
3/2 ANIMAGINE XL 3.0をベースにした画風LoRA作成時の注意点を追記しました。
1/15 ANIMAGINE XL 3.0の登場で、SDXL用のLoRA学習が活発になりそうだったので、SD1.5系とSDXL系での注意点を追記しました。
前回、paperspaceでLoRA学習を行う方法を書きました。
なので、今回はローカルでLoRA学習を行う方法を書いていきたいと思います。
paperspaceの時とは違い、GUI形式で動かせるのですごく簡単にできると思います。
それでは、まずは環境を構築していきましょう。
キャラ学習用、画風学習用のプリセットを以下の記事で配布しています。
【AIイラスト】画風、キャラ、衣装のLoRA学習用の設定プリセットを配布します【stable diffusion】
1.必要ソフトのインストール
必要ソフトは以下の3つです。
・Python 3.10
・Git
・Visual Studio 2015、2017、2019、および 2022
PythonとGitはstable diffusion web-uiを導入するときにインストールしているので、だいたいの方はインストール済みだと思います。
もしインストールしていなければ、下記の記事でインストール方法を解説しているのでどうぞ。
【AIイラスト】AUTOMATIC1111版 web-uiの導入とおすすめ設定
Visual Studioは以下のリンクから、x64の「https://aka.ms/vs/17/release/vc_redist.x64.exe」と書かれたリンクから「VC_redist.x64.exe」をダウンロードし、インストールしてください。
Visual Studio 2015、2017、2019、および 2022
ただ、私の環境ではVisual Studioはインストールしなくても出来ました。(別件でインストール済みだった?)

2.Kohya’s GUIの導入
1.kohya’s GUIのインストール
それでは、お待ちかね、kohya_ss GUIを導入していきます。
まずは、kohya_ss GUIをインストールするフォルダを作成してください。
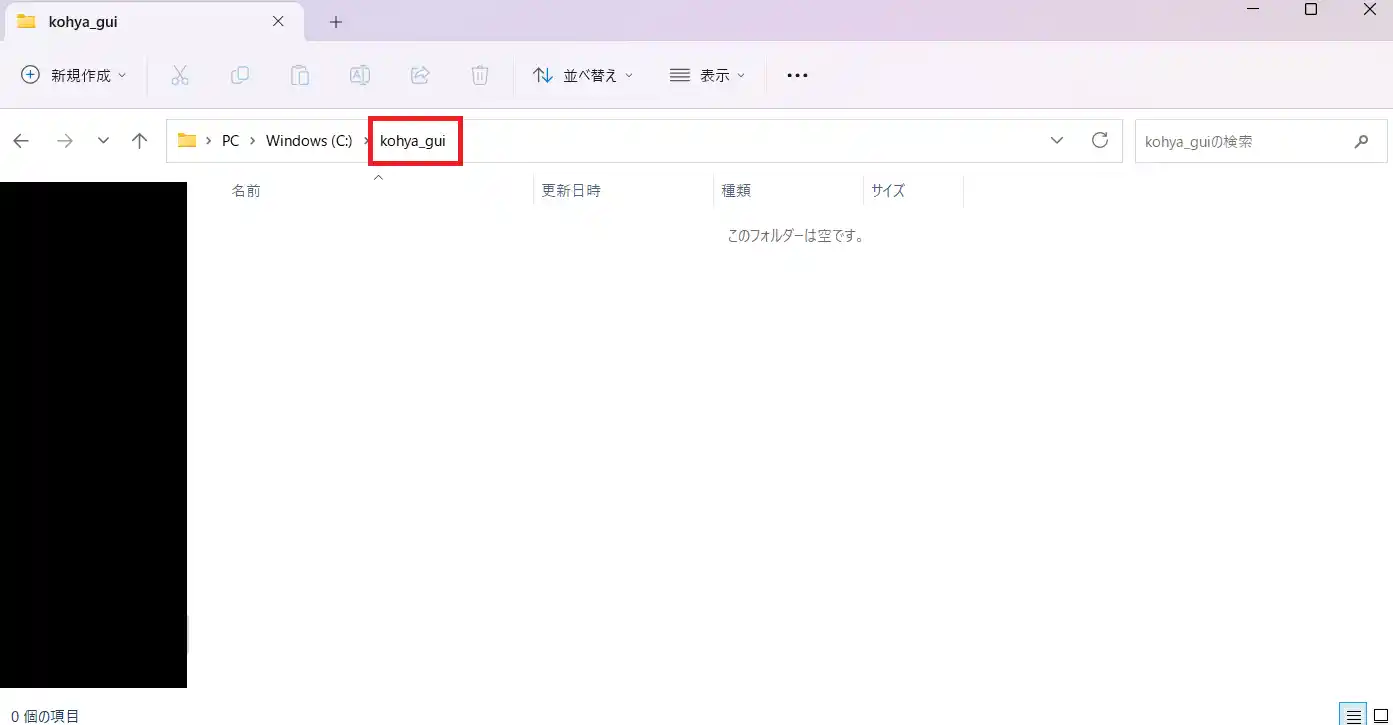
場所はどこでも大丈夫です。上記の画像では、Cドライブ直下にkohya_guiというフォルダを指定することにしました。
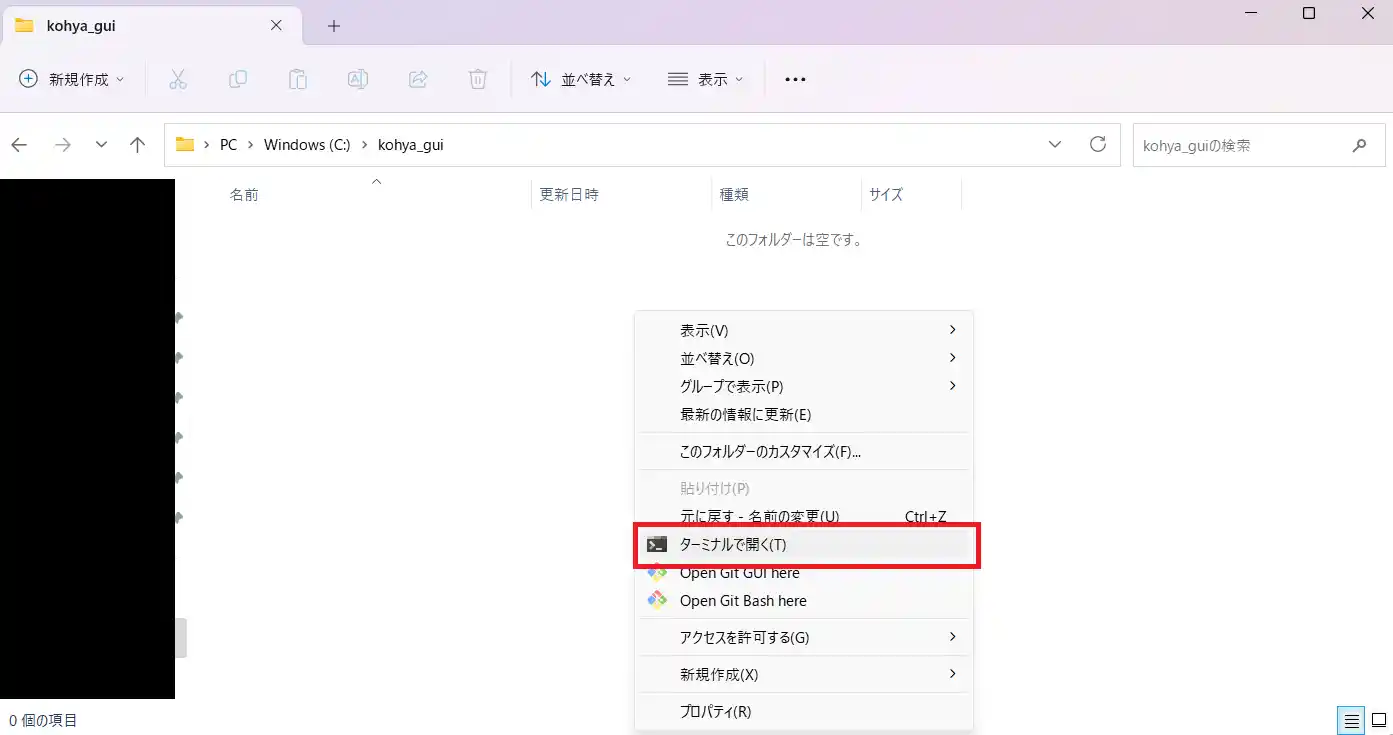
フォルダを作成したら、右クリックし「ターミナルで開く」をクリックしてください。
そうすると、以下の画像のようにpowershellというソフトが立ち上がります。
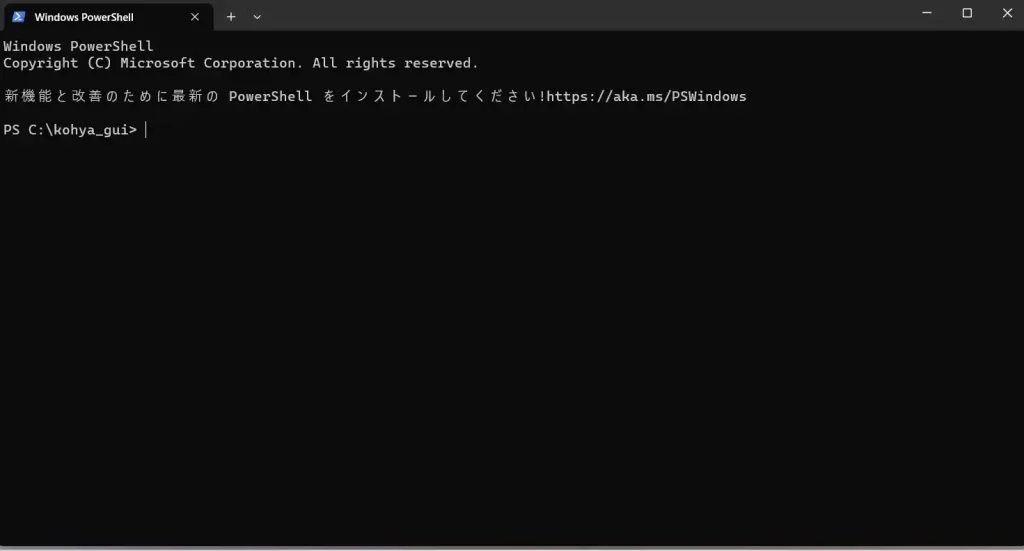
そうしたら、以下のコマンドを打ち込みます。
git clone https://github.com/bmaltais/kohya_ss.git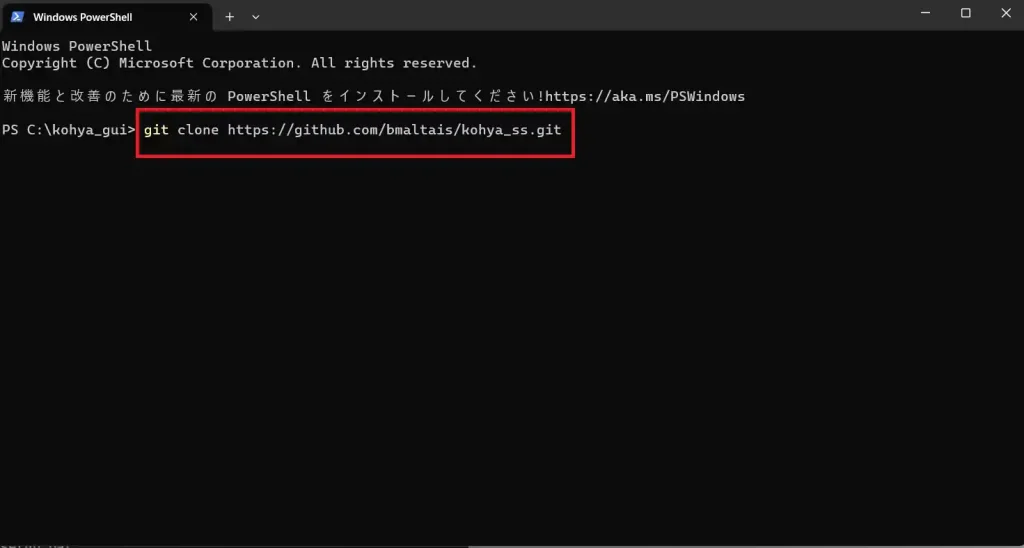
すると、必要データのダウンロードが始まるので、終わるまで待ちます。
次に、以下のコマンドを打ち込みます。
cd kohya_ss
.\setup.bat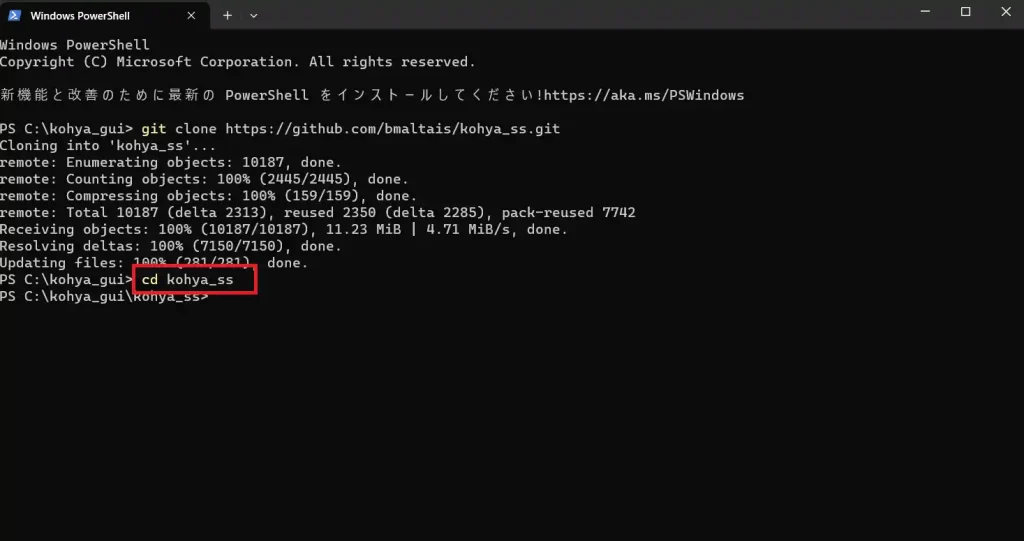
コマンドは一気に打つのではなく、1行ずつ打つようにしてください。
これで、Kohya_ss GUIのインストールは完了です。続いてセットアップをしていきます。
Python 指定されたパスが見つかりません。と出た時の対処法
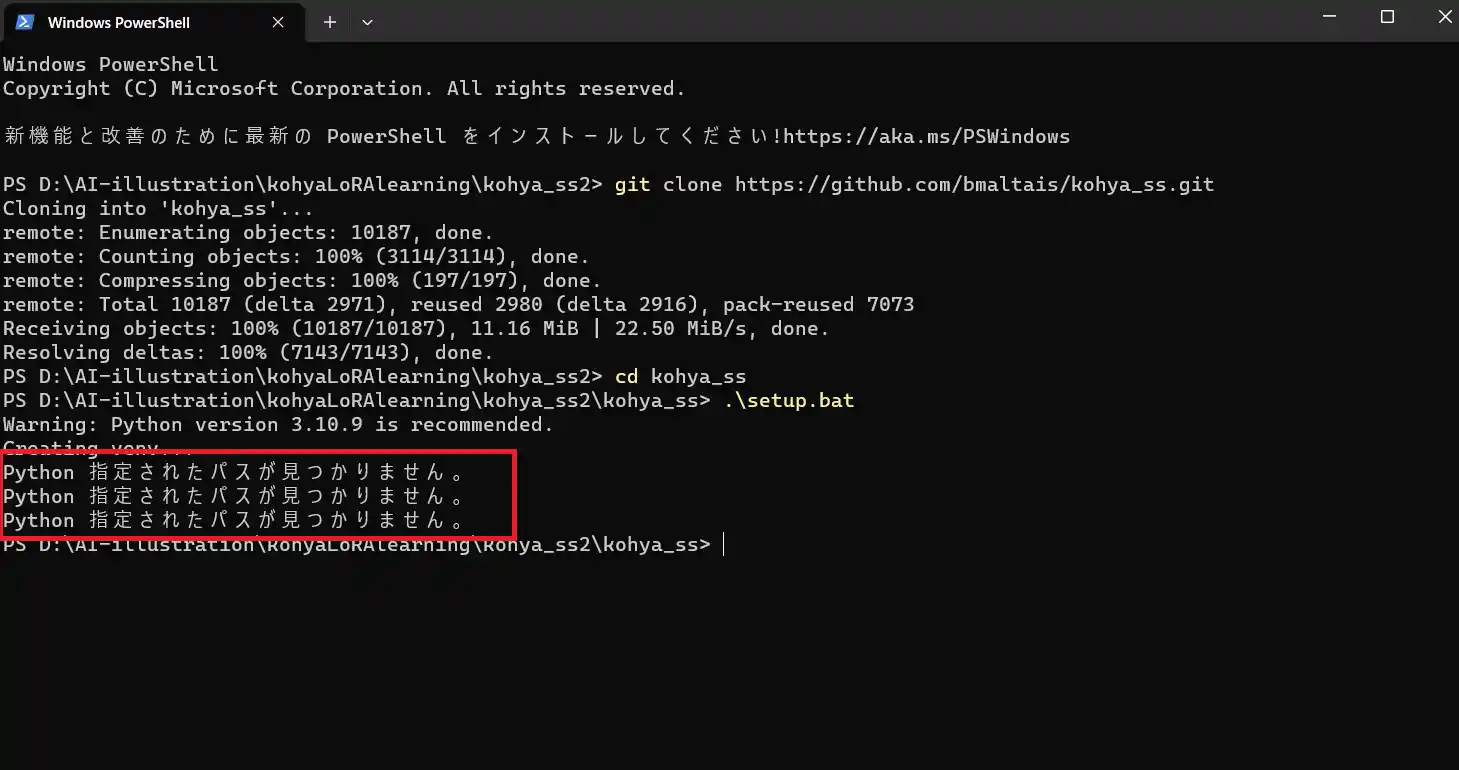
環境によっては、.\setup.batコマンドを実行後に「Python 指定されたパスが見つかりません。」というエラーが発生する場合があります。
このエラーが発生したらpowershellを閉じ、コマンドプロンプトに切り替えてください。
コマンドプロンプトの開き方は、「kohya_ss」フォルダを開き、フォルダ階層のところに「cmd」と入れるだけです。
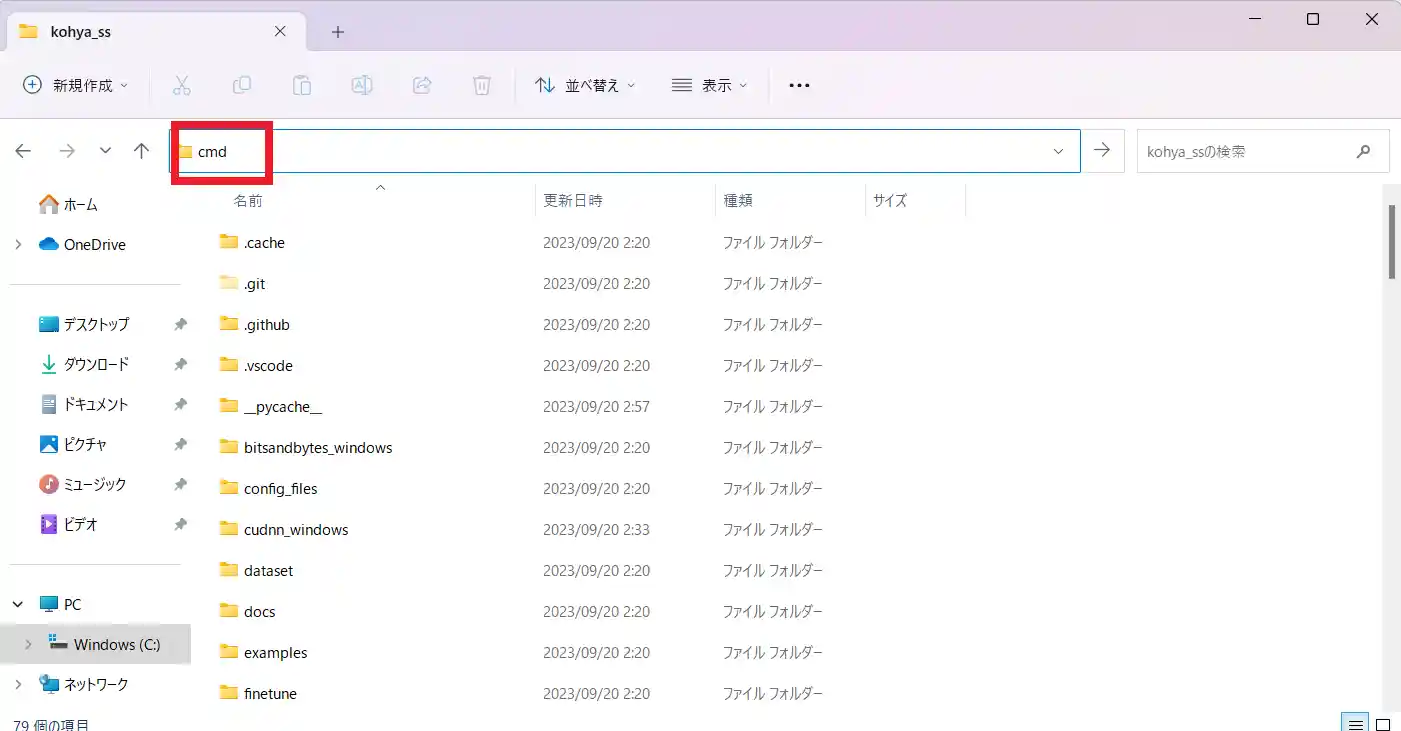
コマンドプロンプトに切り替えたら、以下のコマンドを実行してください。
python.exeへのフルパス -m venv venv
.\venv\Scripts\activate.bat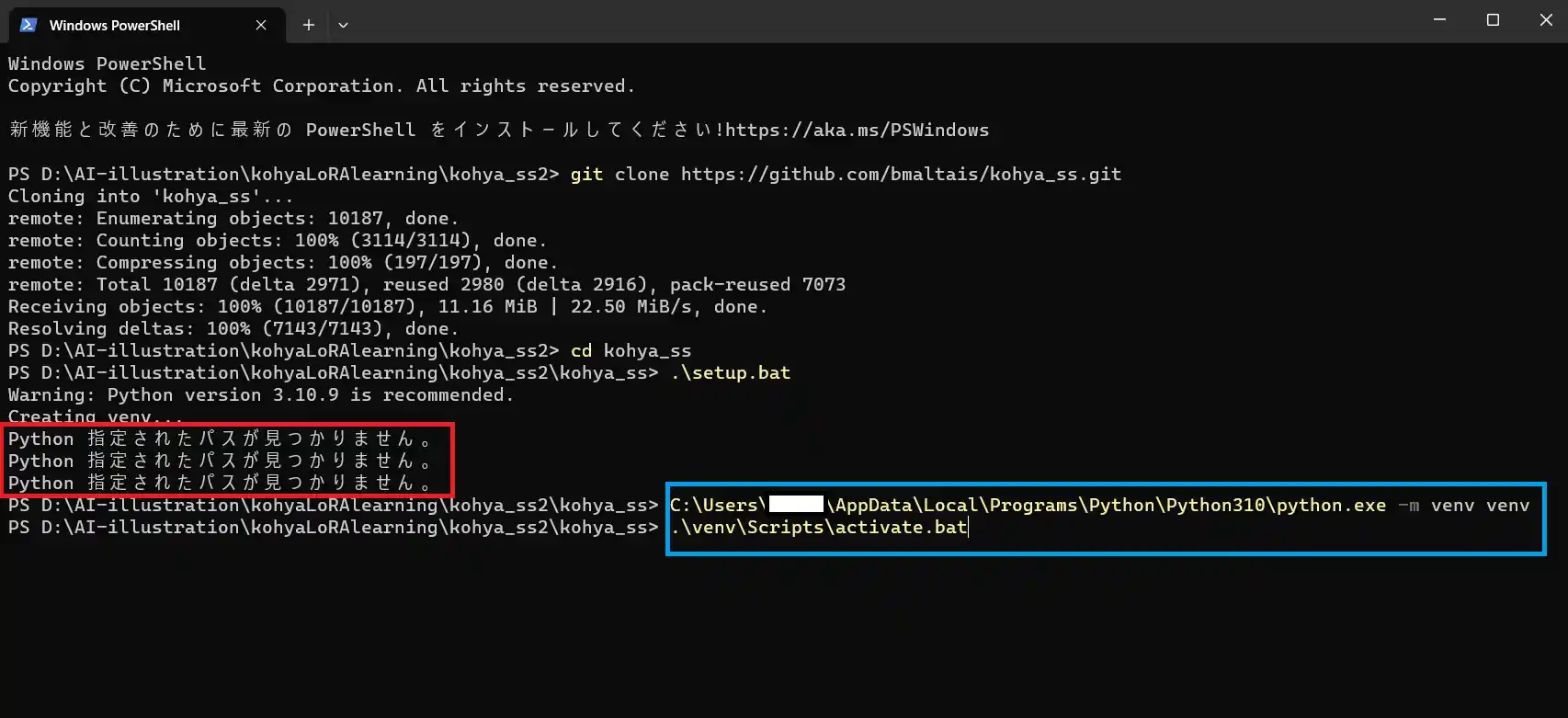
ディレクトリの頭に「(venv)」と付いていたら成功です。
この状態で以下のコマンドを実行しましょう。
setup.bat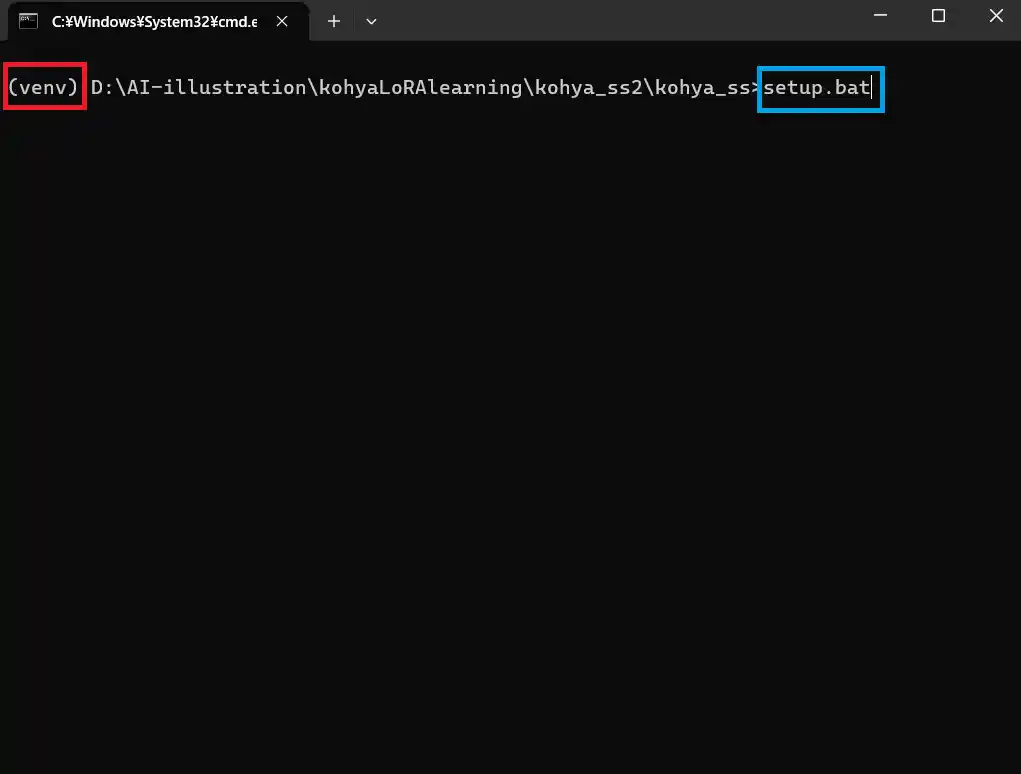
これでセットアップ画面に入れます。
2.セットアップ
上記の手順を終わらせると、以下のようにセットアップメニューが表示されます。
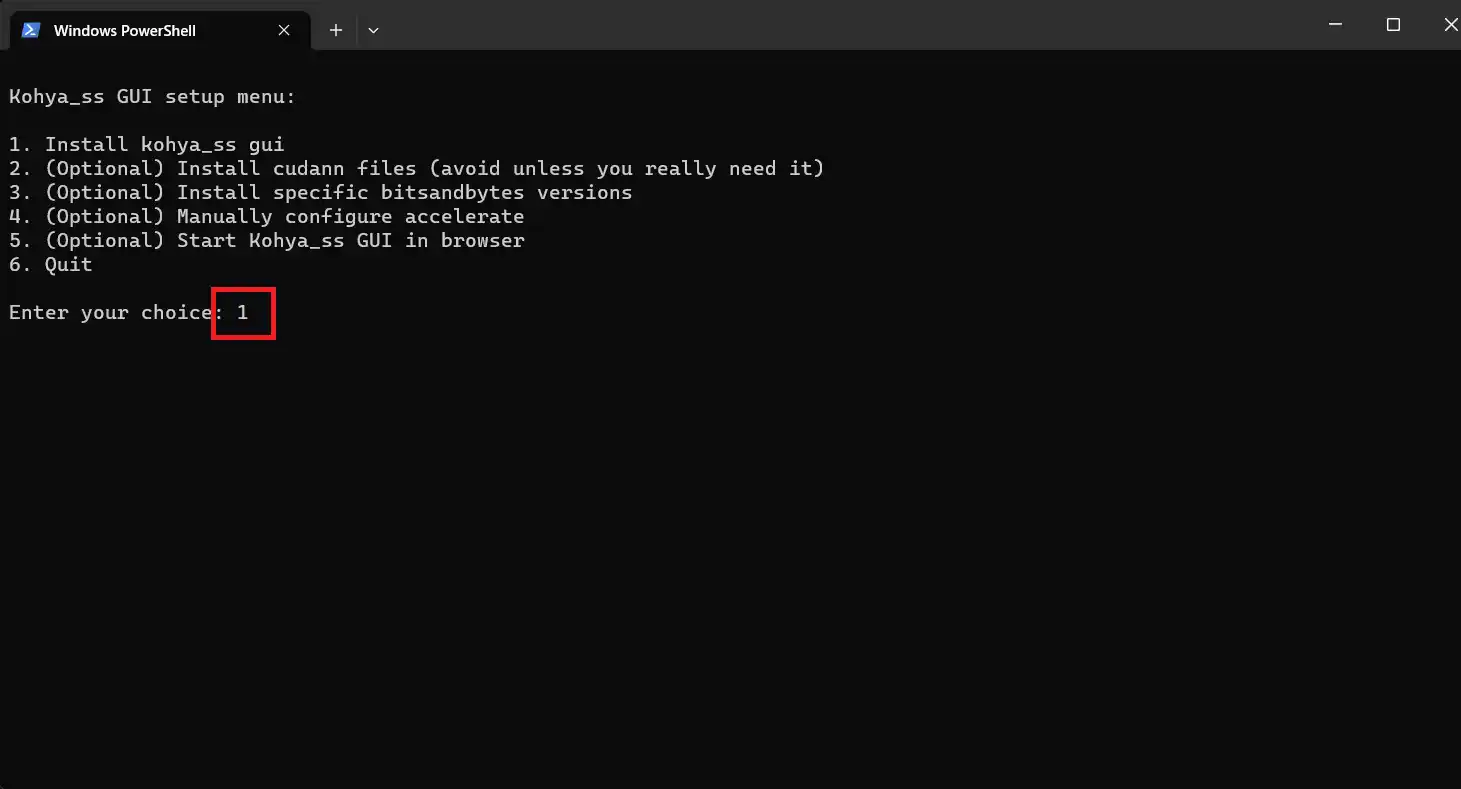
まずは1番の”Install kohya_ss gui“を実行したいので、”Enter your choice“のところに「1」と入力してエンターキーを押しましょう。
するとインストールするTorchのバージョンを聞かれます。Torch 2をインストールしたいので「2」を入力してエンターです。
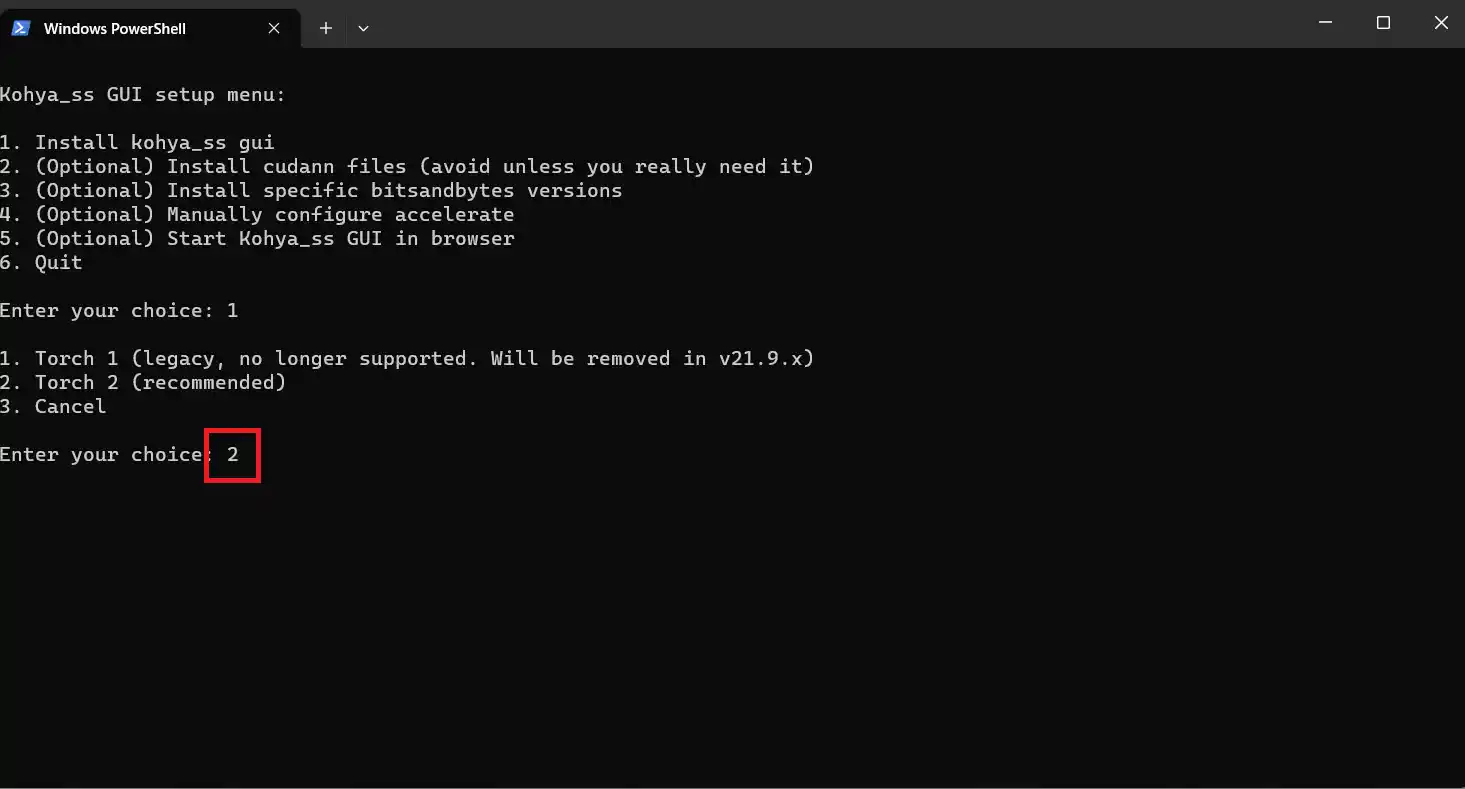
このインストールは多少時間がかかります。環境によっては数十分かかるようなので、終わるまで待ちましょう。
インストールが終わると、セットアップメニュー項目4番のkohya_ssのコンフィグが自動で実行されます。
環境によっては自動実行されない場合もあるので、その場合はEnter your choiceに「4」と入力してください。
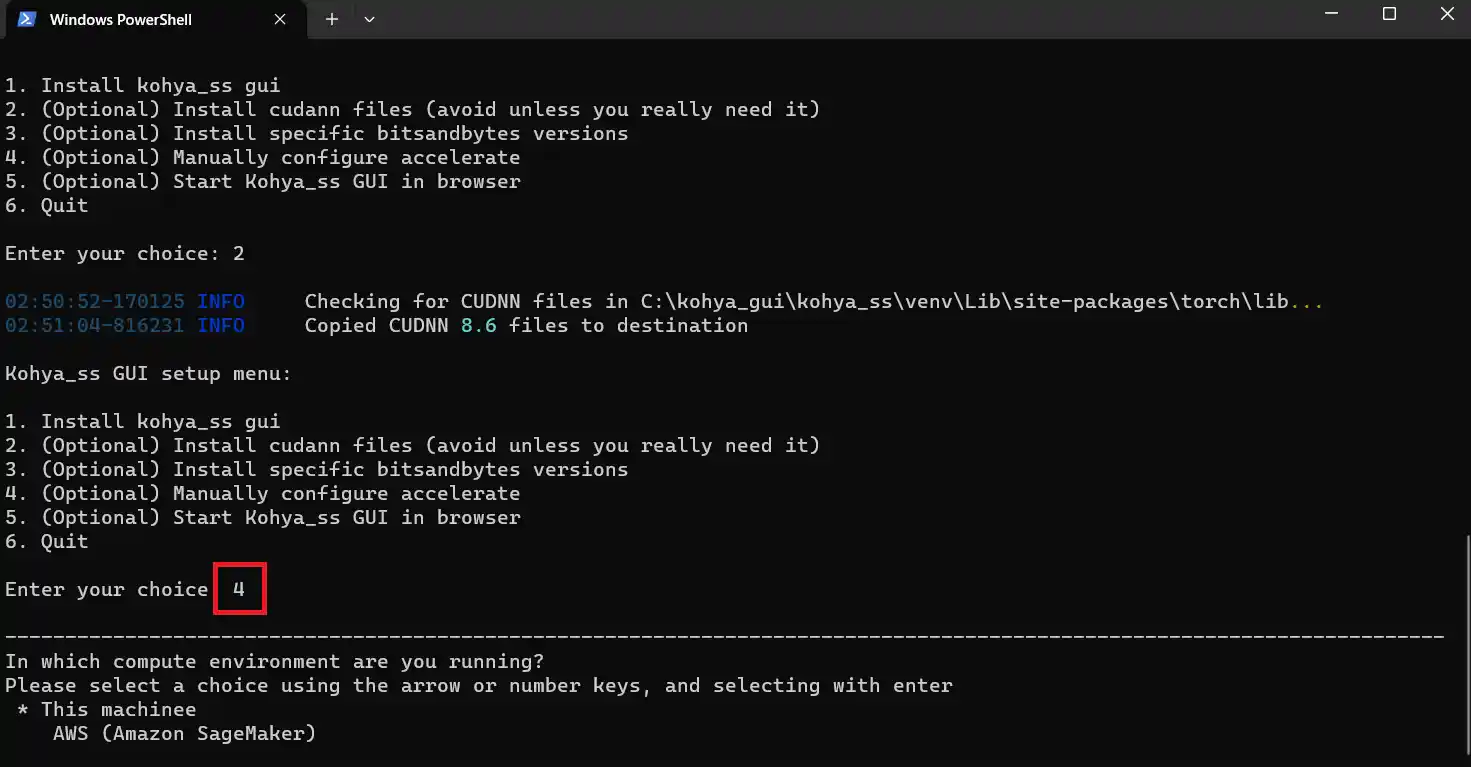
この項目ではいくつか質問されるので、以下のように答えてください。
選択肢は矢印キーか数字キーで変更できます。
1.This machinee
2.No distributed training
3.no
4.no
5.no
6.all
7.fp16
3~6個目の質問は選択ではなく直接打ち込んでください。
7個目の選択肢ですが、使用しているGPUがRTX3000番台とRTX4000番台でVRAMが12GB以上であればbf16を選択しても良いそうです。
これでセットアップが完了しました。
スポンサーリンク
3.kohya_ss GUIの起動
先ほどのセットアップメニュー5番の”(Optional) start kohya_ss GUI in browser” を選択すると起動することができます。
そうするとブラウザでkohya_ss GUIが立ち上がります。
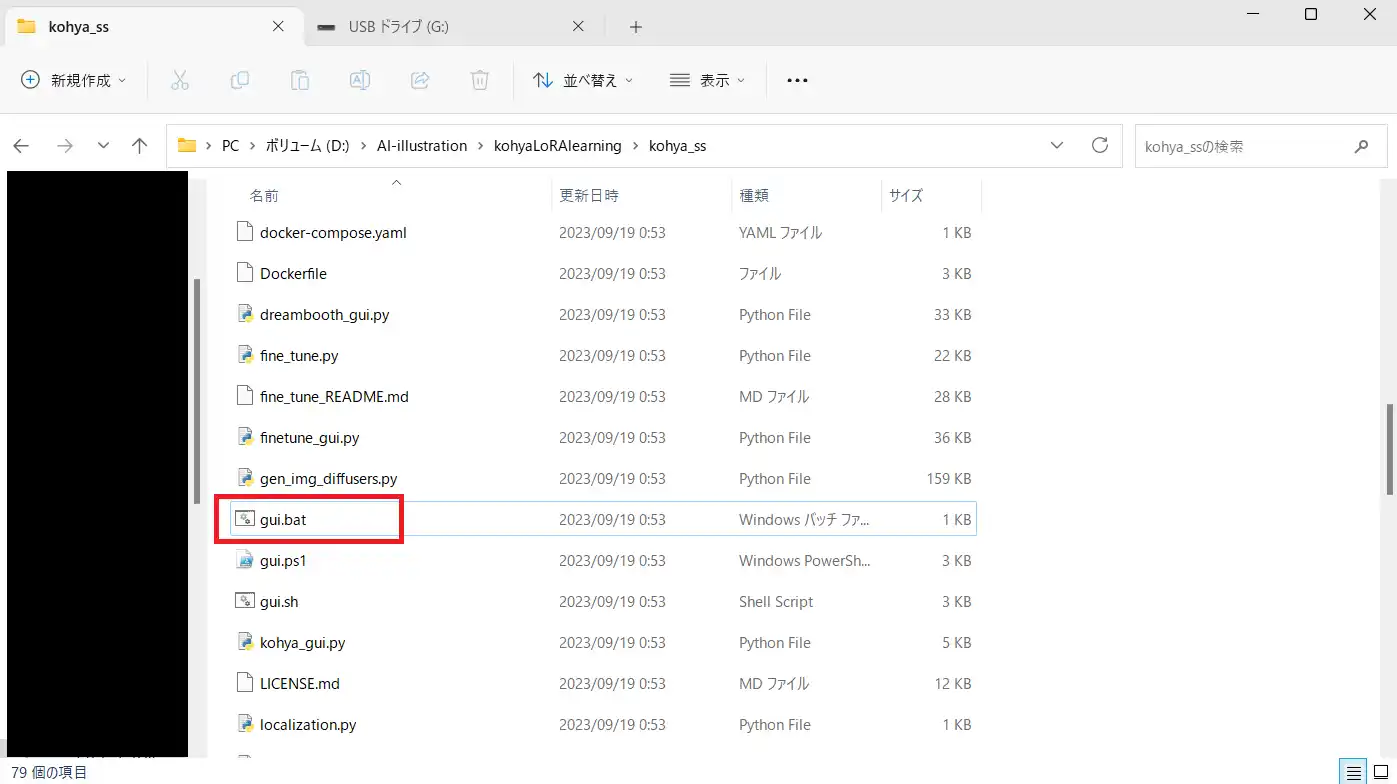
2回目以降の起動
2回目の起動は簡単です。まずはkohya_ssフォルダにある”gui.bat“を実行します。
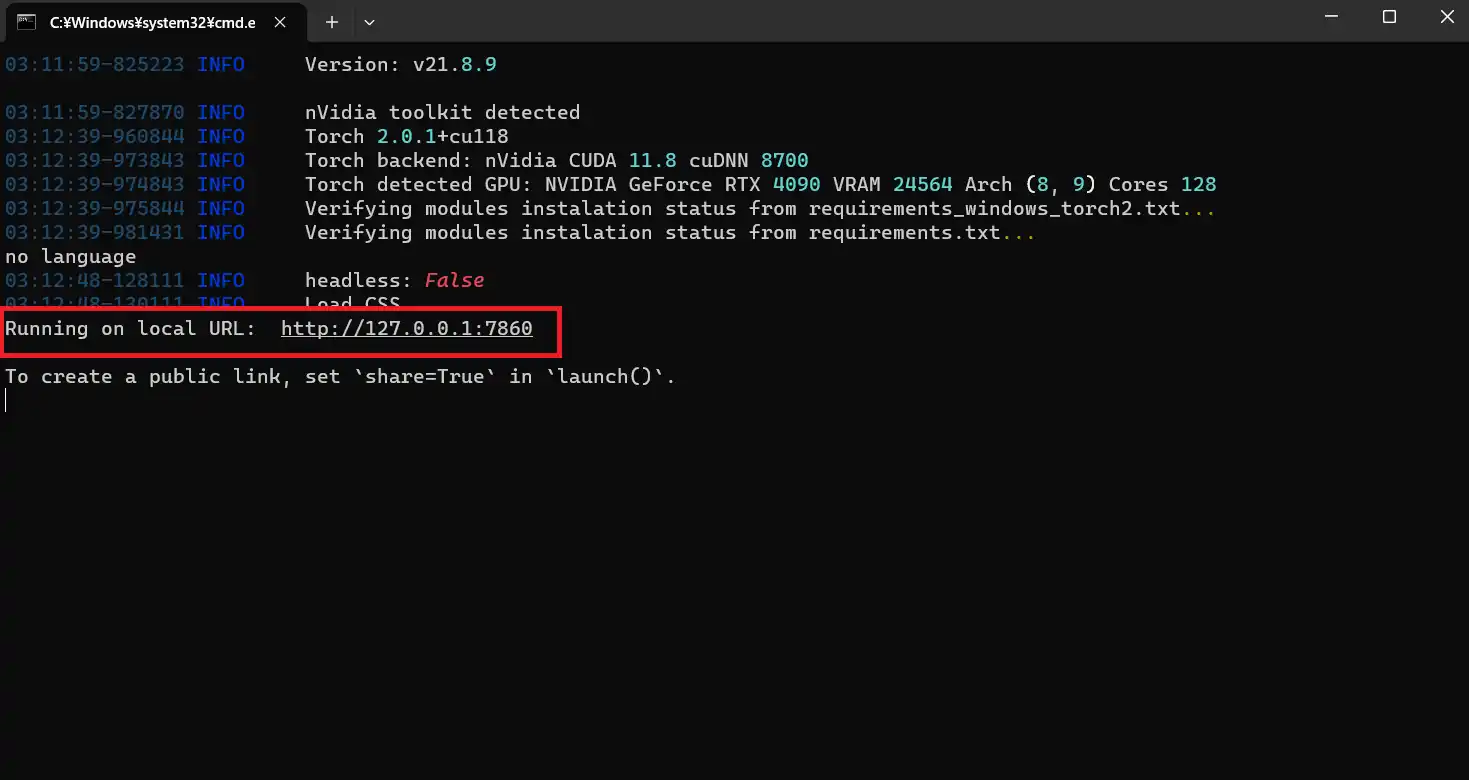
次に、表示されたURLをCtrlキーを押しながらクリックすることで起動できます。
3.学習用データの用意
それではお待ちかねのLoRA学習の方法です。
学習用画像は、東北ずん子プロジェクトが学習用として配布しているのを利用します。

今回は漆黒のめたんを学習させていきます。
この学習データは既にキャプションが付いているので、今回はこのキャプションファイルを使用しますが、一応キャプション付けのやり方も解説していこうと思います。

1.学習用フォルダの作成
階層はどこでも良いので「1_〇〇」というフォルダを作成します。
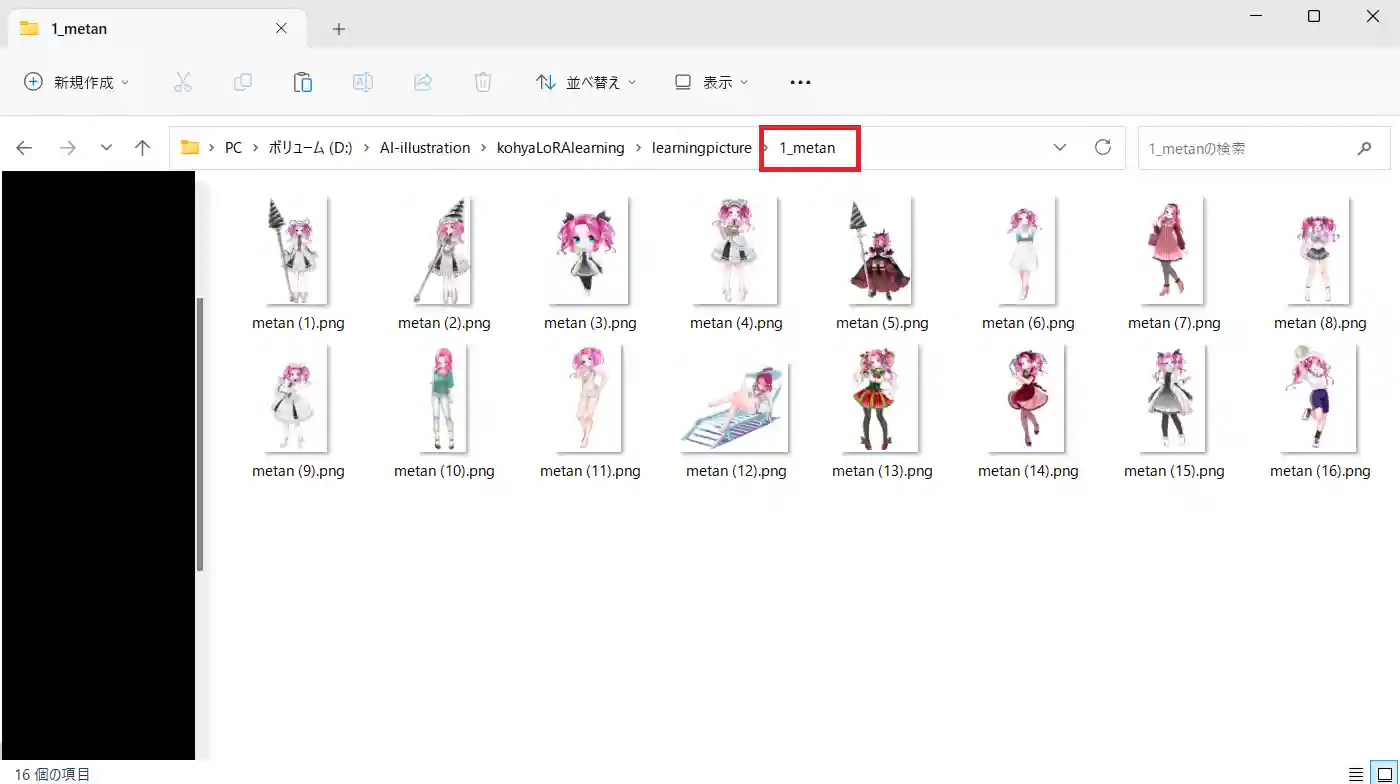
〇〇は自由に決めてもらって大丈夫です。また、この名前が呼び出し用のプロンプトになります。(キャプションファイルを用いる場合は後述)
「1」は繰り返し回数です。繰り返し回数と後述するEpoch数を掛けた値が学習STEP数になります。
今回は「1_metan」でフォルダを作成しました。
フォルダを作成したら、このフォルダの中に学習で使う画像データを入れていきます。
注意点ですが、後述する正則化画像を使用する場合繰り返し回数の部分が変更になります。
詳しくは正則化画像で解説します。
また、今回は正則化画像を使用せずに学習を行うので、フォルダ名は「1_metan」のままです。
2.キャプションファイルの作成
それではキャプションファイルを作成していきましょう。キャプションファイルの作成は、AUTOMATIC1111 Stable-Diffusion-webuiの拡張機能を使います。
拡張機能はstable-diffusion-webui-wd14-taggerを使うので、導入していない方は導入してください。
まずは、以下の画像のように設定します。
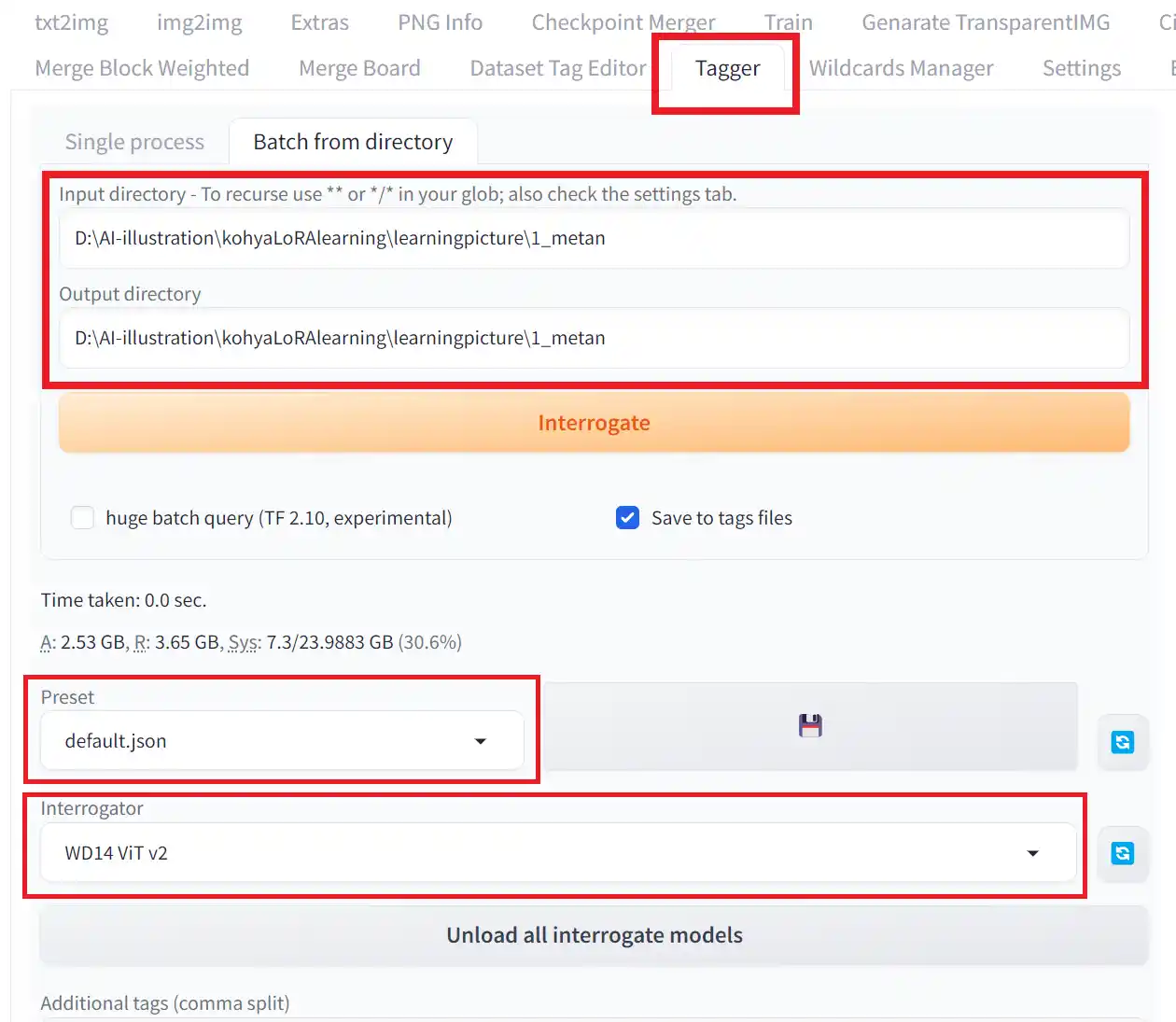
1.Taggerタブを開く
2.Input directoryとOutput directoryに先ほど用意した「1_metan」までのパスを入力する。
3.Presetがdefault.jsonになっているか確認する。
4.Interrogatorを「WD14 Vit v2」に変更する。※WD14 moat tagger v2の方が精度が良いようです。
ここまでの設定が終わったら、その下の項目を設定していきます。
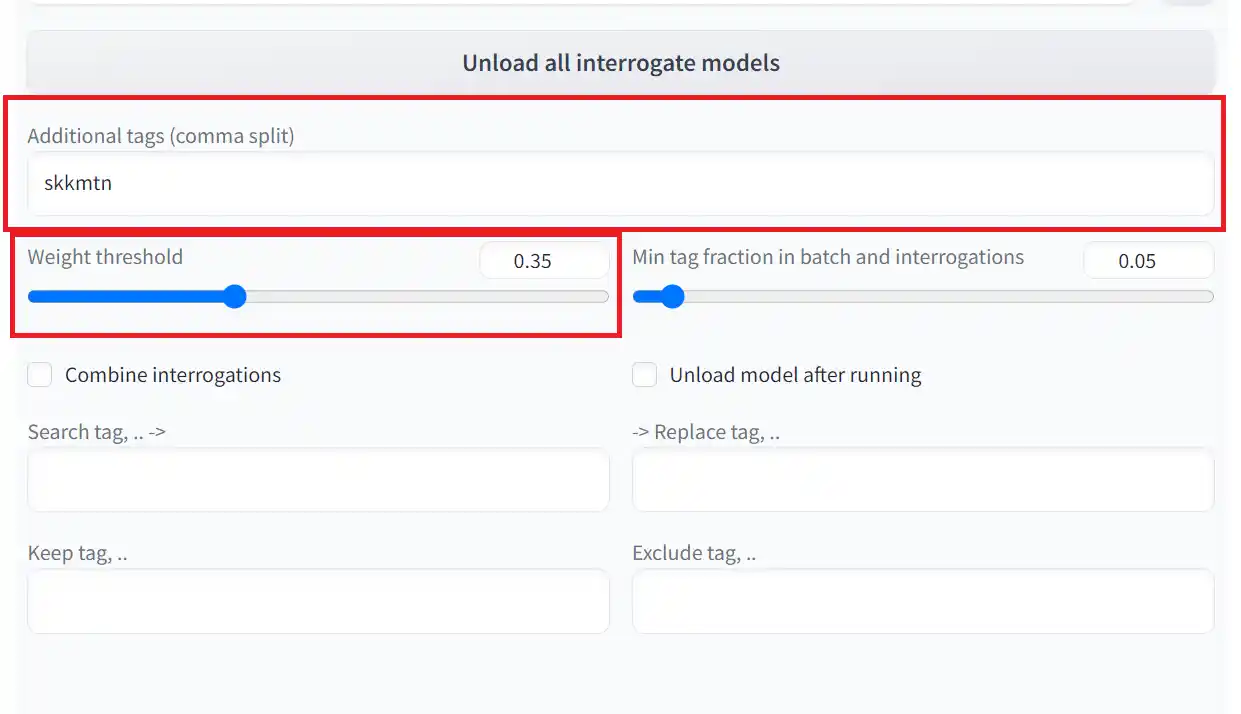
1.Additional tagsの設定
この項目では、キャプションファイルの先頭に付くタグを指定できます。多くの場合、ここで指定したタグが呼び出し用のプロンプトになります。上記の画像では「skkmtn」とします。所謂トリガーワードというものです。
ただし、今回本番で使うキャプションファイルは配布されていたものを使うので、この記事で行う学習での呼び出し用プロンプトは「metan」になります。
2.Weight thresholdの設定
この項目は、どれだけタグを細かく分けるかの設定です。
設定値を0.95で作成した場合、付いたタグは以下の10個になります。

今度は数値を0.5にして作成してみます。
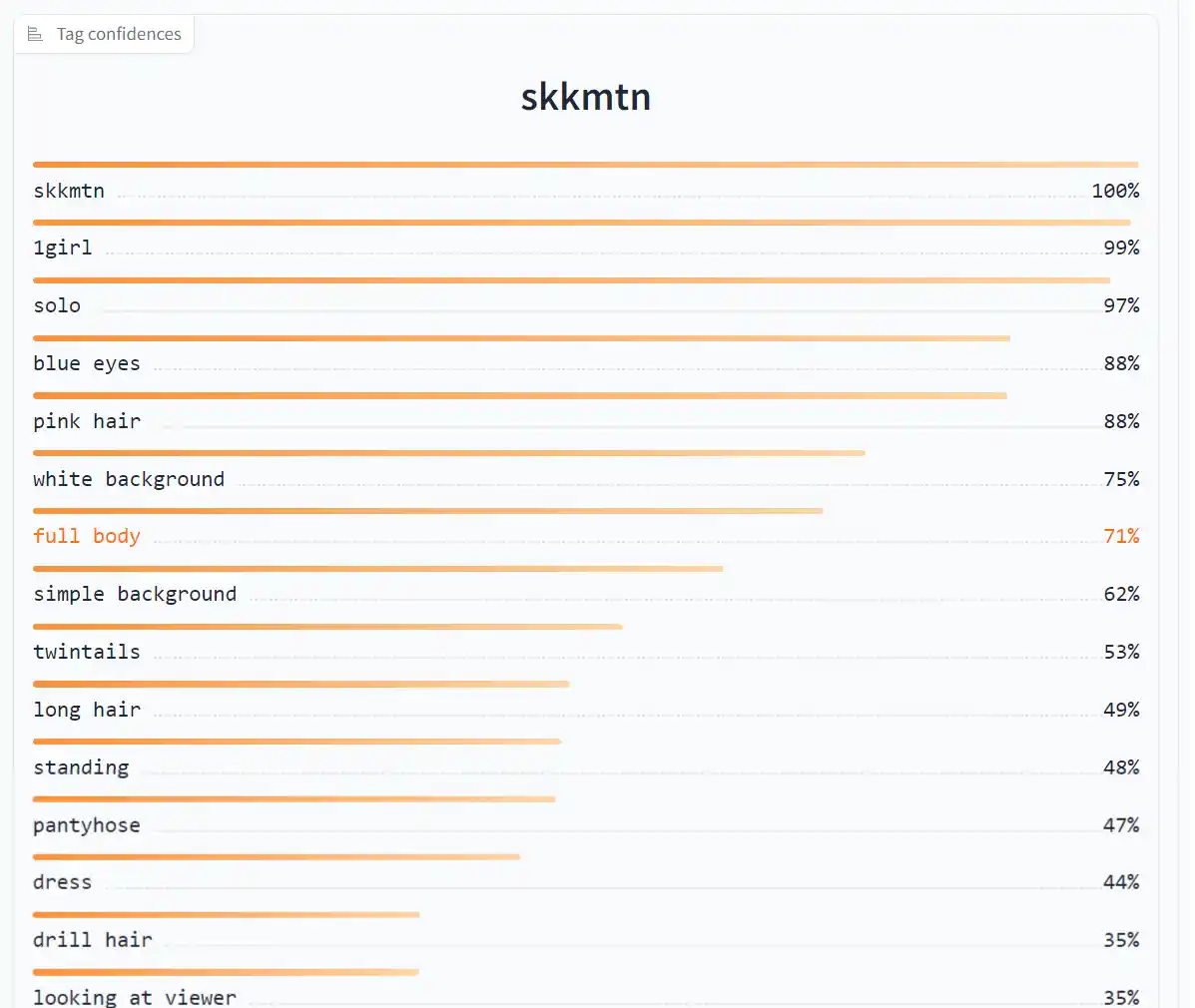
今度はたくさんのタグが付与されました。多すぎて途中で切っていますが、100個以上のタグが付いています。
デフォルトの0.35で十分だと思いますが、画風学習の場合は少し数値を下げてみても良いかもしれません。
3.キャプションファイルの編集
先ほど付けたタグから、いらないものを消していきます。
画風LoRAを作成する場合、この作業はいりません。
消すタグは、髪色や髪型、目の色といった覚えさせたいキャラの特徴タグです。そうすることによって、設定した「skkmtn」というタグに、キャラの特徴を集約させることができます。
キャプションファイルの編集には、AUTOMATIC1111 Stable-Diffusion-webuiの拡張機能を使います。
拡張機能はstable-diffusion-webui-dataset-tag-editorというのを使います。導入がまだの方はインストールしてください。
スタンドアローン版もあるので、バージョンの問題などでweb-uiに導入できない場合はスタンドアローン版をインストールしてみてください。
それでは編集していきます。
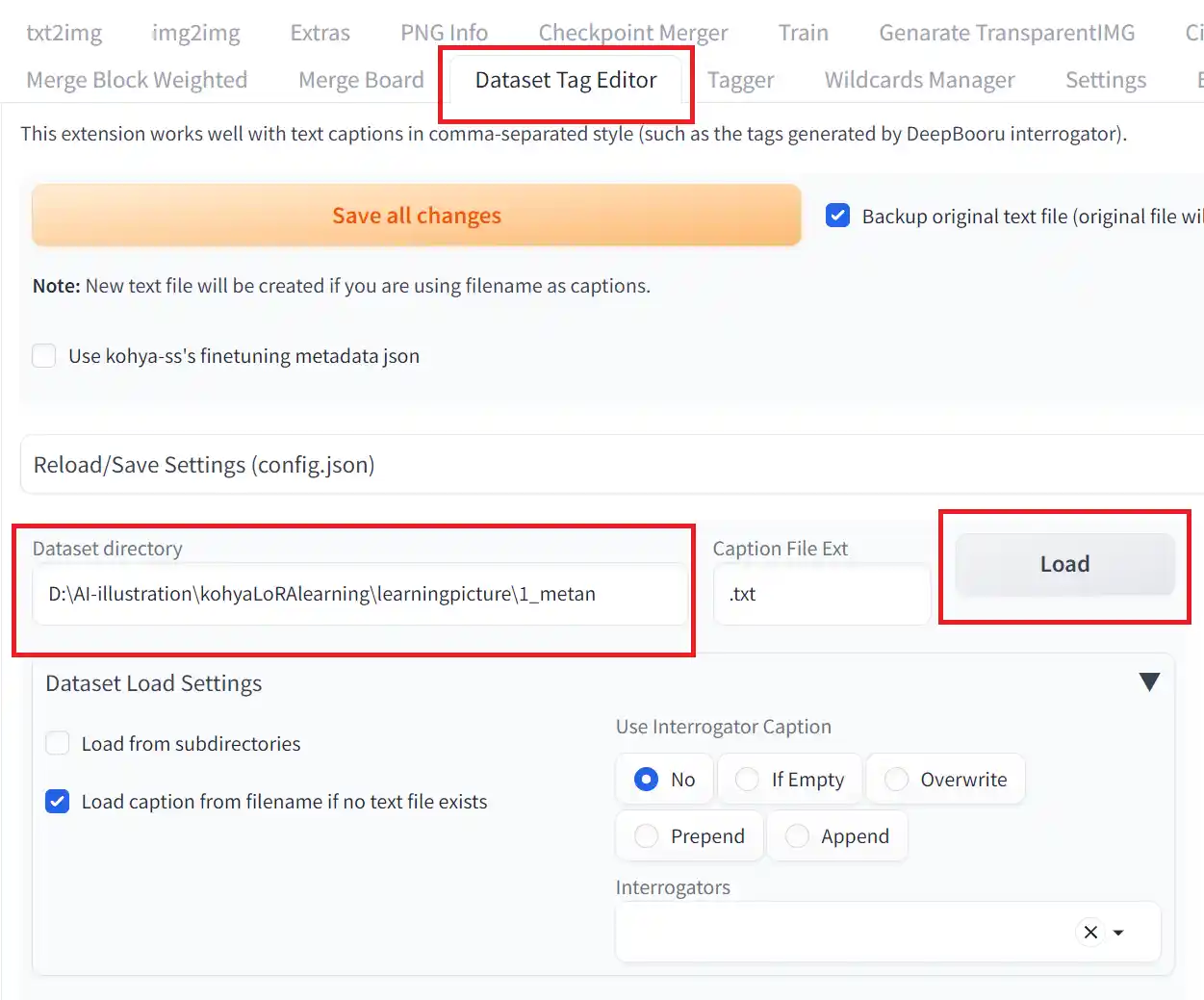
1.「Dataset Tag Editor」タブを開く
2.Dataset directoryにキャプションファイルが入ってるフォルダのパスを入力する。
3.Loadをクリックする
次に、右側の「Batch Edit Captions」タブを開き、その中の「Remove」タグを開きます。
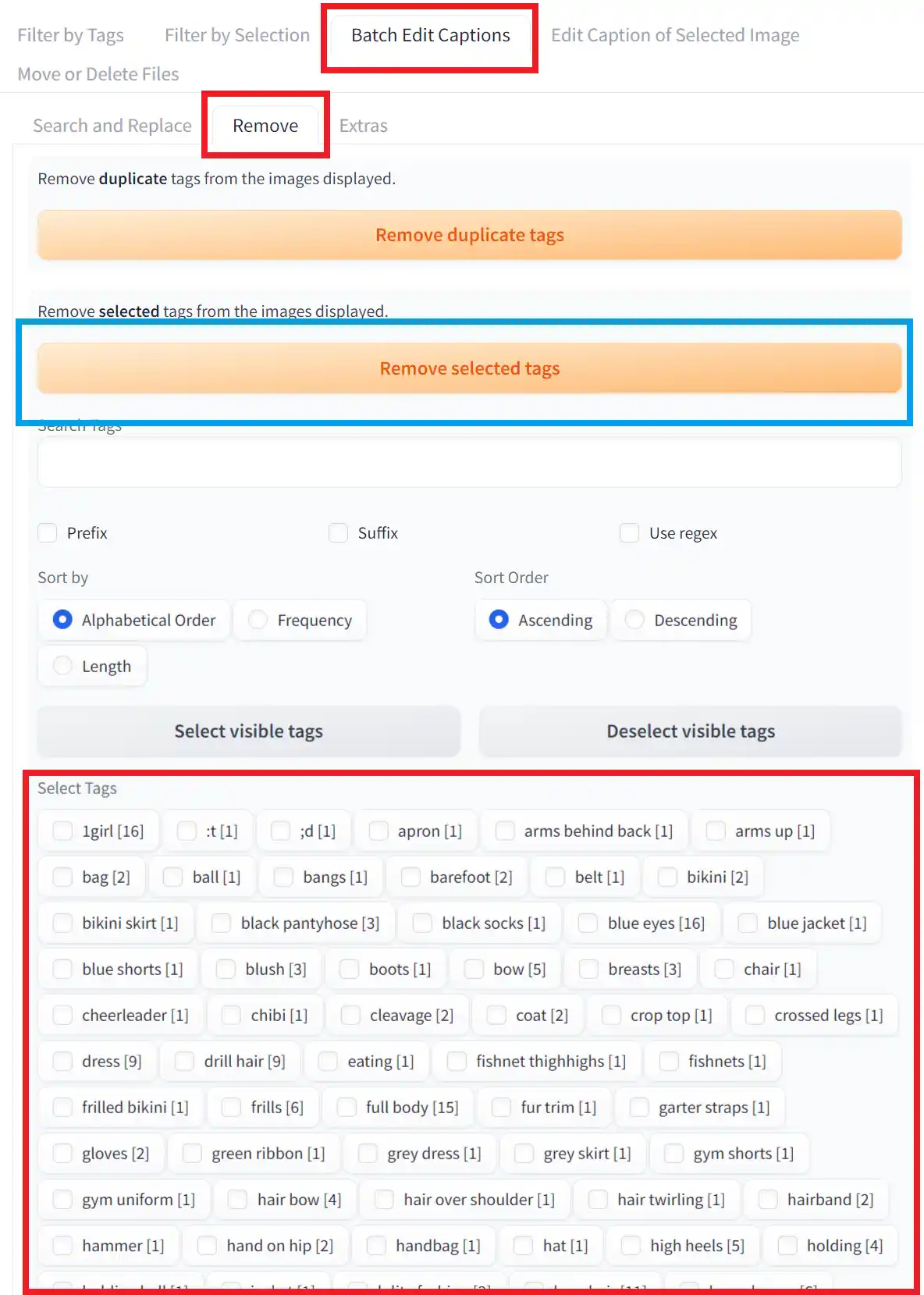
そうしたら、下の方にキャプションファイルに含まれているタグが全て表示されているので、ここから消したいタグを選択していきます。
キャラ学習の場合は、以下のタグを選択すると良いでしょう。
・髪色
・髪型
・瞳の色
・衣装
・胸の大きさ
ただし、髪型や髪色、衣装を固定したくないのであれば、それらに関係するタグは消さない方が良いですね。
選択し終わったら、青枠で囲んだRemove selected tagsをクリックしましょう。
最後にSave all changesをクリックして変更を反映しましょう。

青枠で囲った項目のチェックを外すと、余計なファイルが作成されないのでチェックを入れることをおすすめします。
これでキャプションファイルの作成が終わりました。
最後に確認のため「1_metan」フォルダを確認し、もし学習用画像とキャプションファイル以外の.txtファイル(.jsonなど)があった場合は削除しましょう。
4.正則化画像
最初に注意事項ですが、私自身正則化画像をあまり使っておらず、曖昧な情報となっているので、あまり鵜呑みにしない方が良いです。
1.正則化画像の効果
正則化画像を使わずにLoRA学習をすると、キャラの特徴だけでなく画風まで学習してしまいます。画風LoRAを作る場合はそれで良いのですが、キャラだけを学習し、普段使っているモデルの画風でイラストを生成したい場合、そうなると困ります。
正則化画像を使うと、画風が学習画像に引っ張られにくくなるようです。
ただ、画風の問題は、学習の設定や学習画像である程度コントロールできそうです。
ただし、今回みたいに同じ画風のイラストを学習用画像にした場合は、その画風に寄る傾向があるようです。
また、私はキャラ学習と衣装学習では正則化画像は使用していませんが、上手く学習出来ているので正則化画像は必要ないかもしれません。
2.正則化画像の作成
正則化画像は学習用モデルで生成します。女性キャラを学習させる場合は、プロンプトに「1girl」と入力し100枚程度生成すると良いでしょう。
3.正則化画像の格納フォルダ
正則化画像を保存するフォルダ名は「1_××」とすると良いそうです。例えば「1_girl」など。
4.学習用画像フォルダの繰り返し回数の変更
正則化画像を使用する場合、学習用画像の枚数を正則化画像の枚数に合わせなければなりません。
しかし、場合によっては学習用画像を増やせないこともあります。そんなときは学習用フォルダの繰り返し回数を変更します。
例えば、正則化画像が100枚に対し、学習用画像が20枚しかない場合は、学習用フォルダの繰り返し回数を「5」に変更します。これにより学習用フォルダは1Epochで5回繰り返されることになります。
5.kohya_ss GUIで学習実行
それでは、kohya_ss GUIを起動し、設定を行っていきましょう。
起動すると、以下のような画面が開きます。
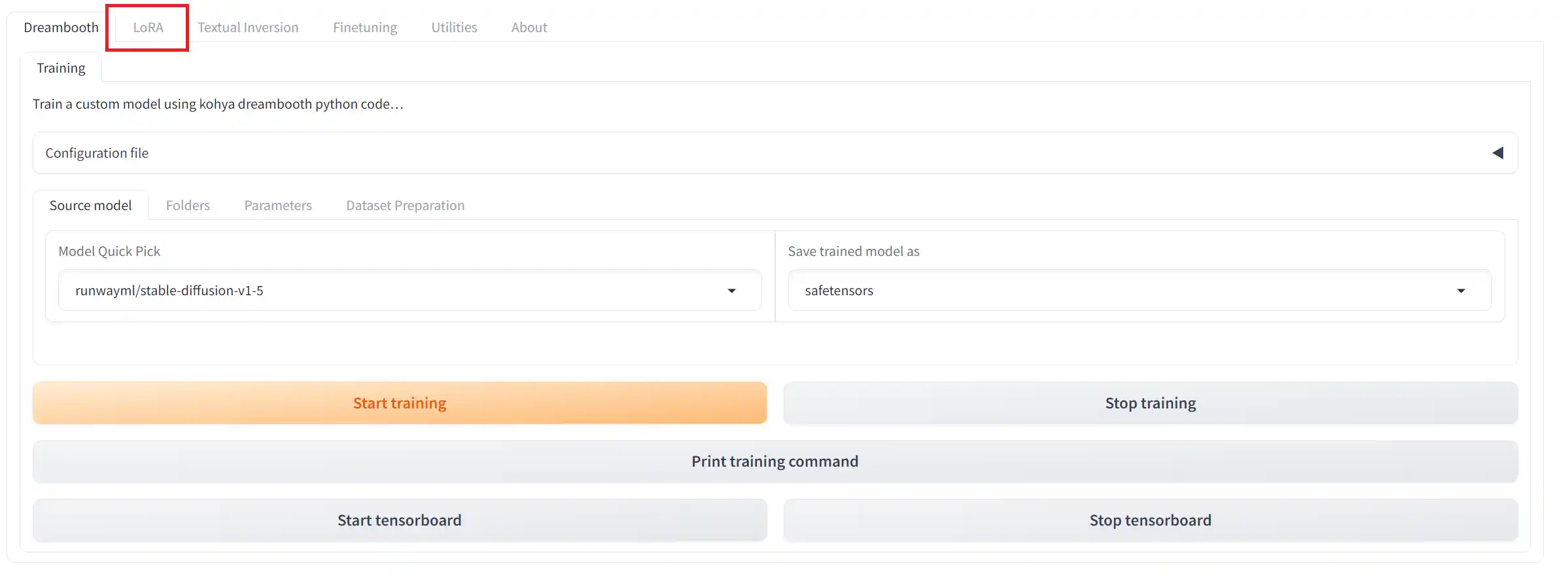
デフォルトでは「DreamBooth」タブが開かれているので、「LoRA」タブに切り替えましょう。
1.学習に使うモデルの選択
「LoRA」タブを開いたら、次は学習に使うモデルの選択です。
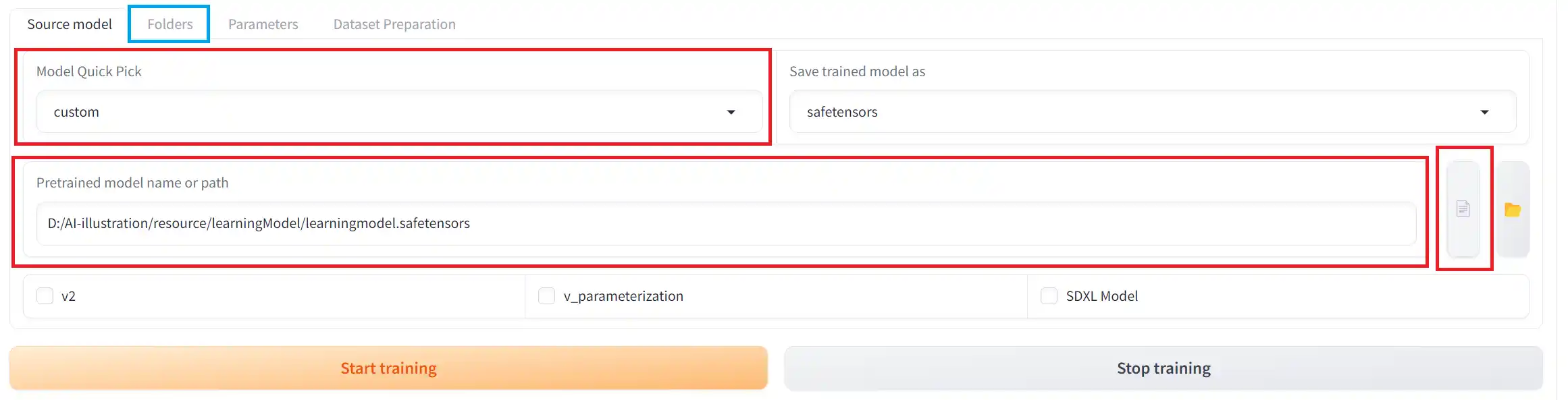
「Source model」タブの「Model Quick Pick」を”custom“に変更します。
すると、下の方に「Pretrained model name or path」という項目が表示されるので、こちらに使用するモデルのパスを入力していきます。右側の書類マークをクリックすることでモデルを直接選択できます。下の3つのチェックは外しておきます。
ただし、使用モデルのバージョンがSDXL系の場合は「SDXL Model」にチェック、SD2系の場合は「V2」にチェックを入れましょう。「v_parameterization」はSD2系で使われる手法のようです。SD1系やSDXLではオフにしましょう。
「Save trained model as」は出力されるLoRAファイルの形式です。特に理由がなければデフォルトの「safetensors」で大丈夫です。
LoRAに関するメタデータを完全に削除したい場合は「ckpt」を選びましょう。メタデータを削除するやり方は後述する、メタデータの削除2を確認してくさださい
メタデータのうち、学習内容だけ消したい場合はメタデータの削除1を確認してください。
設定が完了したら、青枠で囲った「Folders」タブへいきましょう。
2.学習フォルダの設定
「Folders」タブでは以下のように設定していきます。
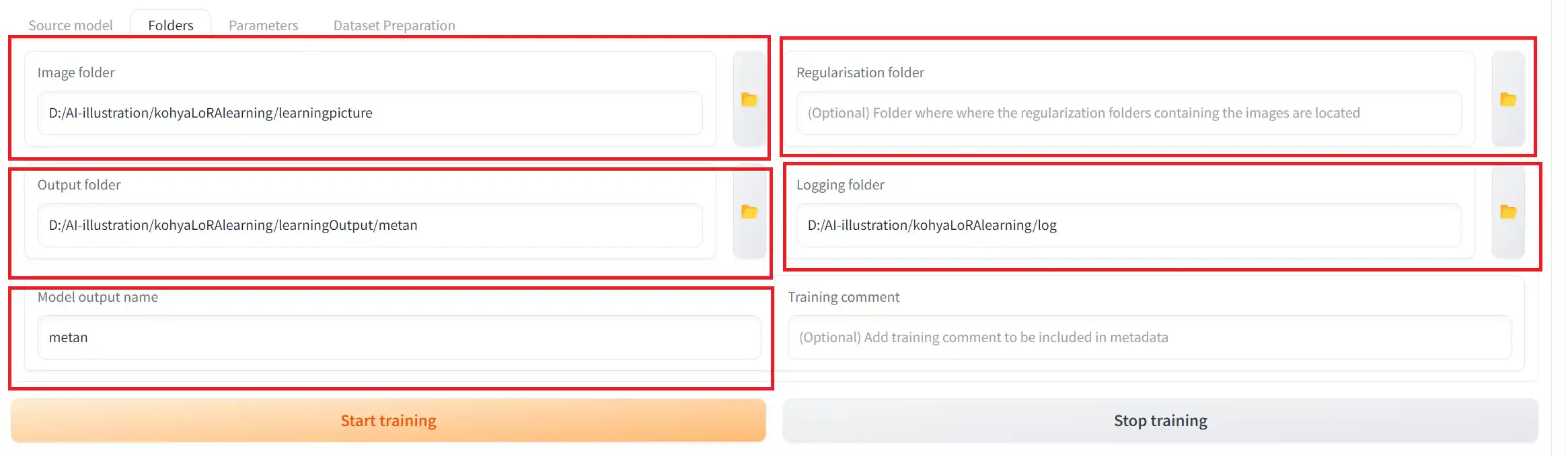
①Image folder
この項目には学習用画像の入ったフォルダを指定します。
注意点ですが、指定するフォルダは「1_metan」ではなく、「1_metan」が入っているフォルダですので、間違えないようにしてください。
②Regularisation folder
この項目には正則化画像が入ったフォルダを指定します。
今回は正則化画像を使用しないので、空欄で進めます。
注意点はImage folderと同じです。
③Output folder
この項目は、出力されるLoRAファイルの保存場所を指定します。
お好きな場所を指定してください。
④Logging folder
この項目は、出力されるログの保存場所です。
オプションなので空欄でも大丈夫です。こちらもお好きな場所を指定してください。
⑤Model output name
この項目は、出力されるLoRAファイルの名前になります。
今回は「metan」で進めていきます。
終わったら「Parameters」タブを開きます。
スポンサーリンク
3.学習用パラメーターの設定
「Parameters」タブを開いたら、細かい設定がたくさん出てきます。
今回は最低限必要な項目だけ設定していこうと思います。
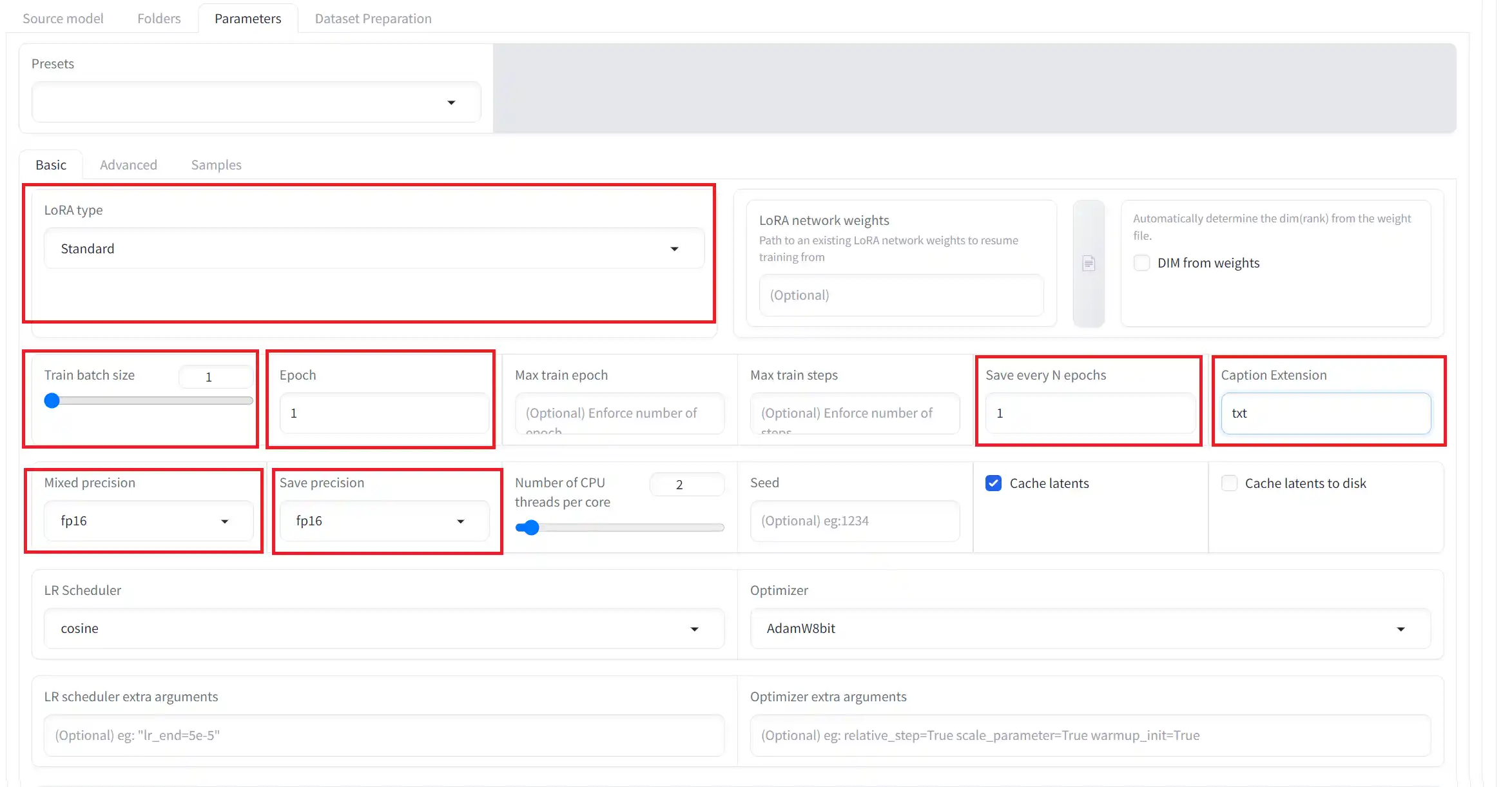
①LoRA type
この項目では、LoHaやLoConを作成したい場合は、ここから変更できます。
今回はLoRAを作成するのでStandardでやります。
②Train batch size
この項目は、数値を大きくすると学習が早く終わりますが、VRAMの使用量が増えます。
ここは使用しているグラボにより変更しても良いでしょう。
ただし、学習用画像のサイズが同一でない場合は「1」に設定するのが良いそうです。
③Epoch
この項目は、学習を何度行うかの設定です。学習用画像とEpoch数を掛けた値がSTEP数になります。
例えば、今回使う学習用画像は16枚あるので、Epoch数を100とした場合、画像16枚×Epoch100となり、STEP数は1600になります。
また、学習用画像フォルダの繰り返し回数を2に変更していた場合は、STEP数が倍になります。
④Save every N epochs
この項目では、学習の途中でLoRAファイルを保存する間隔を指定できます。
50と入力すれば、50Epochごとに保存されます。
⑤Caption Extension
この項目では、キャプションファイルの拡張子を設定します。
キャプションファイルはテキストファイルで作ったので、「txt」と入力します。
⑥Mixed precision
この項目はfp16、グラボによってはbf16を選択してください。
⑦Save precision
同上
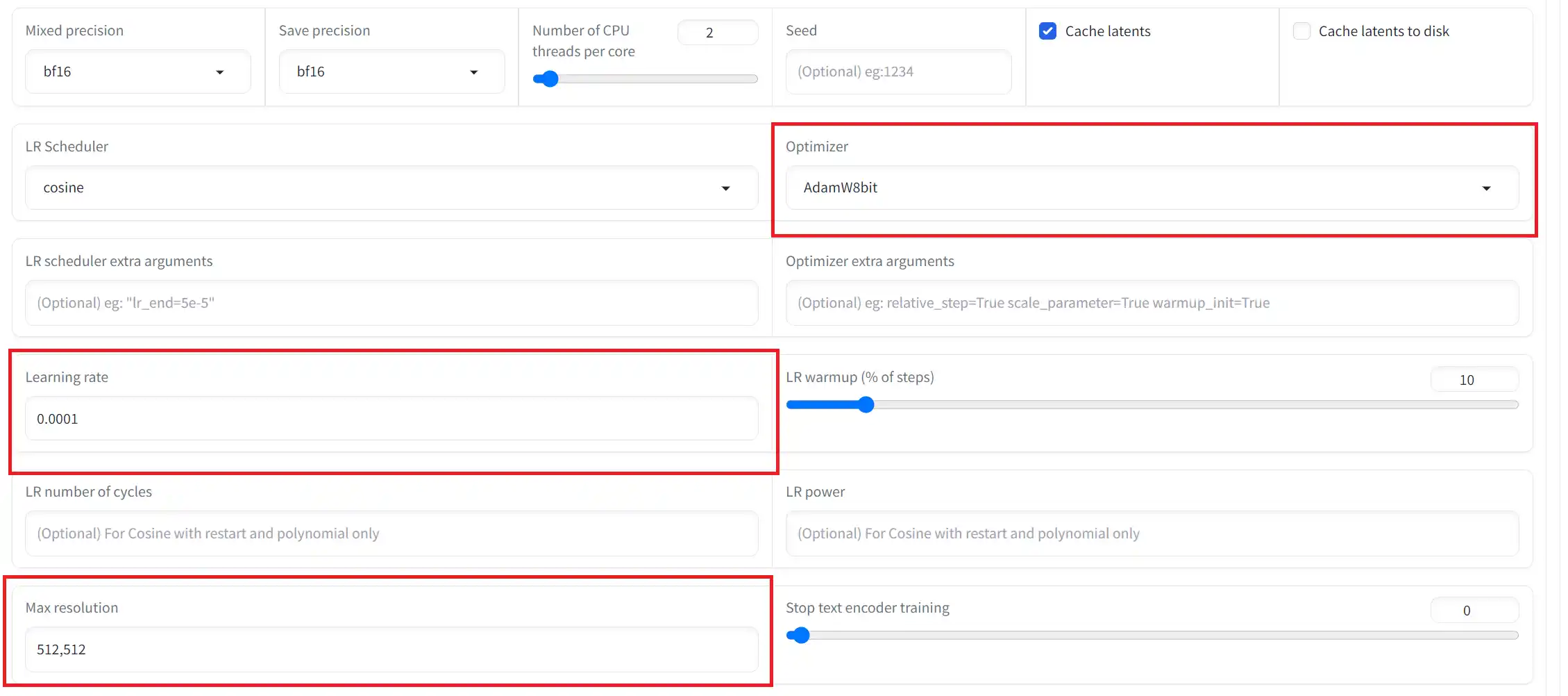
⑧Optimizer
基本的にはadamW8bitで良いです。もしVRAMが足りないようならadafactorに変更してみましょう。
⑨Learning rate
この項目では学習率を設定するのですが、機械学習のプロでも経験則で行っていると聞いたので、最適な数値というのはないようです。
この項目の説明としては、数値を大きくすると学習の進みが早くなり、代わりに過学習を起こしやすくなります。階段を数段飛ばしで駆け上がるような感じです。階段の途中がゴールだとしたら、その場所を飛び越してしまう=過学習、というようなイメージです。
逆に数値を小さくすると学習の進みは遅くなりますが、過学習を起こしにくいです。
ただし、小さすぎると少ないStep数だと全く学習されないので、ちょうど良いところを見つけるのが良いでしょう。
⑩Max resolution
この項目は画像の最大サイズです。ここで指定したサイズ以上の画像は自動でリサイズされます。
SD1.5系のモデルでは512×512で大丈夫ですが、このサイズを上げると精度が上がるという報告もあるため、VRAMに自信があるのならあげてみても良いかもしれません。

⑪Network Rank (Dimension)
この項目はネットワークのランクです!!よく分かりません!!
大きくすると細かいところまで学習する(?)ただしVRAM使用量が上がる。
32や64、128あたりでやっている方が多いようです。
⑫Network Alpha
よく分かりません!ただしNetwork Rankより大きな数値を設定するのはダメみたいです。
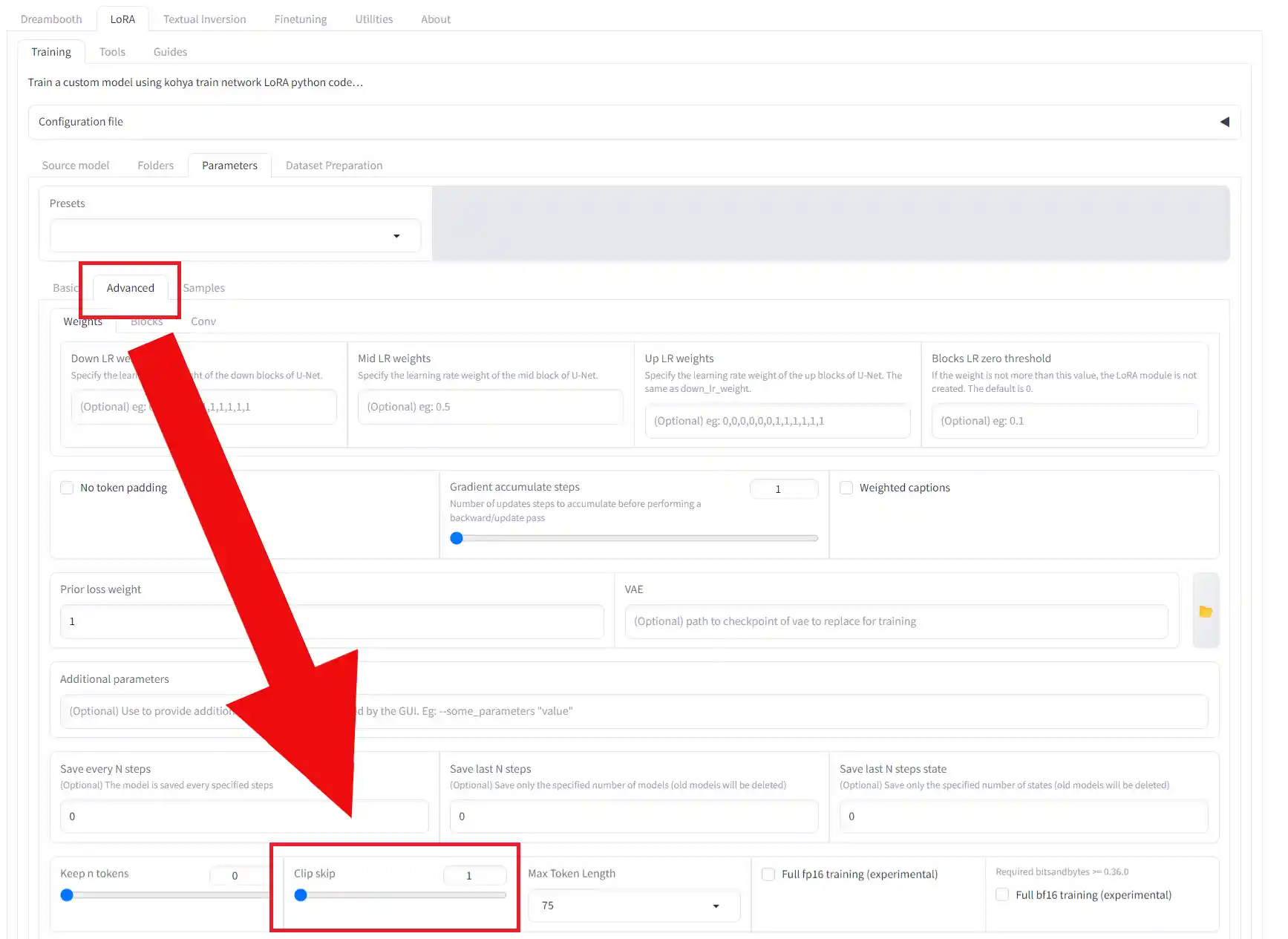
⑬Clip skip
この設定は「Advanced」タブの中にあります。
アニメ系のモデルでは、Clip Skipを2にするのが良いそうです。
基本的な設定はこれくらいですね。
SD1.5系とSDXL系での注意点
Max resolutionの注意点が1つあります。
SD1.5系のモデルでは「512,512」以上の数値を設定してください。
SDXL系のモデルでは「1024,1024」以上の数値を設定してください。
当然ですが、学習に使う画像サイズもそれ以上のものを用意してください。上記の数値以下の画像でも学習は出来ますが、うまく学習できないことが多いです。
4.学習開始
それではいよいよ学習開始です。「Start training」ボタンをクリックしましょう。
学習が開始されると、コマンドプロンプトの方に進捗が反映されます。
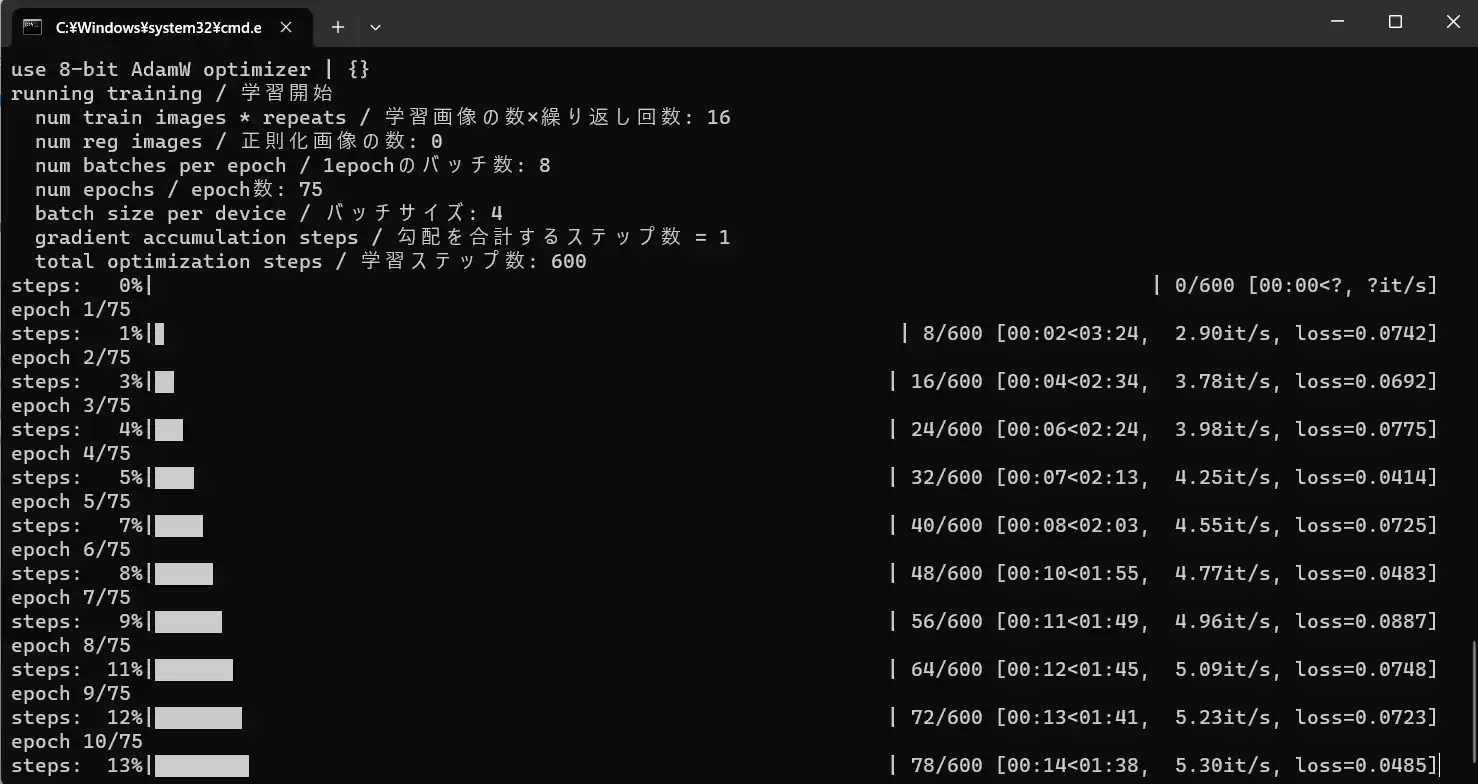
終わるまで待ちましょう。
5.前回の学習済みデータから続ける
既に学習済みのLoRAファイルをさらに学習させたい場合に使います。
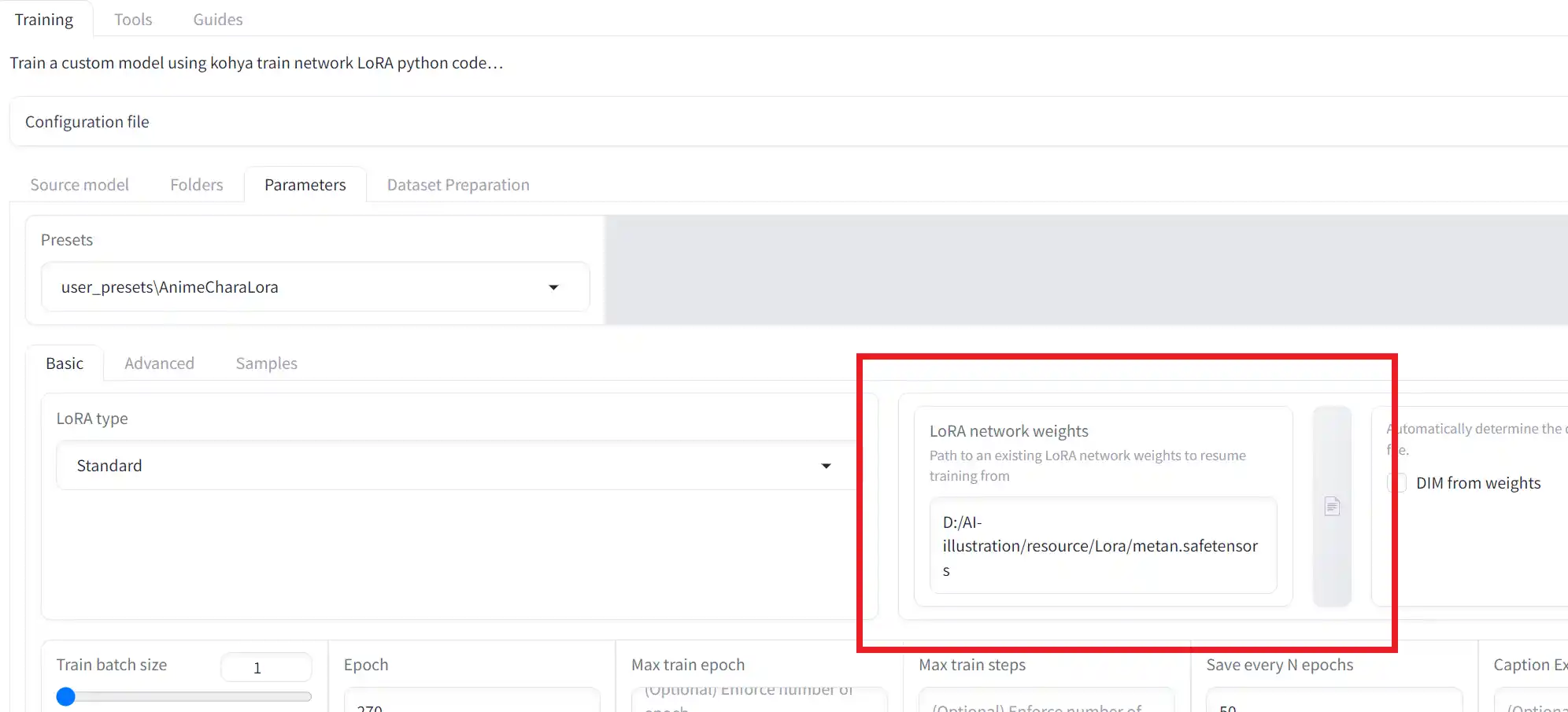
LoRA network weightsという項目に、学習済みのLoRAファイルを指定するだけです。
6.学習結果の確認
学習が終わると、Output folderで指定したフォルダにLoRAファイルが保存されています。
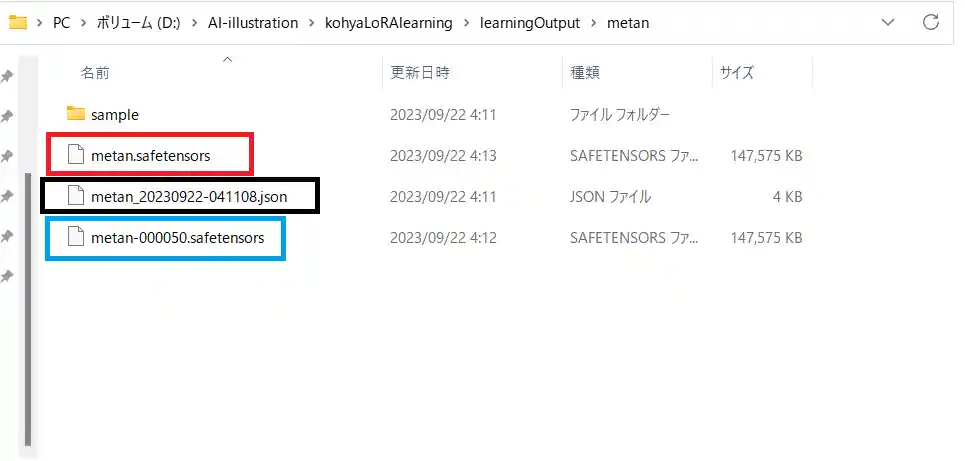
赤枠で囲ったファイルが、設定したEpoch数に到達したLoRAファイル。青枠で囲ったファイルが、Save every N epochsで設定した間隔で保存されたLoRAファイルです。
黒枠で囲った.jsonファイルは、今回の設定が保存されているファイルです。後述するやり方でこの設定を呼び出すことができます。
7.保存された.jsonファイルと使い方
それでは、学習結果と同時に保存されたjsonファイルの使い方です。
使い方は簡単で、kohya_ss GUIの上の方にあるConfiguration fileから保存された.jsonファイルを選択するだけです。これで設定が読み込まれます。
8.学習設定の保存
うまくいった設定は、よく使う設定としてプリセットに保存しましょう。
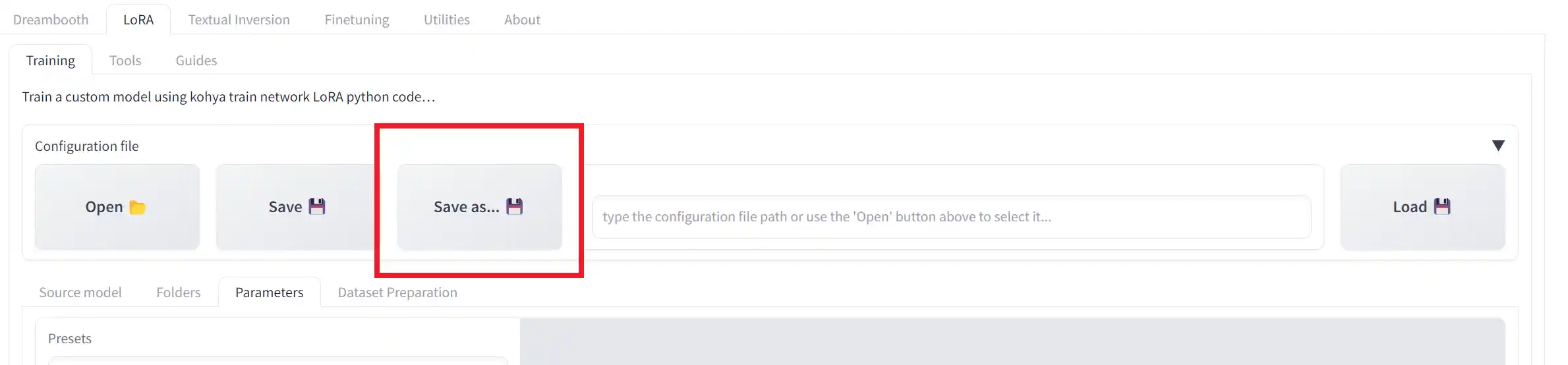
まず、各項目の設定が完了したら、Configuration fileから「Save as…」をクリックします。
そうすると保存場所を聞かれるので「user_presets」フォルダに保存します。
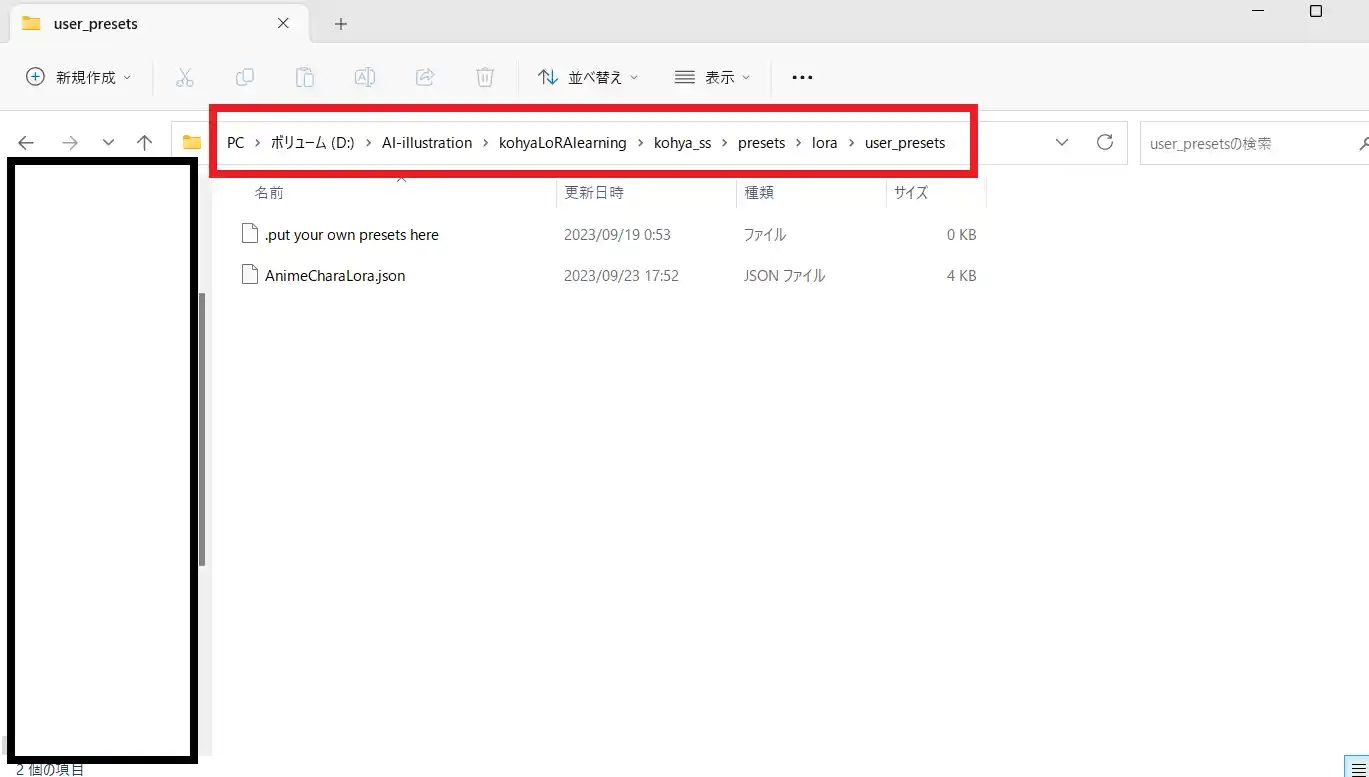
場所は「kohya_ss\presets\lora\user_presets」です。
保存場所はどこでも良いですが、presetsフォルダに保存することで、kohya_ss GUIの「Presets」一覧に表示されるようになります。
スポンサーリンク
9.画像生成
1.学習モデルと同じモデルで生成
それでは、画像生成です。LoRAの適用方法などは割愛し、生成画像とプロンプトだけ載せます。

いい感じに学習することが出来ました。この画像のプロンプトは以下の通りです。
masterpiece,best quality,metan <lora:metan:1>,school uniform2.学習モデルとは違うモデルで生成

プロンプトは変えずにモデルだけ変えました。
ほぼ同じ画風ですね。恐らく、同じ画風の画像を学習用画像にしたからだと思われます。
画風をモデルにより変えたい場合は、学習設定を調整したり、学習用画像の画風をいろいろ用意するのが良さそうです。
10.LoRAファイルのメタデータを削除する方法2選
作成したLoRAファイルには、学習時に使用したモデルや各パラメーターなどがメタデータとして残されています。

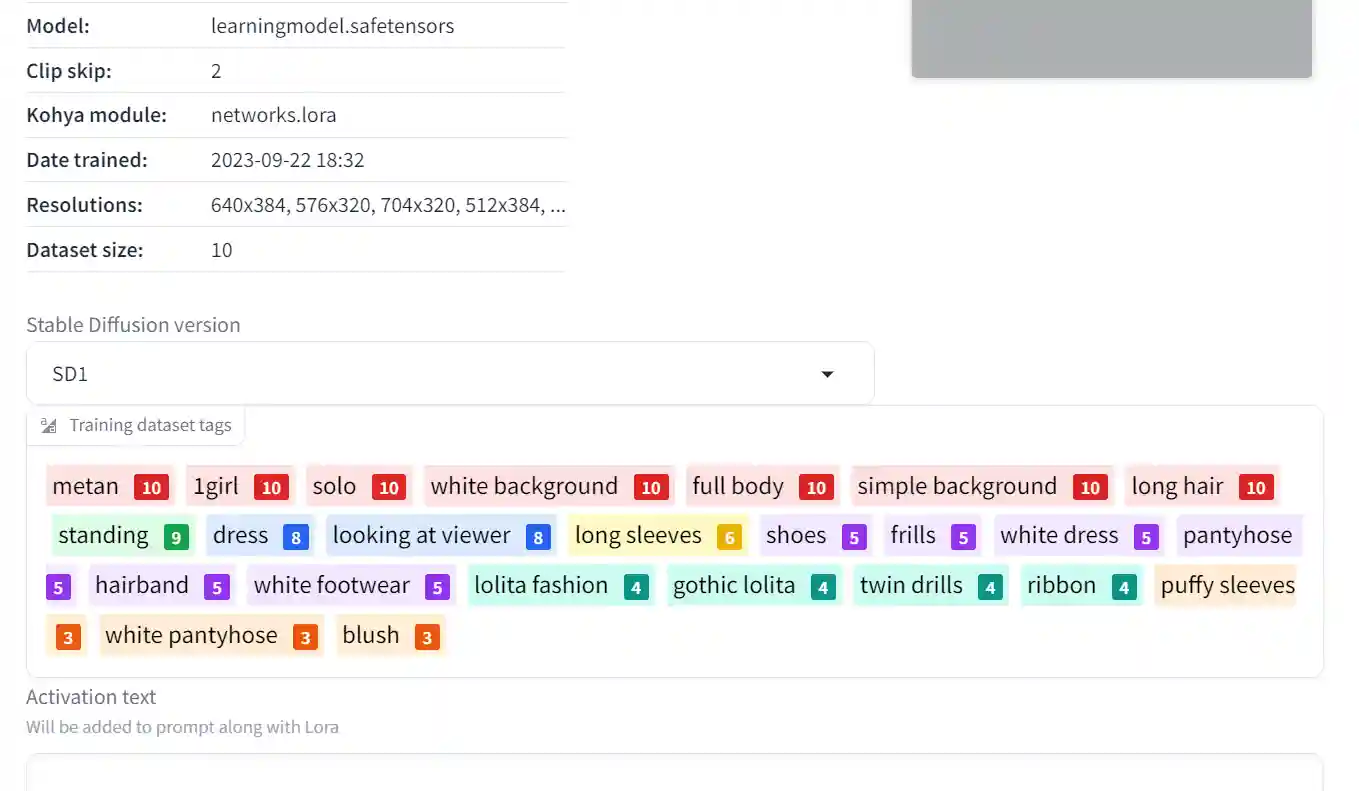
左が学習設定、右がキャプションファイルに用いたタグですね。
基本的に消すことはありませんが、LoRAファイルを配布するときに設定を明かしたくないという方に向けて、メタデータの削除方法を解説していきます。
1.メタデータの削除1
まず、どのような結果になるのかお見せします。
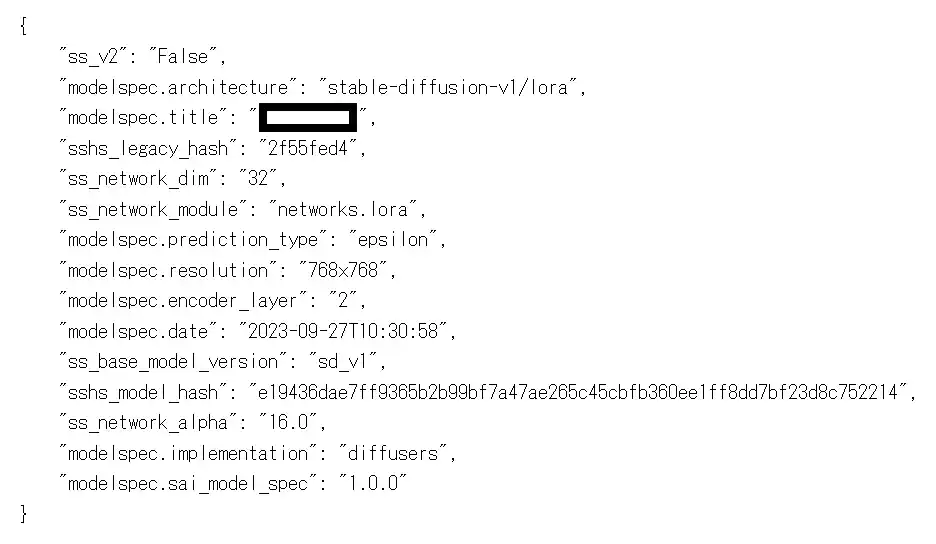
メタデータはこれだけしか保存されていません。
それではやり方です
1.Additional parametersを設定する
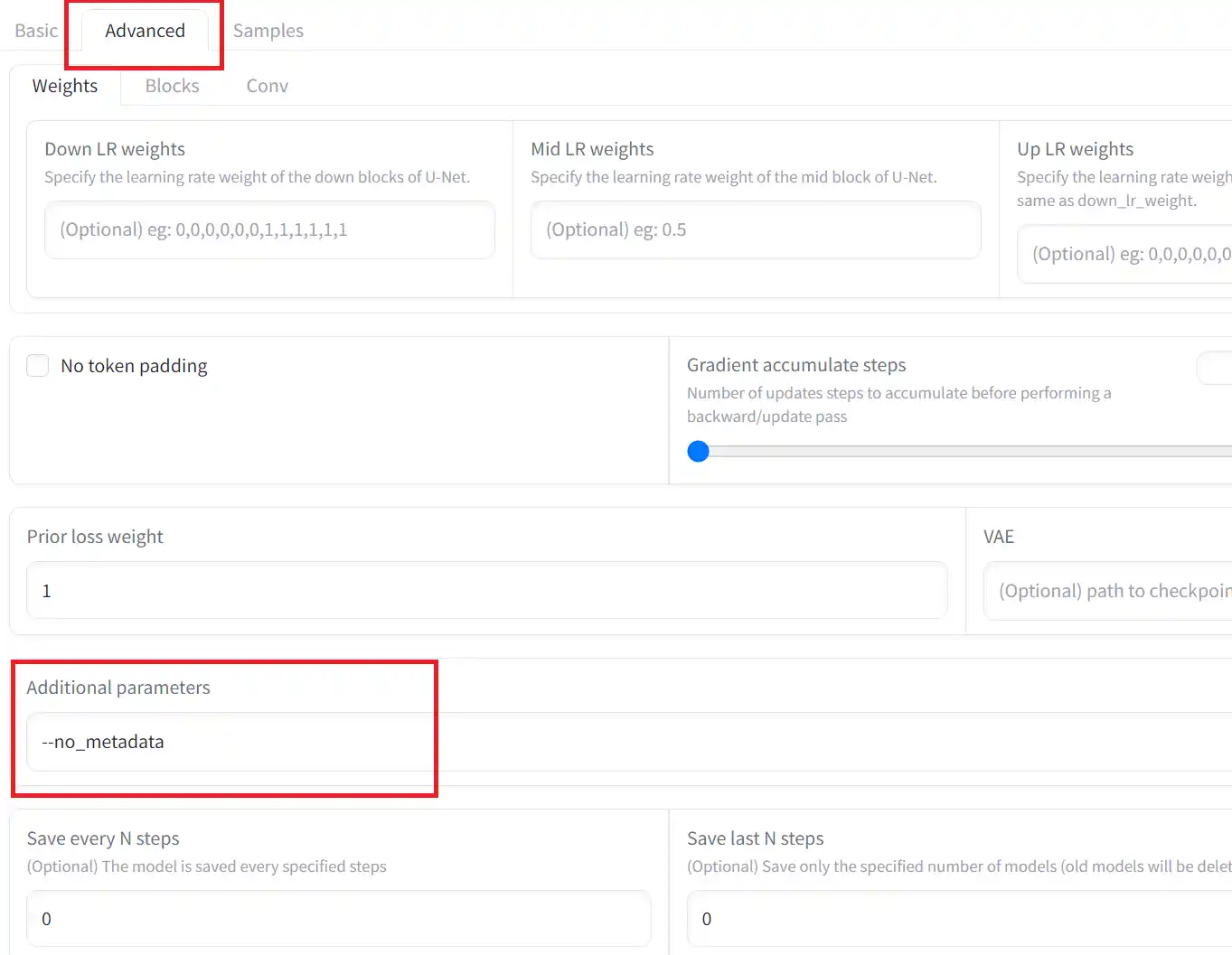
「Adbanced」タブにある「Additional parameters」の項目に”–no_metadata“と入力するだけ。このまま学習を開始すれば学習時の設定はメタデータとして保存されません。
“-“は2つ続けて入力してください。
2.メタデータの削除2
前項では、学習内容まわりのみの削除でしたが、こちらのやり方はLoRAに関することをすべて削除できます。
まず、学習実行の項目で説明したように、LoRAの保存形式をckptファイルにする必要があります。出力されたLoRAファイルがckptファイルが確認してください。
また、厳密にいうと、ckptファイルの時点でメタデータは保存されていません。
では、この手順は必要ないのでは?と思うかもしれません。ckptファイルのまま配布するのであれば必要ありませんが、現在主流の配布形式はsafetensorsです。これはckptファイルと比べて、セキュリティ面で優れてるからです。
また、最初からsafetensorsで出力し、それをメモ帳などのテキストエディターで開きメタデータ部分だけ削除というやり方だと、LoRA適応時の生成結果に悪影響が出るためおすすめしません。
1.LoRAファイルをマージする
やることは簡単です。web-uiに標準搭載されているマージ機能でマージするだけです。
手順は以下の通り。
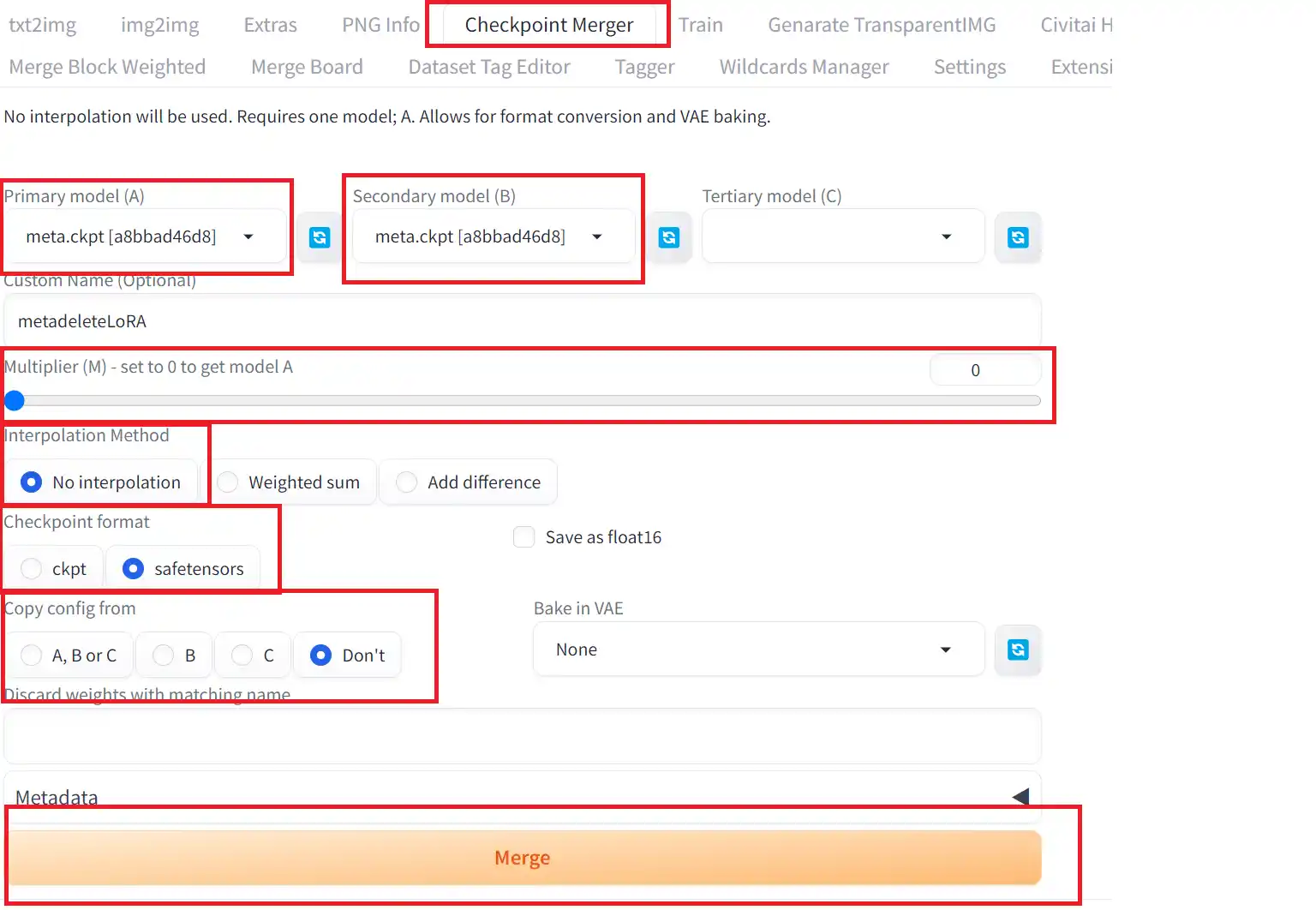
①「Checkpoint Merger」タブを開く
②「Primary model(A)」と「Secondary model(B)」の項目に同じLoRAファイルを指定する
③「Multiplier (M) – set to 0 to get model A」の項目を0に設定する
④「Interpolation Method」の項目をNo interpolationにチェックを入れる
⑤「Checkpoint format」の項目をsagetensorsにチェックを入れる
⑥「Copy config from」の項目をDon’tにチェックを入れる
あとは出力されたファイルの名前を決めてマージボタンを押すだけです。
最後に出力されたLoRAファイルをLoRA用のフォルダに移して完了です。
これでLoRAに関するメタデータを消して配布することが出来ます。
11.SDXL(ANIMAGINE XL 3.0)の画風LoRA作成時の注意点
SDXL系モデル(もしかしたらANIMAGINE XL 3.0だけかも?)で画風LoRAを作成する時は、2.キャプションファイルの作成の項目でキャプションを付ける際にAdditional tagsの項目を入力してください。
SD1.5系のモデルでは未入力の状態でもそれなりに学習画風で生成出来たのですが、SDXL系では生成されないことが多いです。
また、入力するワードは呼び出しタグになるので自由に決めてください。
次に、生成時の注意点ですが、プロンプトからmasterpieceやbest qualityなどのクオリティタグは削除した方が画風LoRAの効果がより効くように思えます。クオリティタグありでも問題なく効果が出ているのであれば外す必要はないです。
12.ローカルで学習するのにおすすめのグラボ
1.RTX3060 (12GB)

画像生成AIではVRAMが重要視されるため、12GBあるRTX3060はstable diffusion登場時からコスパが良いグラボと言われています。ローカルでLoRA学習したいけどグラボの性能が足りてない、だけどグラボに使える予算も少ない、という方におすすめです。
3.RTX4060 Ti (16GB)

ゲーム用途ではあまり良い評価を聞かないグラボですが、LoRA学習に於いてはこのVRAM量が役に立ちます。生成用途でもVRAM消費の多いSDXL系のモデルを動かすことが出来るので、画像生成AIのグラボですね。ただし、SDXL系以外のモデルでの生成速度はあまり期待できません。
生成速度も重視したいのであれば、VRAMが12GBのRTX4070を検討しても良いでしょう。
4.RTX4090

とりあえず生成も学習も最高の環境でやりたいのであればこれしかないですね。
VRAMも24GB載っているので最強と言っていいでしょう。厳密にいうと32GBや48GBのVRAMを載せたグラボもありますが、グラボ単体で70万くらいするので個人が画像生成AI用で購入するのは現実的ではありません。
最後に
これでモデルだけでは生成できないキャラや画風を生成できるようになり、より一層、画像生成AIで作る作品の幅が広がりましたね。
それでは!

コメント
学習開始時に書きメッセージが出て開始されません。解決方法はございますでしょうか。
Fatal error in launcher: Unable to create process using ‘”C:\Users\hayabusa\Desktop\kohya_ss GUI\kohya_ss\venv\Scripts\python.exe” “C:\Users\hayabusa\Desktop\kohya_ss_GUI\kohya_ss\venv\Scripts\accelerate.exe” launch –dynamo_backend no –dynamo_mode default –mixed_precision fp16 –num_processes 1 –num_machines 1 –num_cpu_threads_per_process 2 “C:/Users/hayabusa/Desktop/kohya_ss_GUI/kohya_ss/sd-scripts/sdxl_train_network.py” –config_file “./outputs/tmpfilelora.toml”‘: ??????????????????