

動画生成AIで生成していると、音がなくて寂しいと思ったことはありませんか?
雰囲気が合っているBGMやSEであればテキトーに合わせても良い感じになってくれますが、セリフ音声はそうもいきません。
違和感の一番の原因はセリフと口の動きが合っていない事でしょう。
そんな悩みを解決するAIがありました!
その名も「InfiniteTalk」です!!
InfiniteTalkの簡単な説明
InfiniteTalkについて簡単に説明すると、1枚の静止画または動画から歌やセリフに合わせて自然な口の動きの生成を目的としたリップシンクモデルです。
導入方法
それでは、さっそく導入方法です。使用するツールはComfyUIです。
導入方法は簡単で、以下のサンプルワークフローをComfyUIで読み込むだけです。必要なカスタムノードはワークフローを読み込んだ際に表示されるので、それを確認しながら導入してください。
ただ、こちらのワークフローでは読み込んだ動画のFPSによっては意図しない動画が完成してしまうこともあるので、私の方でその辺りに手を加えたワークフローを用意しましたので、よかったら使ってください。
必要モデルは以下の通りです。
・wan2.1 保存場所 : ComfyUI/models/diffusion_models
Wan2_1-I2V-14B-480p_fp8_e5m2_scaled_KJ.safetensors
・text encoder 保存場所 : ComfyUI/models/text_encoders
umt5-xxl-enc-bf16.safetensors
・vae 保存場所 : ComfyUI/models/vae
wan_2.1_vae.safetensors
・clip vision 保存場所 : ComfyUI/models/clip_vision
clip_vision_h.safetensors
・高速化LoRA 保存場所 : ComfyUI/models/loras
lightx2v_I2V_14B_480p_cfg_step_distill_rank64_bf16.safetensors
・Mel-Band Roformer 保存場所 : : ComfyUI/models/diffusion_models
MelBandRoformer_fp16.safetensors
・wav2vec2 保存場所 : ComfyUI/models/wav2vec2
「wav2vec2」フォルダは手動で作成してください。
wav2vec2-chinese-base_fp16.safetensors
・InfiteTalk 保存場所 : ComfyUI/models/diffusion_models
このモデルは話者が1人用のモデルと複数人用のモデルがあるので、作成したい動画に合わせてダウンロードしてください。
1人用
Wan2_1-InfiniteTalk-Single_fp8_e5m2_scaled_KJ.safetensors
複数人用
Wan2_1-InfiniteTalk-Multi_fp8_e5m2_scaled_KJ.safetensors
ワークフローの配布
以下が私の作成したワークフローです。

こちらのワークフローを使用する際の注意点ですが、デフォルトの状態だとモデルのパスが私の環境のものになっているので、全てのモデル指定をご自分の環境に合わせて変更してください。
スポンサーリンク
配布ワークフローの説明
まずはワークフローの全体図です。
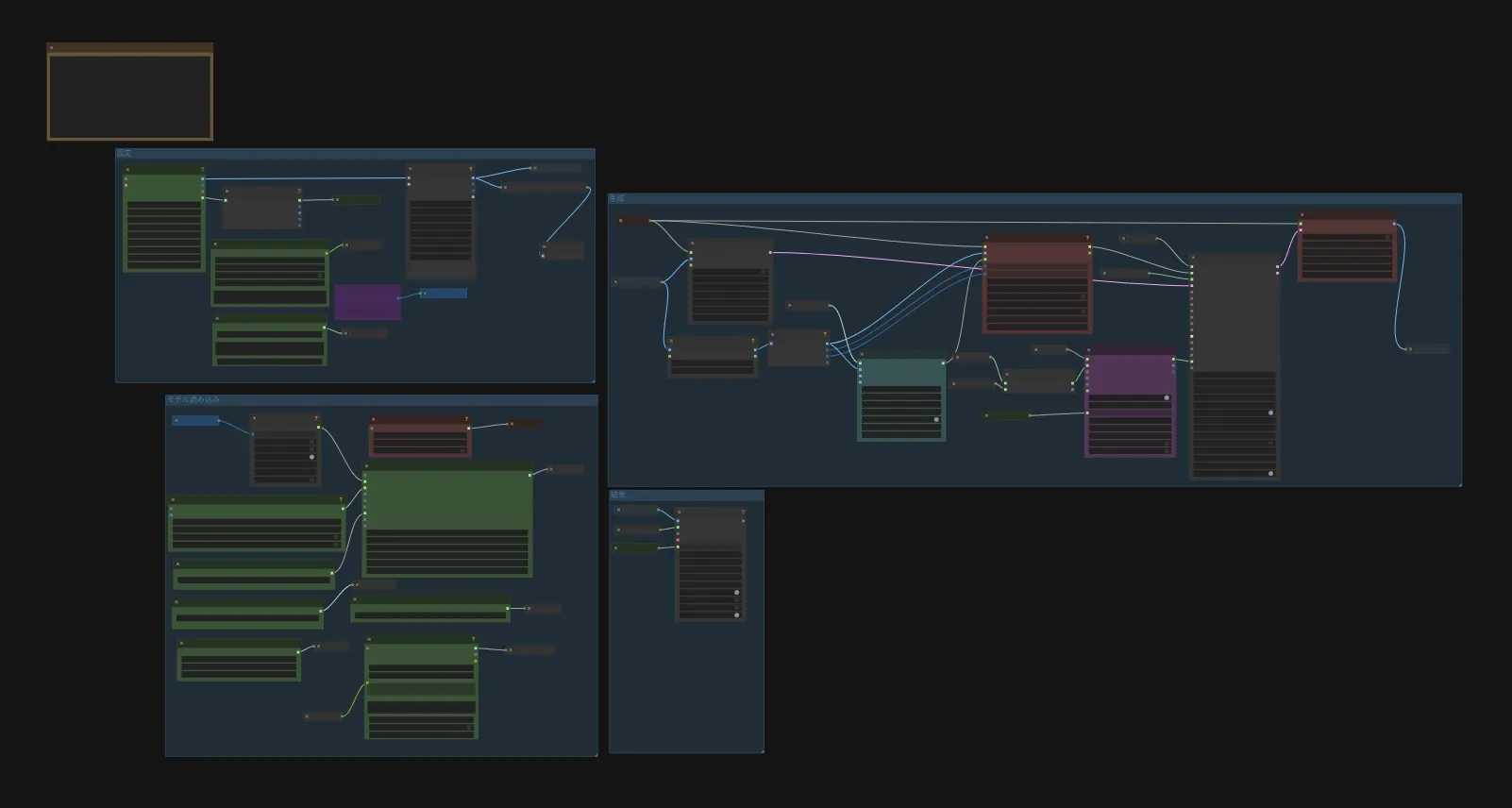
左上の「設定」グループで音声の読み込みや元動画の読み込みなどを行います。
左下の「モデル読み込み」ノードで各モデルの読み込みを行います。基本的にこのグループにあるノードは触りませんが、GGUFモデルへ変更する場合は該当するノードを変更してください。
右上の「生成」グループで生成を行います。このグループも基本的に触ることはありません。
右下の「結果」グループで保存用のノードが実行されます。
それでは、実際に音声や動画を読み込む「設定」グループの説明をしていきます。
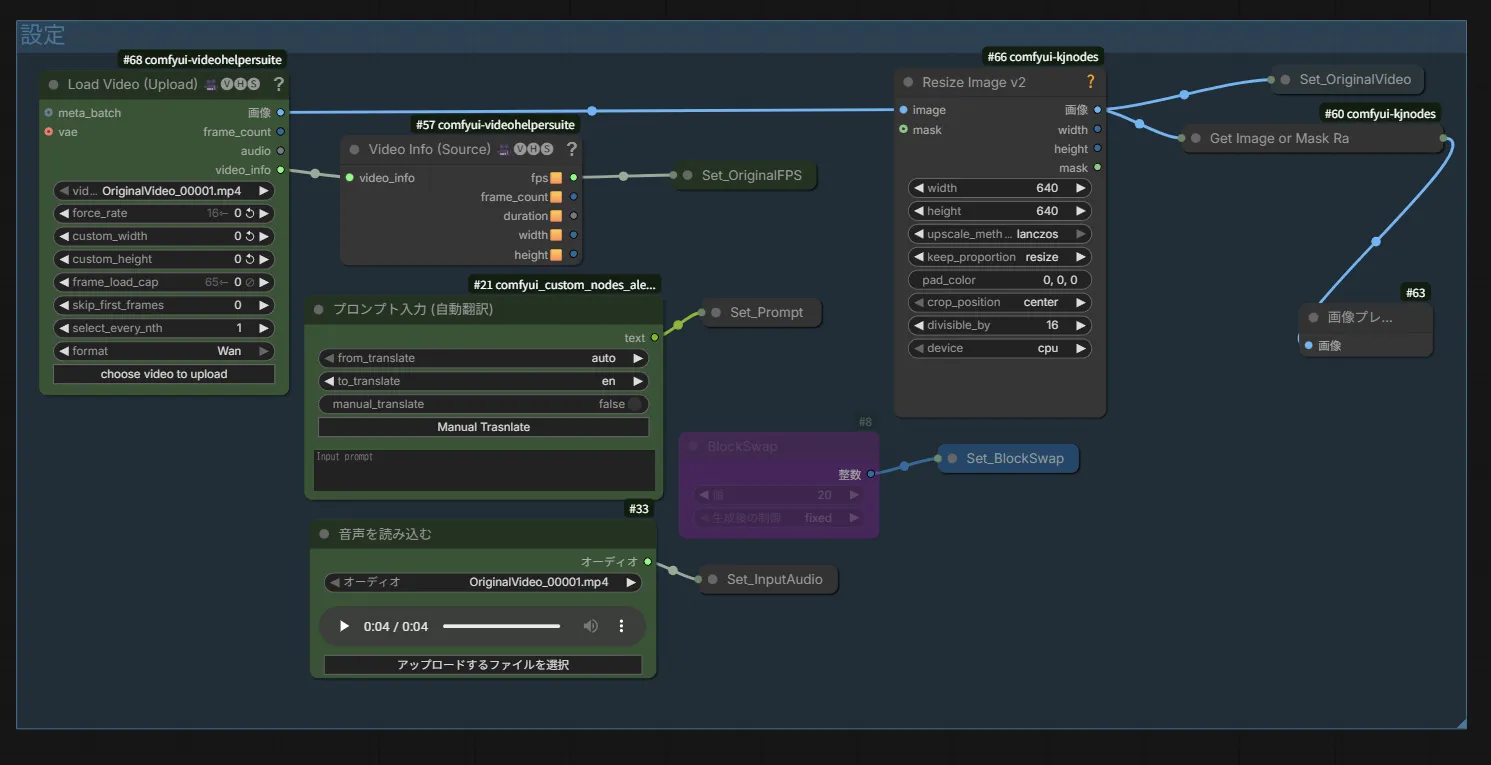
それでは、各ノードについて説明していきます。
Load Video (Upload) : 口パクにしたい動画を読み込みます。「choose video to upload」ボタンを押して動画を選択できます。
音声を読み込む : ここで音声を読み込みます。声のみ収録されたファイルが好ましいですが、ボーカル分離用のノードを使っているので、BGMありでも問題ありません。
プロンプト入力 (自動翻訳) : プロンプト入力用のノードです。自動翻訳されるので日本語で入力しても問題ありません。また、読み込んだ音声が動画より短い場合、プロンプトを入力しなくても問題なく口パク動画が作成されます。(プロンプトを入れた方が精度が上がるかも?)
BlockSwap : VRAMが足りない場合、このノードのバイパスを解除して使用してください。
Resize Image v2 : 基本的にこのノードは触らなくても良いですが、生成する動画の解像度を変更したい場合は、このノードのwidthとheightの数値を変更してください。数値は両方同じにしてください。
以上がワークフローの説明となります。次に注意点をまとめたので必要であれば確認してください。
注意点
注意点が何点かあります。
読み込む動画の解像度は出来るだけ高い方が良いです。低い解像度の動画の場合うまく口パクになりません。
声のみのファイルを読み込んだ時に、生成された動画の音声が所々飛んでいる場合は「結果」グループにある「Video Combine」ノードのaudio入力に繋がっているノードを「Get_InputAudio」に変更してください。
以上が、このワークフローを使用する際の注意点となります。
スポンサーリンク
生成結果
それでは、実際にこのワークフローで口パク動画を作っていきます。使用する動画は前回の【動画生成AI】Wan2.2のモデルはこれだけでOK!NSFW対応のWan2.2モデルの導入方法とワークフロー配布【Wan2.2】のワークフローで作成した以下の動画を使用します。
こちらの動画を約4倍にアップしケールし、フレームレート補間でFPSを60にした動画を読み込んで口パクさせていきます。
使用した音声は「あみたろの声素材工房(https://amitaro.net/)」よりお借りします。
プロンプトは何も入力せずに実行した結果が以下の動画です。
後半少しカクついていますが、ちゃんと口パク出来ていますね!また、この時少し設定を間違えてしまい元動画より秒数が短くなってしまいましたが、配布したワークフローでは修正済みなので安心してください。
後半のカクつきはシード値を変えて再生成したら無くなったので、この辺りはガチャですね。
最後に
これで声を付けても違和感の少ない動画を作成出来るようになりました。
これからは1枚絵だけでなく、動画を用いた作品が増えてくるかもしれませんね。
それでは!



コメント