
LoRA学習時に設定値をどうすればいいか分からない、という方向けにプリセットファイルを配布します。
学習データによってはうまく学習できない場合もあります。
今回配布するプリセットはアニメ系でしか試していないため、リアル系でもうまく学習できるかは分かりません。
SD1.5系のモデルでもSDXL系のモデルでも使えます。
LoRA作成時の注意点ですが、SDXL用のLoRAを作成する場合はmax resolutionを「1024,1024」以上に設定してください。学習用の画像のサイズも1024×1024以上のものが望ましいです。
また、このプリセットはkohya_ss_GUIでの使用を想定しています。
kohya_ss_GUIの導入、使用方法は以下の記事で解説しています。
【AIイラスト】kohya_ss GUIを導入してローカルでLoRA学習をしよう【stable diffusion】
スポンサーリンク
プリセット配布
キャラクター/衣装/ポーズ
キャラクターLoRAと衣装LoRA、ポーズLoRA用のプリセットファイルです。

SDXL用 キャラクター
SDXL用だとこちらの方が良いような気がします。が、気のせいかもしれません。両方試して良かった方を使うのが良いでしょう。
また、確認していないので確証はないですが、衣装やポーズにも使えると思います。

画風
画風LoRA学習用のプリセットファイルです。SDXL用もこのプリセットで出来ました。
それぞれ違う設定です。うまくいかないな、と思ったらプリセットを変えて作成してみてください。
個人的には、StyleLoraLearning_2のプリセットをよく使っています。SDXL用でもStyleLoraLearning_2を使う事が多いです。



使い方
1.プリセットの保存場所
まずは、ダウンロードしたプリセットファイルの保存場所です。
ダウンロードしたプリセットファイルを以下の場所に保存してください。
kohya_ss\presets\lora\user_presetsこれでプリセットの読み込みが出来るようになります。
2.プリセットの読み込み
プリセットの読み込みは簡単で、以下の手順で行えます。
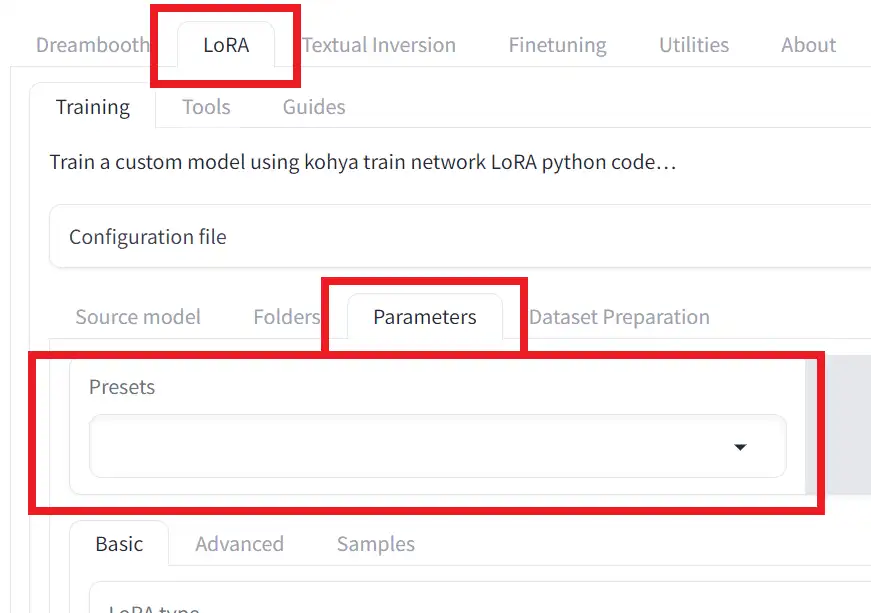
① LoRAタブを開く
②Parametersタブを開く
③Presets一覧から使いたいプリセットを選択する
これだけです。
あとは学習用フォルダや学習用モデル、Epoch数などを設定して使ってください。
スポンサーリンク
実際にうまくいった学習データ枚数とSTEP数
ここからは備忘録的な意味合いで書くので、あまり鵜呑みにしないてください。
私が上記のプリセットで学習させた際に、そこそこうまく出来た時の学習用素材の枚数や繰り返し回数、STEP数を記載しておきます。
・キャラLoRA
学習用素材の枚数 : 100枚以下 (50枚以下でもそこそこの精度だった)
繰り返し回数 : 1
STEP数 : 2000~5000
・衣装LoRA
学習用素材の枚数 : 100枚以下 (50枚以下でもそこそこの精度だった)
繰り返し回数 : 1
STEP数 : 2000~5000
・画風LoRA
学習用素材の枚数 : 200枚前後(50枚くらいでも出来るが、多い方が汎用性の高いLoRAが出来る気がする)
STEP数 : 2500~10000 (2000~5000くらいが丁度良いかも)
最後に
この記事で配布しているプリセットは一例なので、学習用データによっては全く効果が出ないか、微調整の必要があります。
また、配布されているLoRAには、設定値などのメタデータが埋め込まれていることが多いので、それを参考にして設定値を決めるのも良いでしょう。
それでは!


コメント
今まで基本的にkohya_ssの標準プリセット「SDXL – LoRA AI_Now ADamW v1.0」、それ以前は「SDXL – LoRA adafactor v1.0」でLORAを自作してきたのですが、こちらの「StyleLoraLearning_1」と「StyleLoraLearning_2」を使ってみたところ、今まで作ってきたものから飛躍的に再現性や忠実度が高いものが作成できまして、驚きの結果でした。満足してしまったのでこの2つしか試していませんが、私も2がお気に入りです
すばらしいプリセットの共有ありがとうございます…!
なぜここまで差があるのか気になりましたので、SD-WebUIのLORA選択ウィンドウで表示されるトンカチスパナマーク押して、StyleLoraLearningで作成したLORAのメタデータを確認しました。すると、Training dataset tagsがみっちり入っていて、対して私が今まで作ったLORAはいつもトリガーワードしか残っていないことに気が付きました
(他のCivitaiで配布されてるクオリティの高いLORAも確認してみたところ、どれもTraining dataset tagsがみっちり入っていました)
これを残すような設定はkohya_ssのどこかにあるのでしょうか
また標準プリセットのadafactor v1.0やADamW v1.0と実行時間を比較すると、StyleLoraLearning_2は4~5倍の時間(※)を要しまして、私の環境になにか問題があるのかちょっと不安に思ったところがあるのですが、管理人様の方でも実行時間に差はあるものなのでしょうか
(なんとなく上記のTraining dataset tagsを残す/残さないと関連性があるような気もしています)
※同じ学習画像フォルダに対する実行で(ADamW v1.0 : 5000STEP : 2~3時間)のところ(StyleLoraLearning2 : 5000STEP : 12~14時間)といった感じです(4070Ti 12GBで実行。いずれの場合もパラメータはSTEP調整のためのbatch countとEpoch以外変更していません)
LORA作成における初歩的な質問をしているような気がしており恐縮なのですが、もしよろしければご教示いただけたらうれしいです
ただ品質にはとても満足していますので、私の環境の問題であろうがなかろうが使い続けようと思います笑
ありがとうございます
タグを適用させるにはCaption file extensionという項目で、用意したキャプションファイルの形式を選択してください。
学習時間については、こちらの環境(RTX4090 24GB)では大きな差はありませんでした。もしかしたら使用しているGPUにより違いが出るのかもしれません。
迅速な返信ありがとうございます!
わ、そんな項目が…!Caption file extensionを指定していなくてもまずまず再現はできていたので、こちらのプリセットを使うまではこういうものかと思っていましたが、今まで学習損失をしていたかもしれません
もしかすると学習時間が短かったのもCaption file extensionを指定していなかったためにプロンプトが読み込まれなかったからということだったのかも…近いうちに検証してみようと思います
最上級GPUすごいです…!
確かにメモリ容量が倍だったりとこれだけ性能差が大きいと実行状況にもかなり差がありそうですね(私の環境ではバッチカウントを1にしていないと学習時間がとんでもないことになるので…笑)