM StudioなどのLLM用ツールを導入しているのであれば、そちらのツールと連携できるカスタムノードを使用して普段使用しているモデルを利用する方が良いです。
私が使用しているワークフローでは、この部分はLM Studioと連携できるカスタムノードを使用して「qwen3-vl-8b-nsfw-caption-v4.5」のGGUF版のQ8_0を使用しています。
FaceDetailerの説明
こちらはイラスト生成時でもよく使われているFaceDetailerの動画版です。
イラスト生成時、目の虹彩部分がグチャグチャになっている事が多いと思います。静止画なので気にならない方も多いかもしれませんが、動画となると動いている分チラつきが目立ちます。
そのチラつきを抑える為の機能です。完全に無くなるわけではないので、その点はご注意ください。
それでは、実際にどれくらい変わるかご覧ください。
左のBeforeがFaceDetailer処理前、右のAfterが処理後です。
目や前髪、鼻が分かりやすいと思います。処理前では虹彩や鼻のチラつきが気になりますが、処理後ではそれが抑えられています。
FaceDetailerの注意点ですが、「生成グループ」で生成した動画の解像度が高いと失敗する可能性があります。原因はFaceDetailerグループで最初の方に行うアップスケールにて、アップスケール後の解像度が高すぎると事です。
もしUpscaleノードで停止してしまった場合は、一度ComfyUIを終了させてから再度起動し「Upscale」ノードのサブグラフ内に入り「画像を拡大(指定サイズ)」ノードの”スケールバイ”の数値を低くするか、「Upscale」ノードをバイパスしてください。
また、デフォルトでは「UltralyticsDetectorProvider」ノードに顔を検出するモデルが指定されていますが、こちらのモデルを変更することで検出対象を目や手などに変更できます。
スポンサーリンク
CUDA out of memory エラーが出たら
VRAM容量によっては、全ての処理を1度に行うとVRAMが足りなくなってエラーが出る場合があります。Wan2.2のモデルとプロンプト自動生成用のLLMモデルを同時に読み込んでいるのが原因です。
そういう場合は、それぞれの処理を単独で動かし、処理後にVRAMの解放を行ってください。
やり方は、単独で動かしたい処理のノードを全てコピーし、新しく作成したワークフロー内に貼り付けます。次に、set / get ノードを使用している箇所があるので、そちらを該当するノードに入れ替えればOKです。
最後に
画像生成AIのように、モデル1つで動かせるので導入が簡単になって嬉しいですね。
それでは!



コメント
突然のコメント失礼いたします。
参考にさせていただき順番にインストール等をしたのですがエラーが出てしいます。
Cannot execute because a node is missing the class_type property.: Node ID ‘#20’
という表示なのですが何が問題でどこを直せばいいのでしょうか?
一からやり直しを何度かしても同じエラーを吐いてしまいます。
連続の投稿申し訳ございません。
通常生成ワークフローから画像を指定し先ほどのエラーに関してはCrystoolsをインストールし解決したのですが実行を押すと指定した画像と同じ画像が生成されるだけで動画の生成がされません。
通常生成フローと後処理追加フローは別物と考えていたのですが違うのでしょうか?
初めての生成AIで無知で申し訳ございません。
記事内のリンクからワークフローをダウンロードしこちらでも確認してみましたが、問題なく動画が生成されました。
指定画像と同じ画像が生成されるという所からの推測ですが、画像プレビューノードを見ていませんか?生成された動画は、右下の結果グループにあるVideo Combineノードに表示されます。
確認してみてください。
導入に従いワークフローを作成いたしましたが、下記エラーで実行出来ませんでした。
内容についてご存じでしょうか?
VisionModelLoaderTransformers
Failed to load model: Huihui-Qwen3-VL-8B-Instruct-abliterated
Huihui-Qwen3-VL-8B-Instruct-abliterated のモデルが無いというエラーなので、「\models\LLM」フォルダにモデルデータ一式をダウンロードしてください。
初歩的な質問でした……
ご回答ありがとうございます。
度々失礼いたします。
こちらStabillityMatrix環境にて動かすことは可能でしょうか。
実際に試した訳ではないですが、動くと思います。
導入は問題なくできたのですが、通常生成ワークフローでi2vすると出来上がってくる動画がグレーになってしまいます。
色々設定を変えてみたのですが、解決できないため原因が分かれば教えていただきたいです。
こちらでは再現できませんでした。
モデルバージョンの変更やComfyUIのアップデートなどを試してみてください。ComfyUIをアップデートする時はバックアップを取っておくことをおすすめします。
すみません、ワークフローを読み込んで実行ボタンを押した際に以下のエラーが出てしましました。
お手数ですが内容についてご存じだったりますでしょうか。
SyntaxError: Unexpected non-whitespace character after JSON at position 4 (line 1 column 5)
すみません、ワークフローを読み込んで実行ボタンを押した際に以下のエラーが出てしましました。
お手数ですが内容についてご存じだったりますでしょうか。
SyntaxError: Unexpected non-whitespace character after JSON at position 4 (line 1 column 5)
こちらでも試してみたところ、フロントエンドを最新(v1.40.8)にすると同じエラーが発生しました。
ComfyUIの起動用batファイルが保存されている場所でコマンドプロンプトを開き、以下のコマンドを実行してフロントエンドのバージョンを下げてください。
pip install comfyui-frontend-package==ここにバージョンを入力
使用しているComfyUIがポータブル版であれば以下のコマンドを実行してください。
python_embeded\python.exe -m pip install comfyui-frontend-package==ここにバージョンを入力
v1.39.14のフロントエンドをインストールする場合は以下のようなコマンドになります。
pip install comfyui-frontend-package==1.39.14
python_embeded\python.exe -m pip install comfyui-frontend-package==1.39.14
返信いただきありがとうございます!
自分は stability matrix を使用しているので色々と少し違うところがあるかもしれません。
自分のフロントエンドのバージョンはComfyUIの設定(歯車アイコン)の「情報」を見たところ、「ComfyUI_frontend v1.38.14」 とありました。
この確認の仕方で合っているかわかりませんが、仮に合っていた場合はアップグレードした方がよいでしょうか。
あとポータブル版を使用していたと思うのですが、
「StabilityMatrix-win-x64\Data\Packages\ComfyUI\.ci\windows_nvidia_base_files」
階層にある「run_nvidia_gpu.bat」があるところでターミナルを開いて
python_embeded\python.exe -m pip install comfyui-frontend-package==1.39.14
を試してみたところ以下のエラーが出てしまいました。
python_embeded\python.exe : モジュール ‘python_embeded’ を読み込むことができませんでした。詳細については、’Import-Modul
e python_embeded’ を実行してください。
発生場所 行:1 文字:1
+ python_embeded\python.exe -m pip install comfyui-frontend-package==1. …
+ ~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : ObjectNotFound: (python_embeded\python.exe:String) [], CommandNotFoundException
+ FullyQualifiedErrorId : CouldNotAutoLoadModule
お手数ですが見て頂けると幸いです。
「run_nvidia_gpu.bat」と同じ階層に「python_embeded」というフォルダはありますか? “python_embeded\python.exe” こちらのコマンドは「python_embeded」フォルダに入っているpython.exeを使うというコマンドなので、フォルダが無い場合やフォルダ名が違う場合はエラーが出ます。
私はstability matrixを使用したことが無いので確かな事は言えませんが、stability matrix用で使われているpython.exeがあると思うので、そちらを指定してみてください。
また、バージョンについてですが、私の使用しているバージョンを載せておきます。
ComfyUI : 0.14.1
ComfyUI_frontend : v1.39.14
ご返信ありがとうございます!
別のバージョンのComfyUIをインストールしなおしました。
ただ、不足しているノードをすべてダウンロードでダウンロード、インストールしてもSwitch Any [Crystools] だけがずっと不足しており、ノードに赤枠がついたままだったので「ComfyUI-Crystools」からGit Clone でインストールしましたが、やはり不足していると出て実行時にエラーが出るようです。
Cannot execute because a node is missing the class_type property.: Node ID ‘#20’
このあたりまだまだ勉強が必要そうなのでもう少し調べてみたいと思います・・・!
こんにちは!
素晴らしいワークフローをご紹介頂きありがとうございます。
Loraを使用したいと考えているのですが、Highとlowの両方をPower Lora Loaderに追加すればよいのでしょうか?ご教授いただけると幸いです。
どちらか片方を追加すればOKです。
Lowノイズ用のLoRAが推奨されていますが、Highノイズ用でも機能しているので好みの生成結果になる方を使うと良いです。
汎用性がある分、当然というか特化させた使い方は難しいですね
あくまでも入門的な位置づけなんですかね?