
今回は、AIボイスチェンジャーの「RVC」の記事です。
この記事では、RVCの学習から使い方までを解説します。
RVCとは
学習などの解説の前に、RVCについて簡単に説明します。
RVCはAIにより声を変換するボイスチェンジャーです。名探偵コナンに出てくる「蝶ネクタイ型変声機」のように、自分の声を好きなアニメキャラなどの声に変換することが出来ます。
少し前にバ美肉が流行ったときに、ボイスチェンジャーを用いて女声にする方法などが話題になりましたが、なんの訓練もなしにその声を維持するのは大変です。ですが、事前に録音しておいた女声のデータをRVCで学習させれば、常にその声を出し続けることも出来ます。
また、AIボイスチェンジャーというとSeiren VoiceやMMVCが思い当たると思いますが、Seiren Voiceはリアルアイム変換が出来ず、MMVCは学習がめんどうという欠点があります。
しかし、今回紹介するRVCは学習が簡単でリアルタイムで声を変換することができます。両者の良いとこ取りのような存在です。
RVCとMMVCの学習はどう違うのか、それは自分の声のデータの有無です。
MMVCでは変換したい声のデータだけでなく、自分の声のデータも必要になります。
この声を用意するのが一番めんどくさいです。具体的に言うと、変換したい声のデータと同じセリフを喋っているデータを用意しないといけません。
つまり、100個の学習データを用意したら、自分の声のデータも100個用意しないといけません。
しかし、RVCの学習では自分の声は必要ありません。変換したい声のデータのみで学習できます。
しかもクオリティも高いです。
それでは、まずは学習のやり方から解説していきます。
スポンサーリンク
学習データの準備
学習データは、自分のなりたい声を.wav形式で用意してください。
学習データの注意点ですが、BGMなどは含めずに、声だけのものを用意してください。そうしないとクオリティが低くなってしまいます。
もし用意したデータに声以外の音声が含まれている場合は、BGM除去ツールやノイズ除去ツールなどを使って音声を分離してください。
この記事では、MMVC用に配布されているずんだもんの音声を使用します。
ダウンロードリンクは以下のページから下にスクロールしたところにあります。
https://github.com/isletennos/MMVC_Trainer
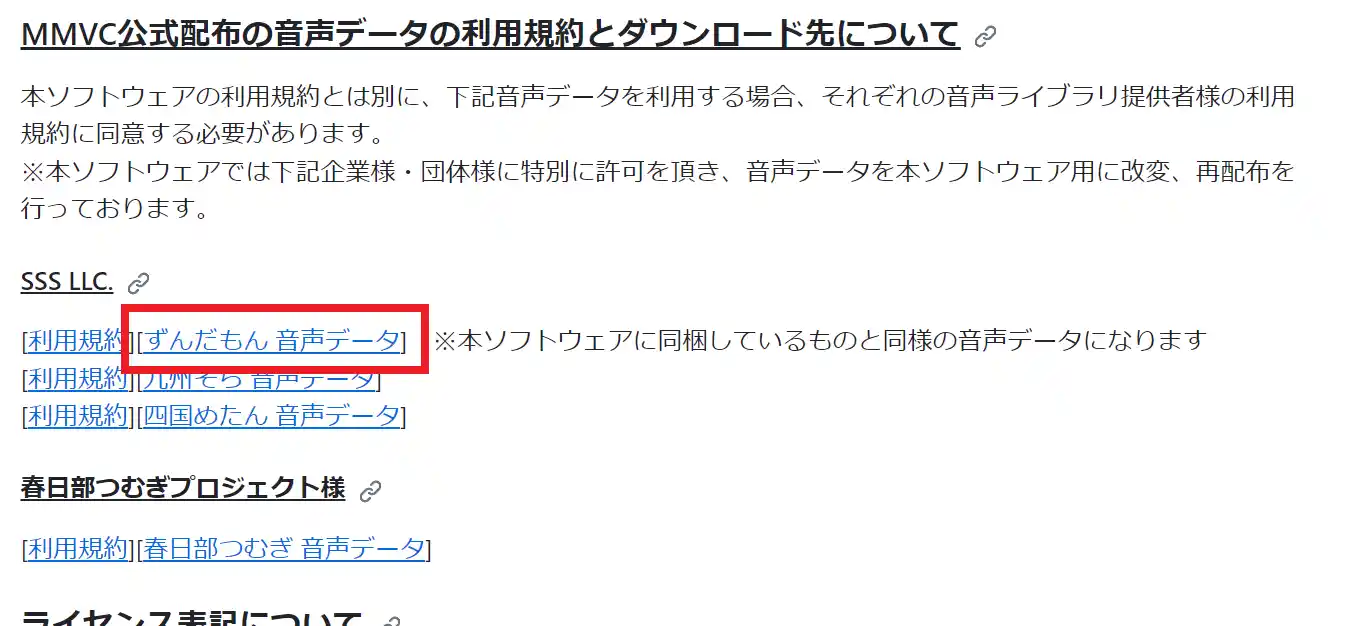
とりあえず学習をしてみたいという方は、上記のリンクからずんだもん音声をダウンロードしましょう。
ダウンロード出来たら解凍し、中にある「wav」フォルダを取り出します。
このフォルダの中に入ってる音声データが学習データとなります。
これで学習データの準備は完了です。
RVCのインストールと起動
まずは学習に必要なツールを導入します。
1.RVCのインストール
1.以下のURLへ移動する。
https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main
2.「RVC-beta.7z」をダウンロードする
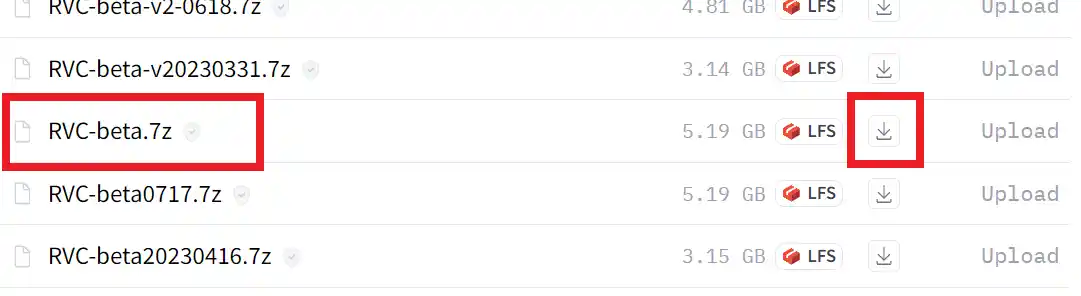
3.ダウンロードした.7zファイルを解凍する。
.7zを解凍するソフトが入っていない場合7-Zipをインストールしましょう。
2.RVCの起動
先ほど解凍したフォルダを開いたら「go-web.bat」を起動します。
すると、cmd画面が立ち上がり、準備が整うと自動でブラウザが開かれます。環境によっては時間がかかる場合もあるのでcmd画面は閉じずに待ちましょう。
起動すると以下のような画面が表示されます。
これで起動は完了です。
それでは学習させていきましょう。
RVCの学習を始める
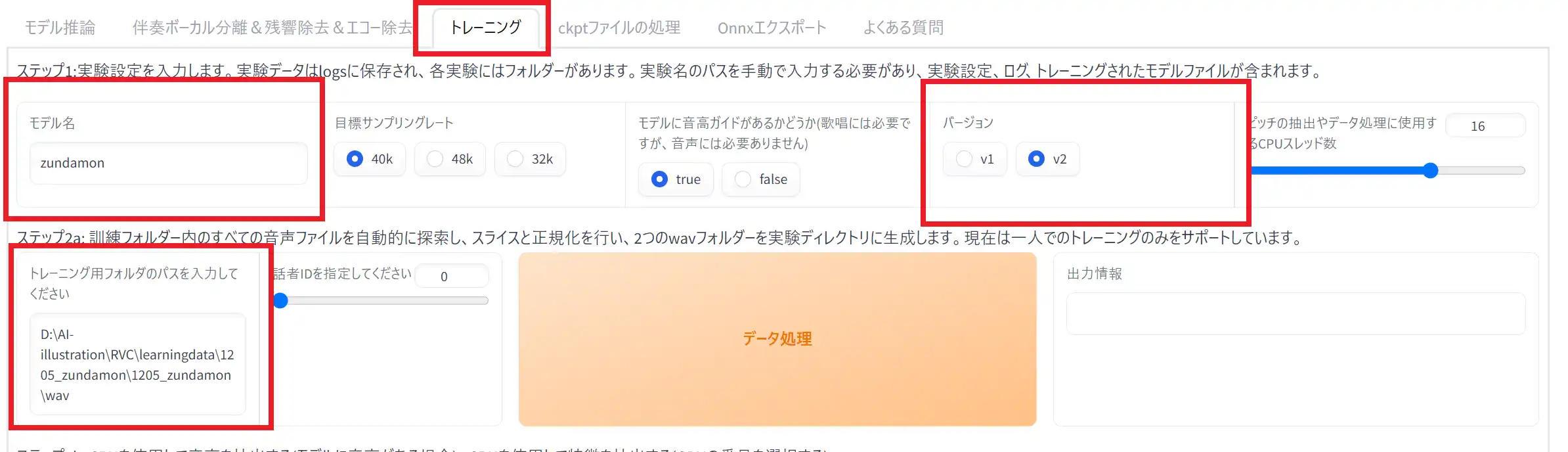
まずは「トレーニング」タブを開きます。
開いたら学習用の設定を行っていきます。
①モデル名
この項目は出力されるモデル名を決めます。自由に決めてください。
②バージョン
「v2」の方が精度が良いようなので、v2を選択します。
③トレーニング用フォルダのパスを入力してください
学習用の.wavファイルが入っているフォルダまでのパスを指定してください。
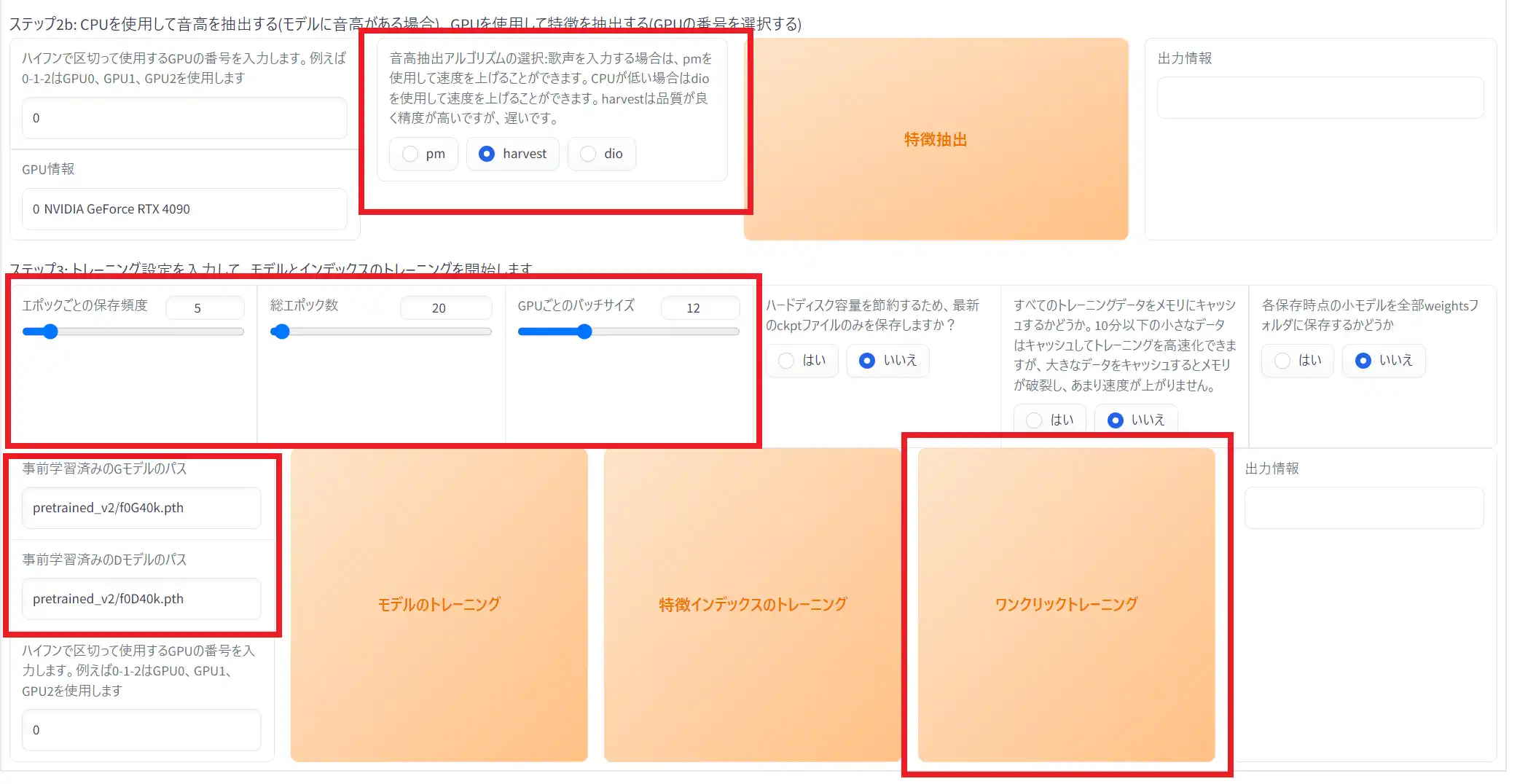
④音高抽出アルゴリズムの選択
基本的には”harvest“で大丈夫です。
⑤エポックごとの保存頻度
この項目では学習途中でモデルを保存する間隔を設定できます。
5と入力すると、5Epochの学習が終了するたびに保存されます。
⑥総エポック数
この項目は学習を何回繰り返すかの設定です。この項目で設定した数だけ学習が繰り返されます。
少なすぎると学習不足でうまく声を変換できませんが、学習しすぎても過学習となってしまう為、うまく調節していきましょう。
⑦GPUごとのバッチサイズ
使用しているGPUと相談して決めましょう。数値が高い方が良い結果になるらしいです。
⑧事前学習済みのGモデルのパス/事前学習済みのDモデルのパス
最初の学習ではデフォルトで良いです。もし、今回学習した結果から学習を再開したいとなった場合は、出力されるGモデルとDモデルを指定します。
⑨ワンクリックトレーニング
設定が済んだらこの項目をクリックして学習を開始できます。
学習を開始すると「出力情報」の欄にログが表示され、学習が終わると「全工程が完了!」と表示されます。
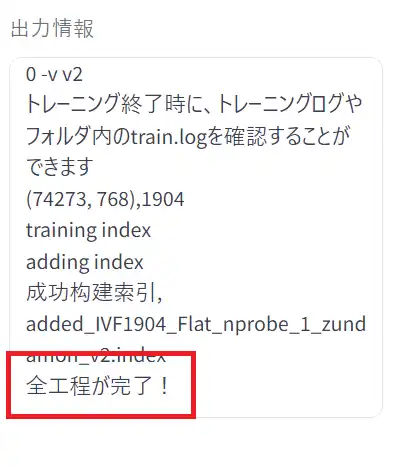
学習データの保存場所
学習し終わったファイルは以下の2か所に保存されています。
①”RVC-beta\RVC-beta0717\weights“
②”RVC-beta\RVC-beta0717\logs\〇〇〇〇“
に保存されています。
ボイスチェンジャーとして使うときに必要になるファイルは、①のフォルダに入っている「〇〇〇〇.pth」ファイルと②のフォルダに入っている「added_IVF1904_Flat_nprobe_1_〇〇〇〇_v2.index」ファイルです。
スポンサーリンク
非リアルタイムで声を変えてみよう
まずは非リアルタイムのボイスチェンジャーを行います。
非リアルタイムの場合はこの画面のまま行えます。
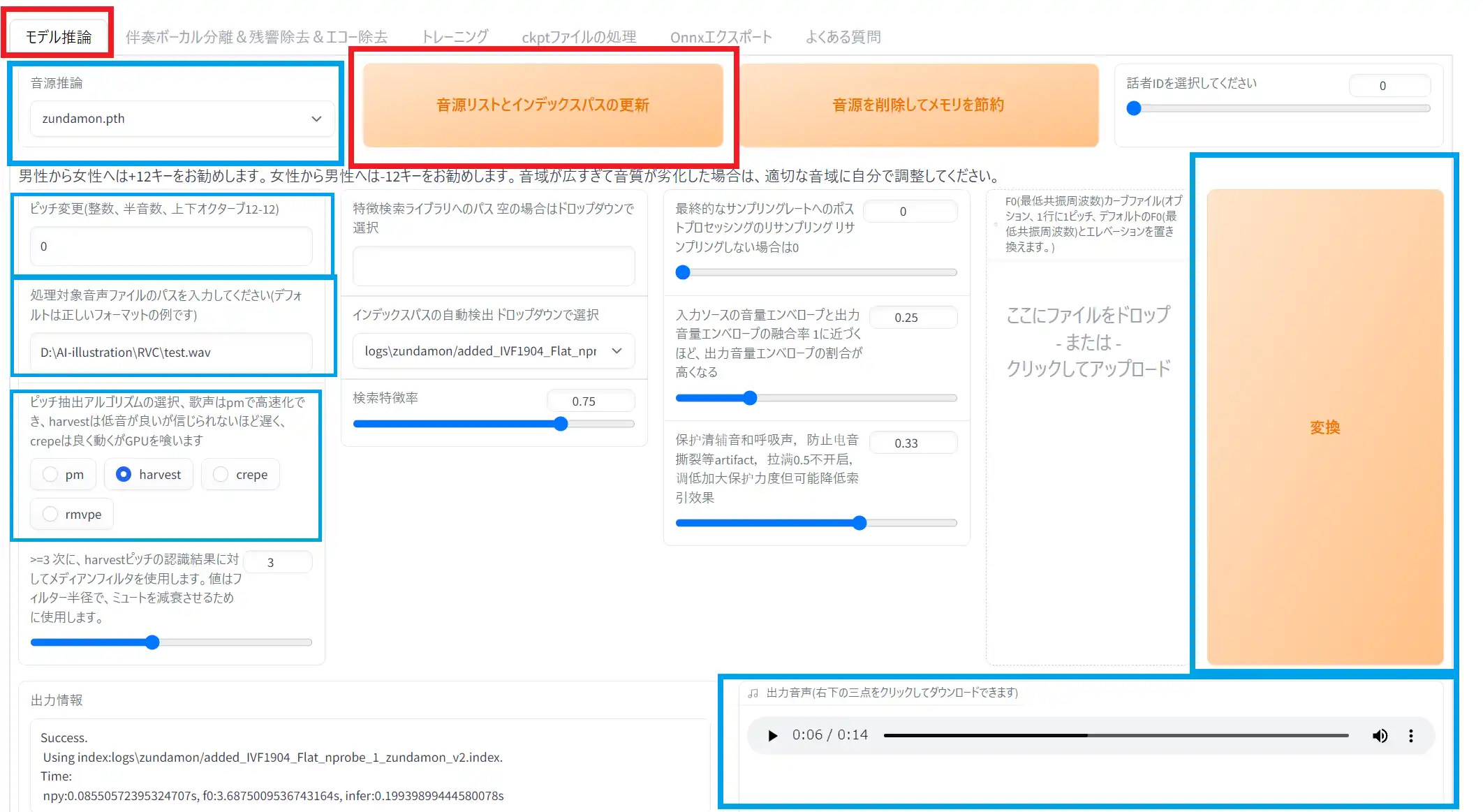
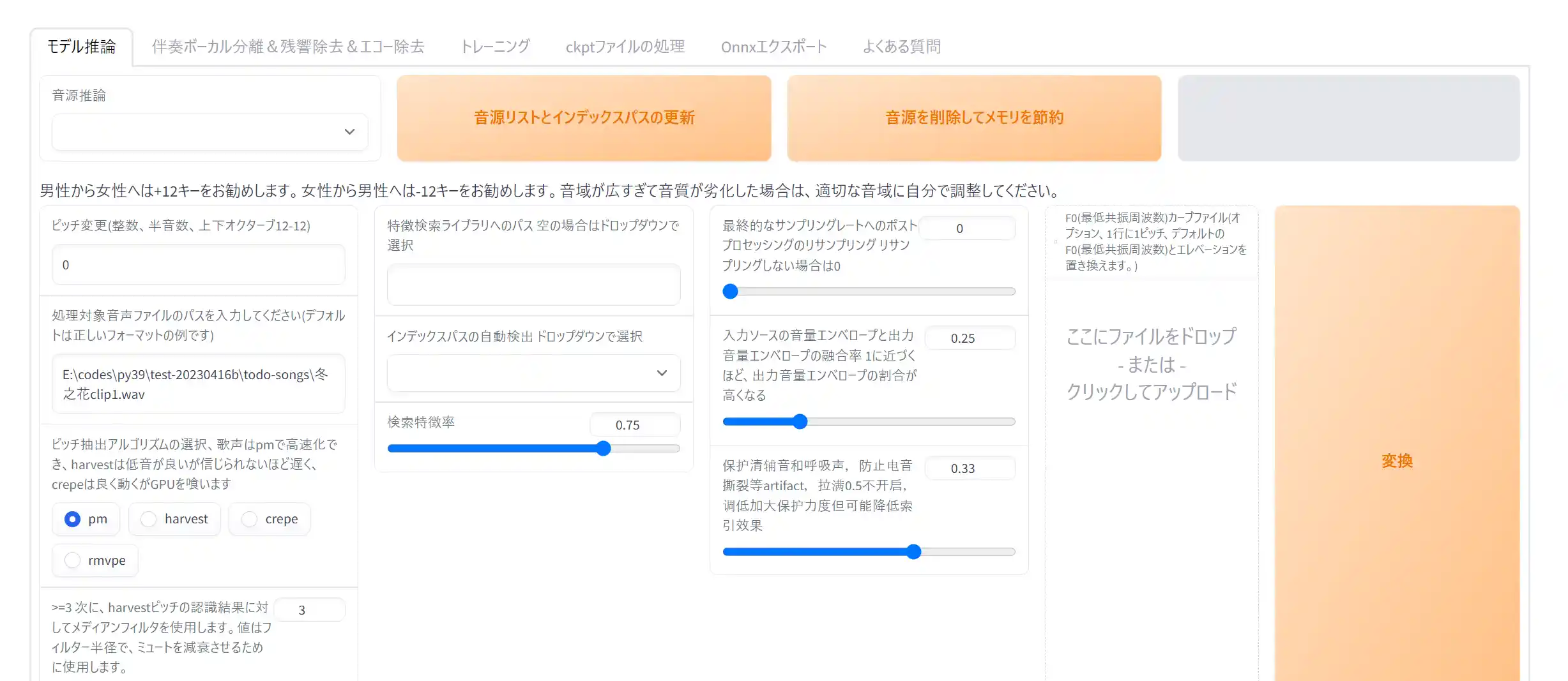
まず「モデル推論」タブを開きます。
①「音源リストとインデックスパスの更新」ボタンを押す
学習が終わってすぐ試す場合はこのボタンを押してください。そうしないと学習済みのファイルが表示されません。
②音源推論
クリックすると学習済みのモデルが一覧で表示されます。変換したい声のモデルを選択しましょう。
③ピッチ変更
変換がうまくいかない場合や、男声から女声、女声から男声に変換する場合は設定を変えましょう。男声から女声の場合は+12、女声から男声なら-12がおすすめです。
④処理対象音声ファイルパスを入力
ここに変換したい音声ファイルのパスを入れます。自分の声を録音したものでも良いですし、喋らせたいセリフの音源ファイル、なんでも良いです。
擬音の音源ファイルを入れてみても面白いかもしれません。
⑤ピッチ抽出アルゴリズム
学習時に選択したものを選択します。今回は”harvest“です。
あとは「変換」ボタンを押します。
少し待てば変換された音声が表示されるので、再生ボタンを押して聞いてみましょう。
うまく変換できていない場合、学習不足などの可能性があるのでEpoch数を上げるなどして再学習しましょう。
また、処理対象音声ファイルに、ボーカル抽出した音声ファイルを使用することで、歌わせることが出来ます。
これで非リアルタイムでのボイスチェンジが出来るようになりました。
次はリアルタイムでのボイスチェンジです。
リアルタイムで声を変えてみよう
1.VC Clientのインストール
リアルタイムで変換するには「VC Client」というソフトを使います。
RVCフォルダの中にもリアルタイムで変換する為のものと思われるbatファイルがありますが、VC Clientの方が日本語での情報が多く、何かエラーが起こった時に解決しやすいので、こちらを使用します。
ダウンロードは上記のリンクを開き、下の方にスクロールしたところにリンクがあるので、そこからダウンロードできます。
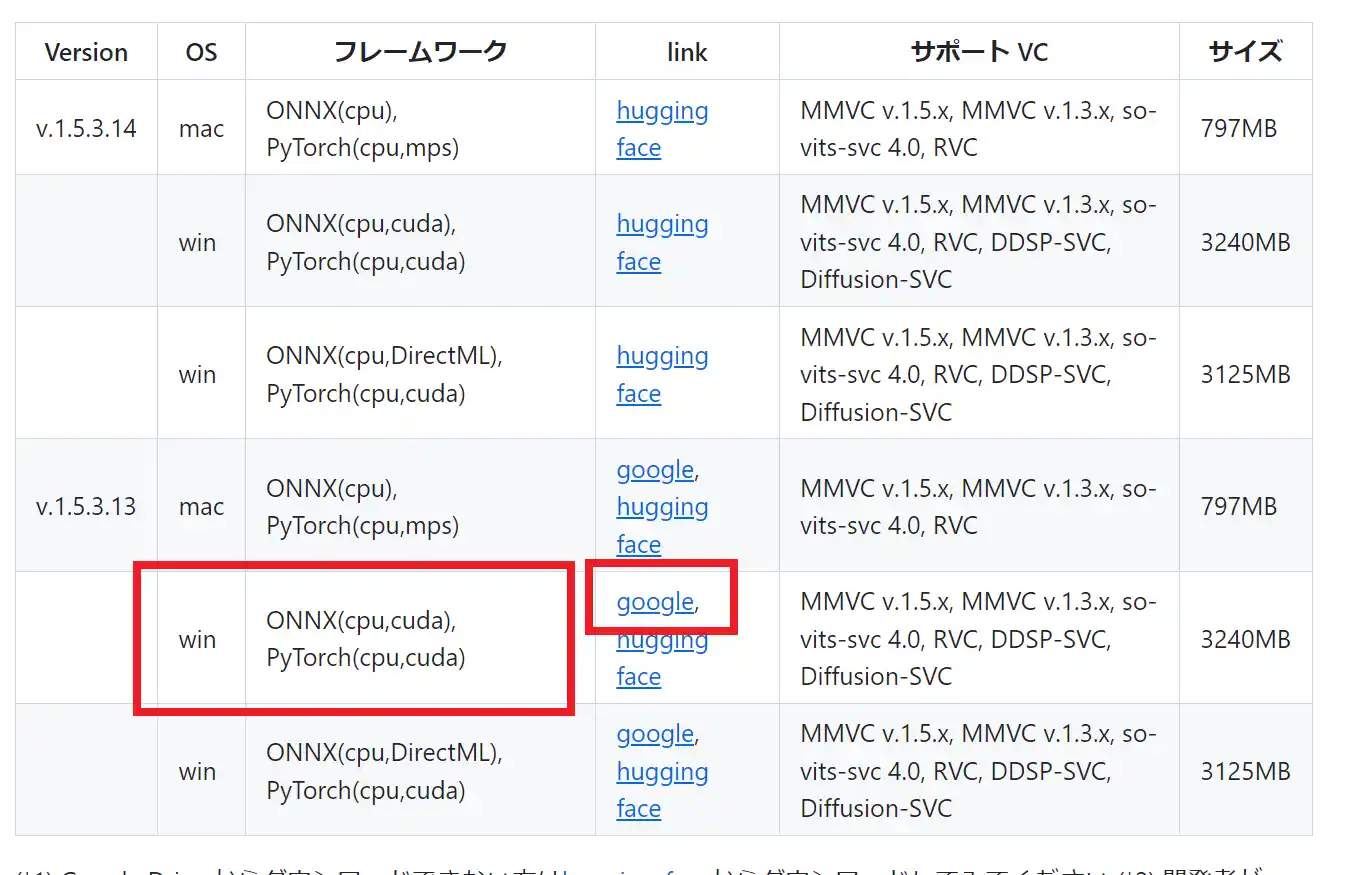
windows用でONNX(cpu,cuda)と書かれたものをダウンロードします。
ダウンロードはgoogleとhugging faceがありますが、googleの方が簡単なのでここではgoogleを選択します。
ダウンロードが終わったら解凍します。
2.VC Clientの起動
解凍したフォルダに入っている「start_http.bat」を起動します。

似た名前の「start_https.bat」がありますが、こちらではないので注意してください。
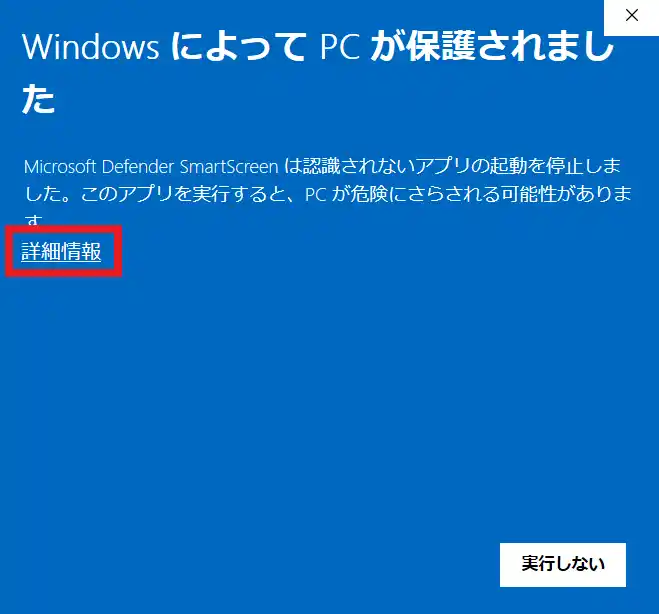
初回起動時に下記のような警告が出てくると思いますが、「詳細情報」をクリックし、「実行」を押します。
また、ファイアウォールの警告も出ると思いますが、こちらも「アクセスを許可」をクリックしてください。
cmdが開き、準備が出来ると自動でVC Clientが立ち上がります。
まずは、今回学習したモデルを追加していきます。
3.学習モデルの追加
上部に現在使用できるモデル一覧があります。その右下にある「編集」をクリックします。
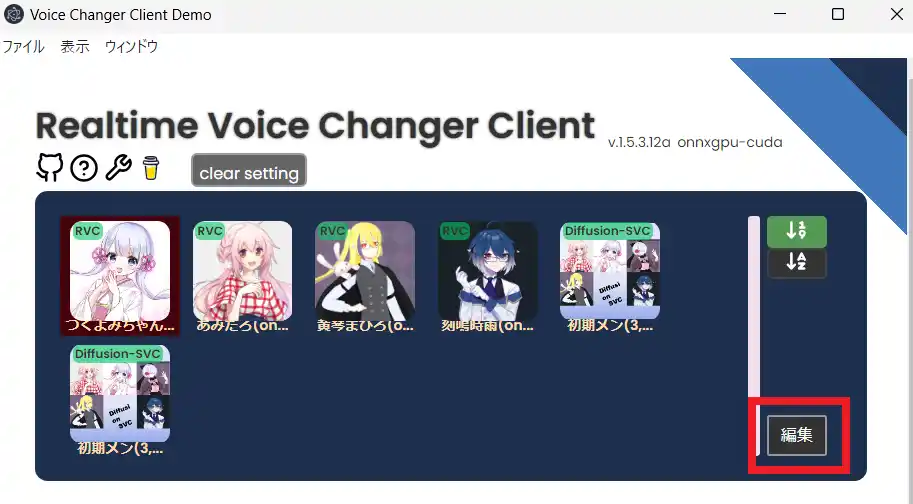
次に、”blank“と書かれた場所の「アップロード」をクリックします。
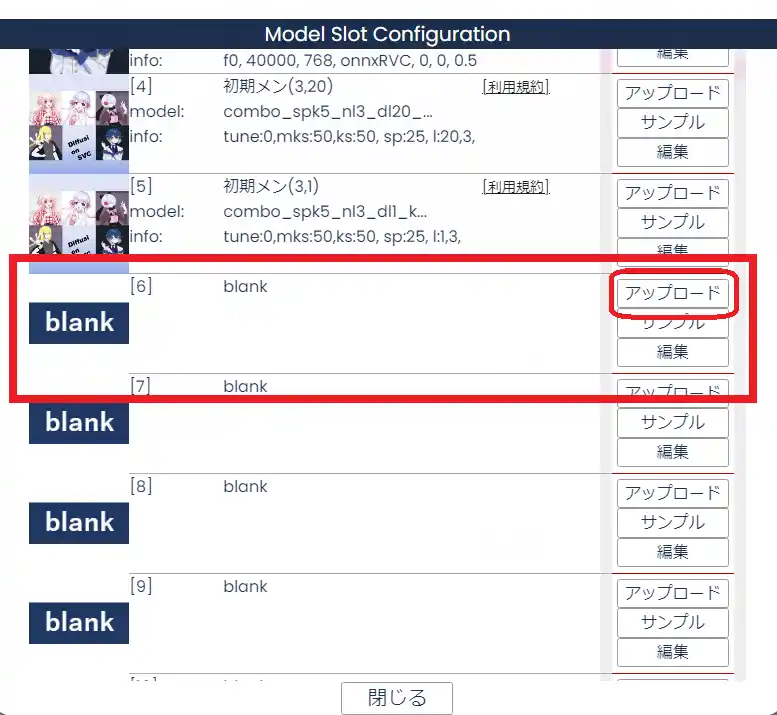
次に以下の項目を設定していきます。
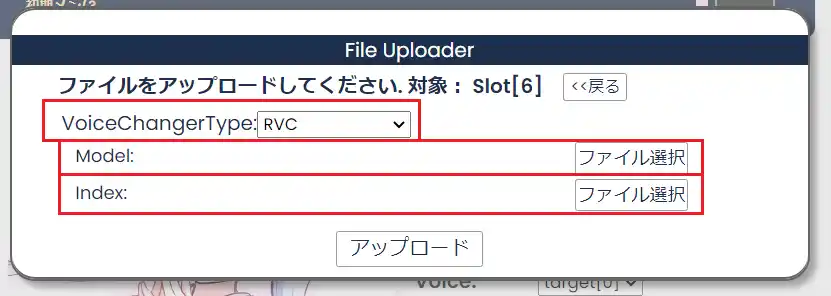
①VoiceChangerType
この項目は”RVC“を選択してください。
②Model:
この項目では、学習モデルを選択します。以下のフォルダに入っている「〇〇〇〇.pth」を選択してください。
“RVC-beta\RVC-beta0717\weights“
③Index:
こちらの項目には以下のフォルダに入っている「added_IVF1904_Flat_nprobe_1_〇〇〇〇_v2.index」ファイルを指定します。
“RVC-beta\RVC-beta0717\logs\〇〇〇〇“
終わったら「アップロード」をクリックします。
これで追加が完了しました。

この状態ではアイコンなどが設定されておらず、数を増やしたときに分かりづらくなってしまいます。
アイコンの設定は、blackと書かれた部分をダブルクリックすることで変更することが出来ます。
スロット名の変更は、上記の画像の青枠で囲った部分をクリックすることで行うことが出来ます。
終わったら「閉じる」ボタンを押しましょう。
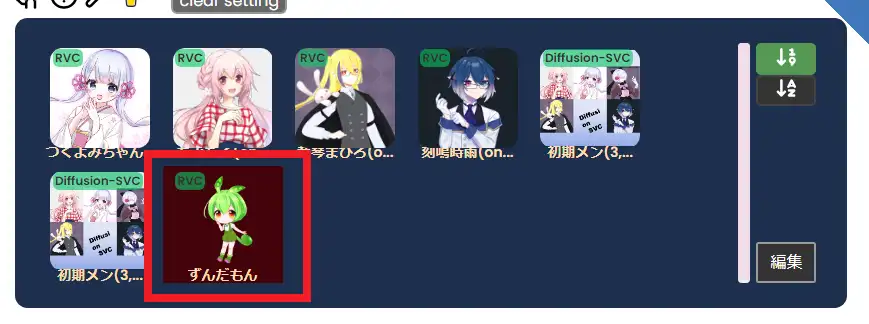
一覧に追加したモデルが表示されます。
これでモデルの追加は完了です。
次はいよいよリアルタイムボイスチェンジャーの為の設定をしていきます。
4.各種設定
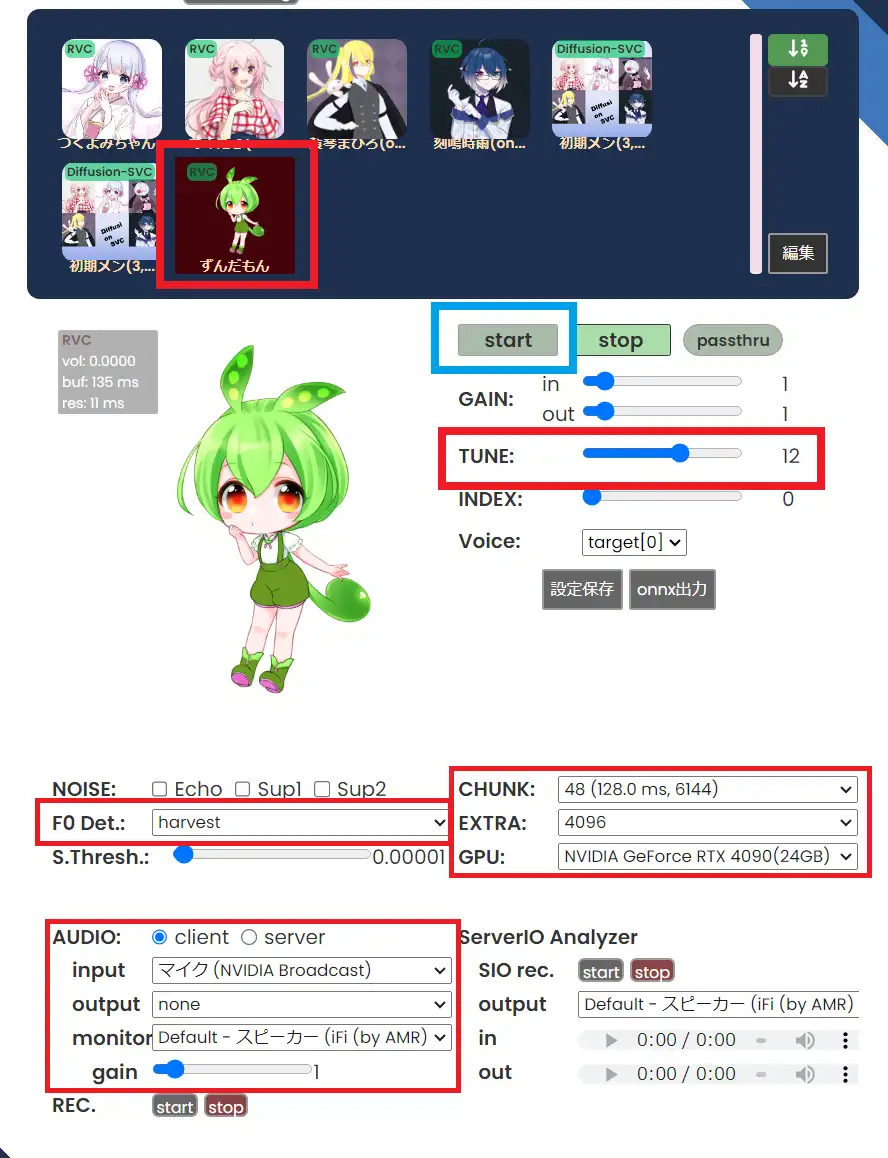
まずは、変更したい声をモデル一覧から選択します。
①TUNE
この項目は男声から女声に変える場合は上げる、女声から男声なら下げると良いです。どれくらい下げるかは自分の声によるので、うまく調整してください。
②F0 det…
変えて試してみましたが、なにが変わったのかよく分かりませんでした。とりあえず学習時に選択していた”harvest“を指定しています。
③CHUNK:
下げると遅延が少なくなりますが、クオリティが落ちます。上げるとクオリティは上がりますが、遅延が大きくなります。デフォルトの48でも問題ないと思います。
④EXTRA
変えてみたいけどよく分かりませんでした。デフォルトのままで良いと思います。
⑤GPU
この項目は、使用しているGPUかCPUを選べますが、基本的に使用しているGPUを選びましょう。CPUは遅延が大きくてリアルタイムボイスチェンジャーとして使い物になりません。
AUDIOの項目は、使用している環境に合わせて設定してください。
ここまでの設定が終わったら青枠で囲ってある「start」ボタンをクリックしましょう。これでボイスチェンジャー機能がONになります。
5.モデル一覧からいらないモデルを削除する方法
もう使わないモデルを、モデル一覧から削除する場合は、以下のパスにある該当するフォルダを削除するだけです。
“MMVCServerSIO_win_onnxgpu-cuda_v.1.5.3.12a\MMVCServerSIO\model_dir”
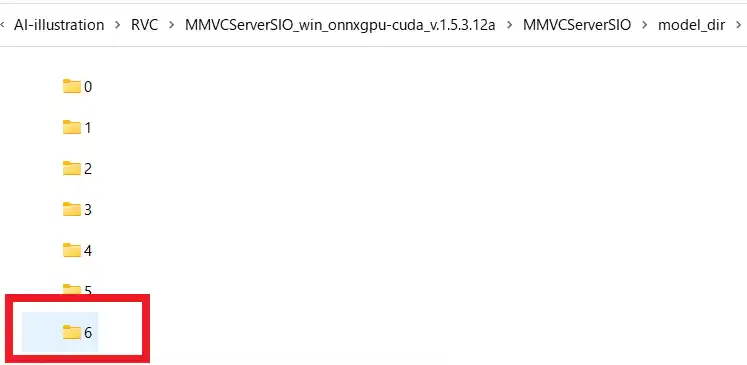
今回は追加したずんだもんのモデルはスロット6に追加したので、「6」と書かれたフォルダを削除すればモデル一覧からも消すことが出来ます。
最後に
これで好きなキャラにあんなセリフやこんなセリフを言わせてみたり、歌わせたりすることが出来ますね!
それでは!

コメント
モデル一覧からいらないモデルを削除する方法がわからなかったので助かりました!