

FLUX.1 Kontextをローカルで動かすモデルFlux1-Kontext-Devが配布されました。
今回は、そんなFlux.1 Kontext Devをローカルで動かす方法と、様々な使い方を紹介していきます。
ローカル環境はComfyUIを使用します。また、Flux.1 Kontext Dev用のワークフローも配布するので、よければ使ってください。
まず、動かす方法を説明する前に、Flux.1 Kontextについて簡単に説明していきます。
Flux.1 Kontextは画像を編集することが可能な画像生成モデルです。
例えば、背景を変えたい場合は、プロンプトに「背景を〇〇にする」というように入力し、描かれている人物の表情を変えたい場合は「表情を〇〇にする」という風に入力するとその通りに変更された画像が生成されるという訳です。
それでは、Flux.1 Kontext Devの導入方法を解説していきます。
Flux.1 Kontext Devの導入
必要モデルのダウンロード
まずはFlux.1 Kontext Devのモデルをダウンロードします。
以下の2つの内どちらか1つをダウンロードします。
flux1-kontext-dev.safetensors (オリジナル版)
flux1-dev-kontext_fp8_scaled.safetensors (FP8版)
オリジナル版はVRAMが32GB、FP8版は16GB必要です。
ダウンロードしたモデルは「ComfyUI/models/diffusion_models」フォルダへ保存します。
次にテキストエンコーダーをダウンロードします。
テキストエンコーダーは以下の2つをダウンロードします。
clip_l.safetensors
t5xxl_fp16.safetensors
保存場所は「ComfyUI/models/text_encoders」フォルダです。
最後にVAEをダウンロードします。
ae.safetensors
保存場所は「ComfyUI/models/vae」フォルダです。
必要カスタムノード
続きまして、この記事にて配布するワークフローで使用しているカスタムノードを紹介します。
配布ワークフローを使用する場合は導入してください。
ComfyUI-KJNodes
ComfyUI_Custom_Nodes_AlekPet
AlekPetというカスタムノードは翻訳用のノードが追加されるカスタムノードで、英語での自然言語をプロンプトとして扱う際に役立ちます。
翻訳用のノードが無い場合、ブラウザなどで翻訳ツールを使用して日本語を英語に翻訳し、それをコピペして入力しますが、このカスタムノードを入れることで、日本語で入力したものが英語に自動的に翻訳され、それがプロンプトとして反映されます。
ワークフロー配布

上記の.jsonファイルをダウンロードし、ComfyUIで読み込むだけで使用できます。
配布ワークフローの説明
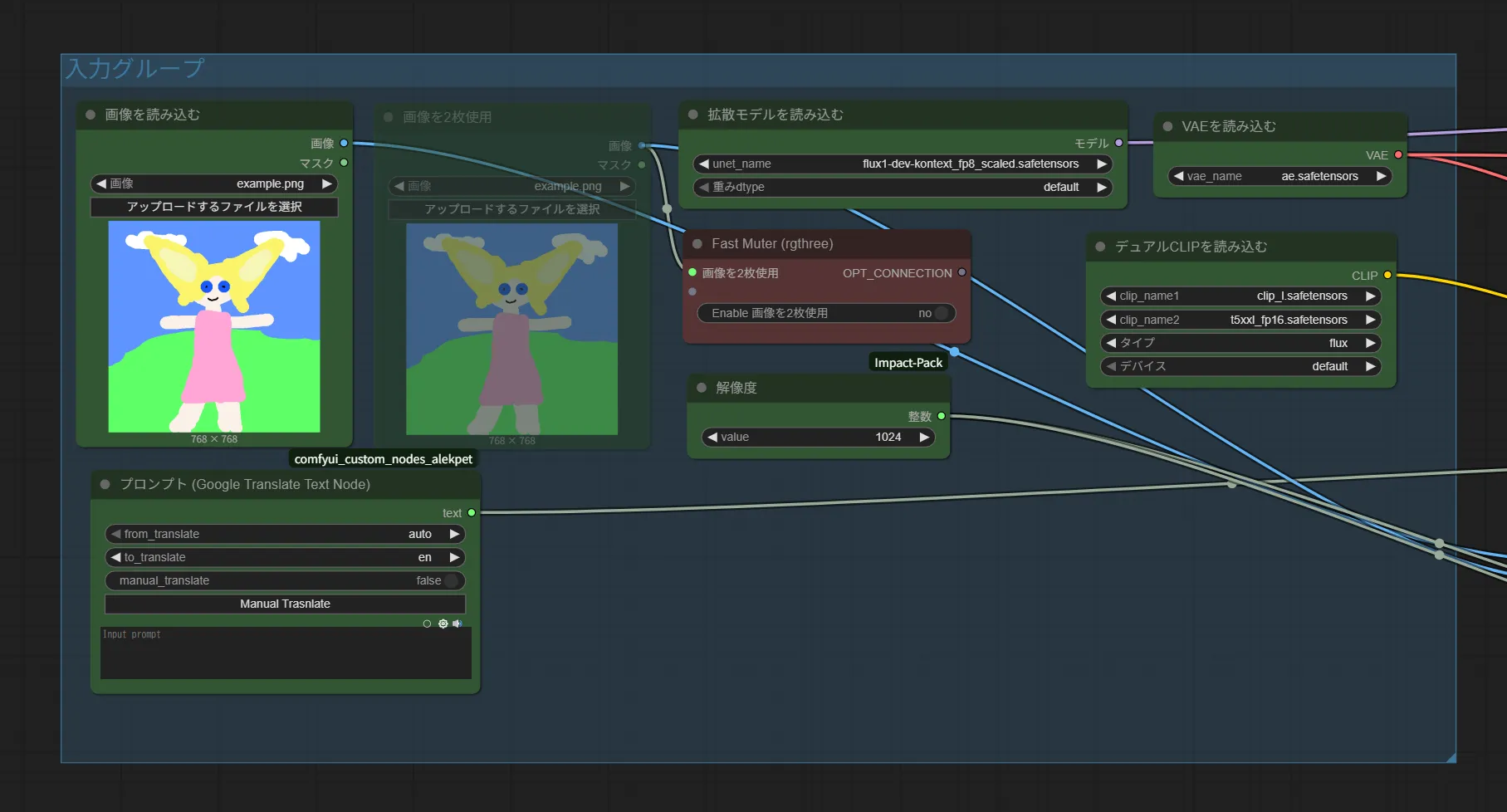
説明といっても、基本的には入力グループに配置してあるノードしか操作しません。
また、操作するノードも基本的には画像を読み込む、画像を2枚使用、プロンプト (Google Translate Text Node)、解像度、Fast Muterの5つのノードだけです。
それぞれのノードについて説明していきます。
・画像を読み込む
このノードに編集したい画像を読み込ませます。
・画像を2枚使用
画像を2枚使う場合は、こちらにも画像を指定してください。
・プロンプト (Google Translate Text Node)
このノードは日本語で入力したプロンプトを自動で英語へ翻訳してくれます。
Flux Kontextでは英語での自然言語で指示を出すので、このノードを使えば楽にプロンプトを入力できます。
・解像度
読み込んだ画像をリサイズする際の長辺のサイズを決めます。
・FastMuter
画像を2枚使用するかどうかを選択できます。画像を2枚使用する場合は、画像を2枚使用ノードに画像を指定して、このノードの画像を2枚使用をONにしてください。
これだけです。
これでFlux.1 Kontext Devをローカルで動かす事が可能になりました。
次は、Flux.1 Kontext Devを使用して読み込んだ画像に変更を加えていきたいと思います。
スポンサーリンク
Flux.1 Kontext Devを使ってみる
元イラスト
元となる画像は以下の2枚を使用します。


左の画像を1枚目、右のを2枚目として読み込みます。
背景を変更する
まずは背景を白にします。
プロンプトは以下で生成しました。
背景を白にします生成された画像が以下となります。

ちゃんと背景が白に変わっているので成功ですね。
次は背景を海に変更してみます。
プロンプトは以下。
背景を海にします 生成された画像が以下。

こちらも成功ですね。プロンプトを変えれば様々な背景にすることが可能です。
衣装を変更する
次は衣装を変えてみましょう。今回は麦わら帽子を外してみます。
プロンプトは以下で生成してみます。
麦わら帽子を外します生成された画像が以下。

ちゃんと麦わら帽子が外れていますね。
表情を変更する
それでは次は表情を変えてみたいと思います。
プロンプトは以下でやります。
目を閉じて口を開けます生成された画像が以下。

ちゃんとプロンプト通りに変わりましたね。
画像を2枚使う
それでは、次は画像を2枚使った生成を行います。
1枚目のキャラと2枚目のキャラが抱き合うような画像を生成してみようと思うので、プロンプトは以下でいきます。
男性と女性が抱き合います生成された画像が以下です。

背景の異なる画像を使用してもちゃんと背景も合わせてくれてますね。少し手が怪しいですが、ここは通常の画像生成と同じようにガチャか自力で修正する必要があります。
もう一枚試してみます。今度は男性キャラが着用しているサングラスを、女性キャラに付け替えてみます。
プロンプトは以下で試してみます。
麦わら帽子を被った白いドレスを着た女性が、男性からサングラスを取って自分に着けます。男性はサングラスを外します。生成された画像が以下。

サングラスを付け変えることに成功しました。
このモデルはどれくらい使えるか
表情差分や衣装差分、ポーズ差分など一通り作成することは出来ますが、プロンプトの効きが悪い内容のもあったり、イラストの画風によっては馴染まない事もあるので、本格的な差分作成の場合は、従来の画像生成モデルとControlNetやインペイントを組み合わせる方が良いと感じました。
スポンサーリンク
最後に
出せない内容もあるので少し使い勝手が悪いですが、2枚の画像を1枚の画像にするなど面白い使い方はあるので、派生モデルLoRAなどが充実すれば化けそうですね。
それでは!


コメント