
先日、ComfyUIの導入と使い方について記事を書きました。しかし、先日の記事では導入方法とデフォルトのワークフローでの生成しか説明しておらず、新しいノードの配置や線の繋ぎ方については全く触れていませんでした。
なので、今回の記事では、LoRAとワイルドカードを使用してtxt2imgで生成した画像をimg2imgで処理し、それをFaceDetailerを使用し顔を整え、最後にアップスケールを1クリックで出来るワークフローを組んでいこうと思います。
カスタムノード(拡張機能)のインストール
まずはカスタムノードをインストールしましょう。
絶対に使うカスタムノードと、使わなくても問題ないがあると便利なカスタムノードがあるので、分けて紹介します。
また、この記事はここで紹介しているカスタムノードがインストールされている事を前提として書いています。
カスタムノードのインストール方法については【AIイラスト】ComfyUIの導入と使い方を解説【stable diffusion】で説明しているので、そちらをご覧ください。
必須カスタムノード
・ComfyUI-Impact-Pack
ワイルドカードとFaceDetailerを使うために必要なカスタムノードです。
・ComfyUI-KJNodes
このカスタムノードを必須にするかどうか迷いましたが、この記事ではこのカスタムノードで追加されるset,getノードの使用を前提で解説していくので、必須に入れました。
あると便利なカスタムノード
・ComfyUI-WD14-Tagger
画像からdanbooruタグを解析するノードを追加できます。
・ComfyUI-TiledDiffusion
A1111版webuiの拡張機能「multidiffusion-upscaler-for-automatic1111」と同じような機能を使えるようになります。
・rgthree-comfy
生成した画像を比較できるノードを追加できます。FaceDetailerで処理した後と前を比較出来るので便利です。
ワイルドカードファイルの設定
ワイルドカードを.txtファイルで管理する場合は、以下のフォルダに.txtファイルを格納します。
ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-Impact-Pack\wildcards.txtファイルの書き方はA1111版webuiのワイルドカードと同じなので割愛します。
ノードの追加方法
追加方法1
画面のなにもないところでダブルクリックし、出てきたウィンドウの検索バーに必要なノード名を入力します。
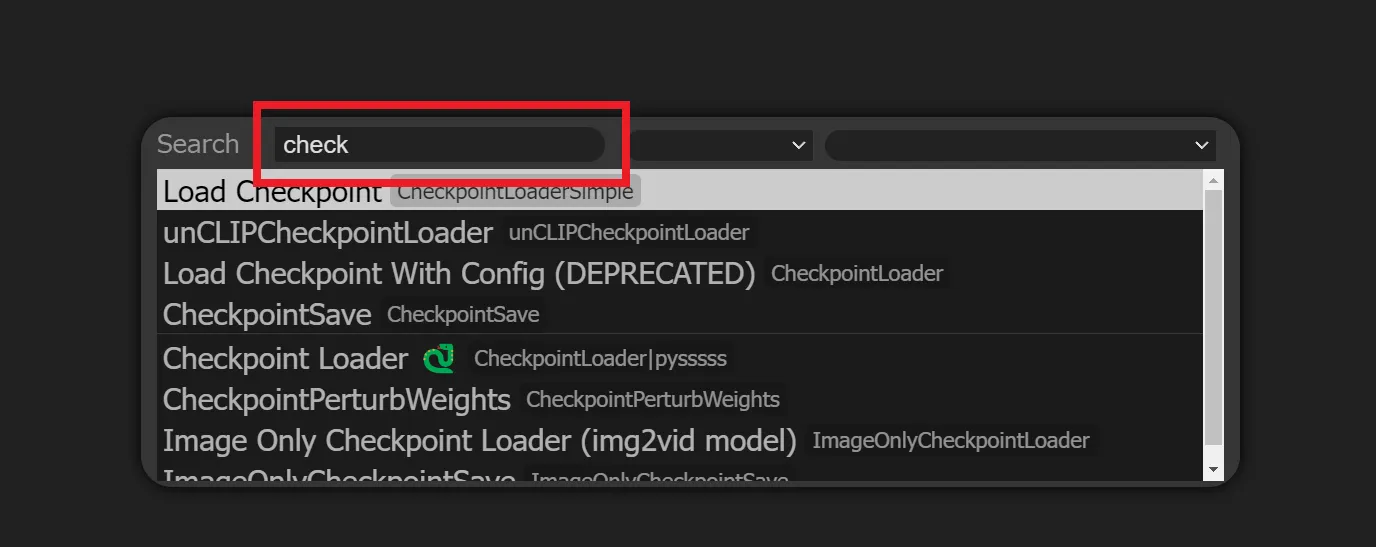
必要なノードをクリックするとノードが追加されます。
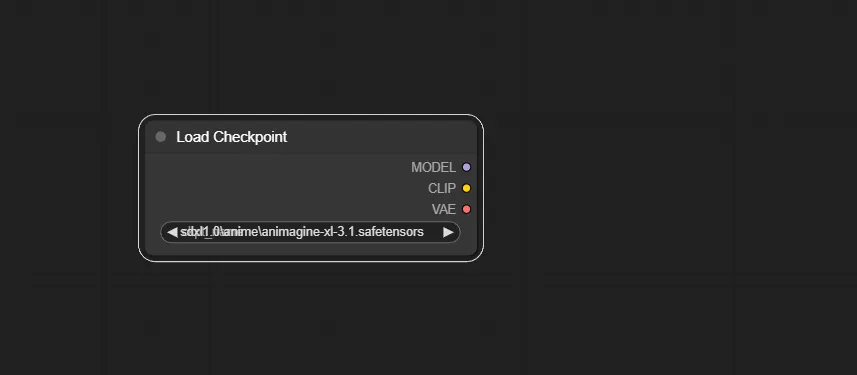
追加方法2
なにもないところで右クリックし、出てきたメニューから「Add Node」をクリックし、必要なノードを選択するとノードを追加できます。
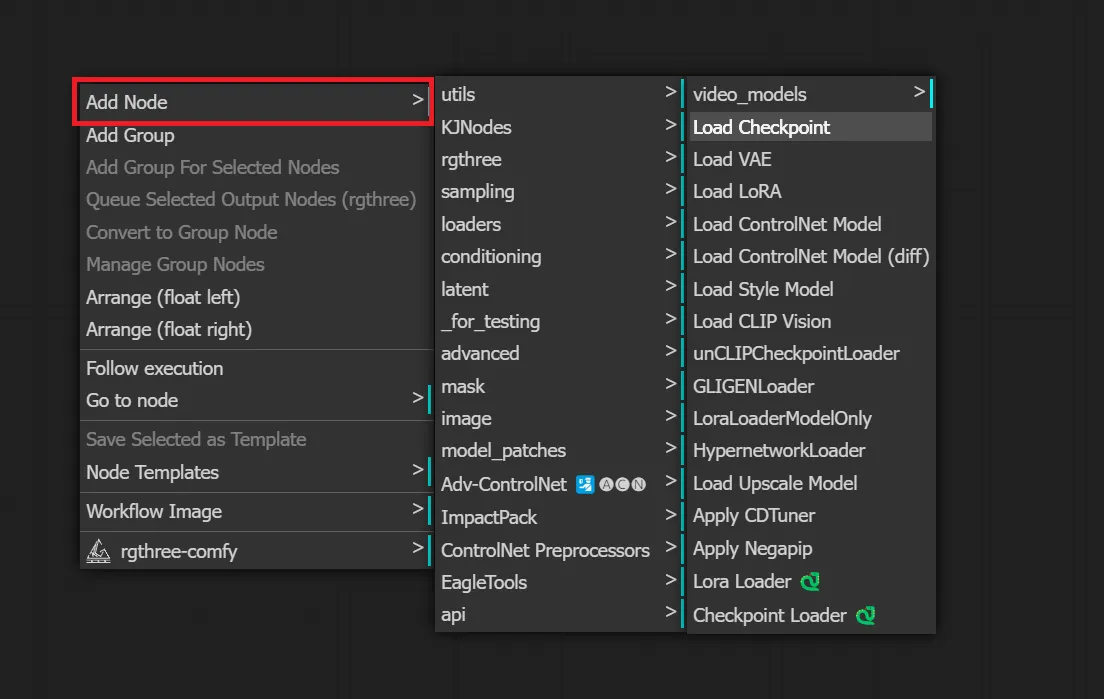
このやり方では、追加したカスタムノードごとに分かれているので、カスタムノードで追加したノードを探したい時に便利です。
スポンサーリンク
ワークフローの構築
それではワークフローを組んでいきます。デフォルトのtxt2img用のワークフローを改変して使っても良いですが、今回は白紙の状態から組んでいきます。
txt2img部分の構築
まずは基本となるtxt2imgで画像を生成する為の部分を作成していきます。
1.Load Checkpoint ノードを追加する
まずはチェックポイントを読み込む為のノードである「Load Checkpoint」を追加します。
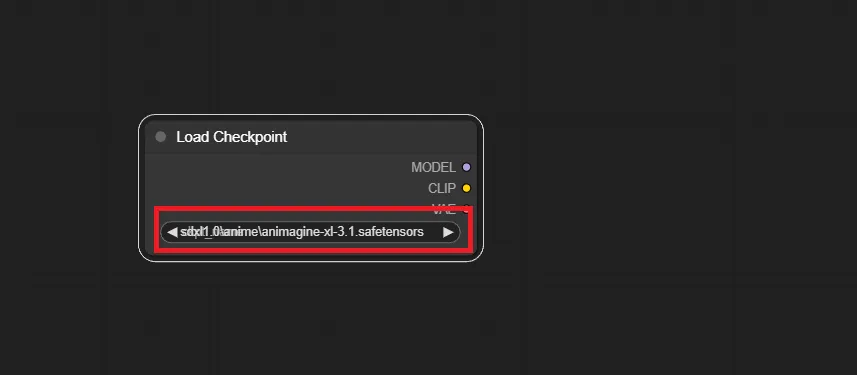
赤枠で囲った部分をクリックすることで、使用するモデルを選択できます。
2.Load LoRA ノードを追加する
LoRAを使用する為のノード「Load LoRA」を追加します。A1111版webuiと違い、プロンプトに入力するだけでは使えず、それようのノードを追加する必要があります。
LoRAを使用しないのであれば、このノードは不要です。
3.Load Checkpoint ノードとLoad LoRA ノードを繋ぐ
最初に追加したLoad CheckpointとLoad LoRAを繋ぎます。
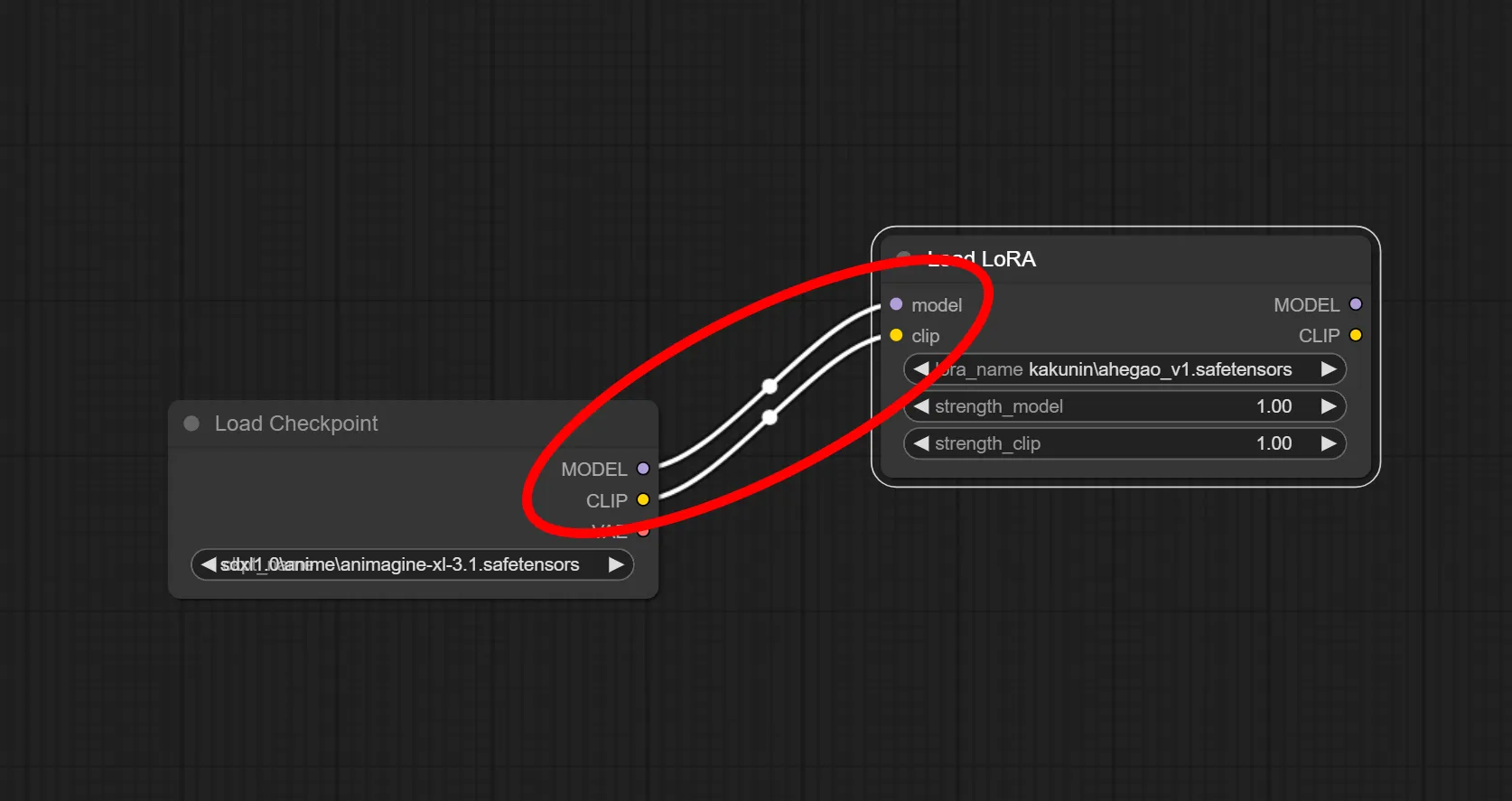
Load Checkpointの “MODEL” から Load LoRAの “model” 、Load Checkpointの “CLIP” から Load LoRAの”clip”へそれぞれ線を繋ぎます。
4.CLIP Text Encode(Prompt) ノードを2つ追加する
次に、プロンプト入力用のノード「CLIP Text Encode(Prompt)」を2つ追加します。
2つ追加するのは、1つがポジティブプロンプト、1つがネガティブプロンプトとなる為です。
ちなみに、この時点ではどちらがポジティブプロンプトで、どちらがネガティブプロンプトかは決まっていません。
1つ追加したら、ノードをクリックし「Ctrl」+「C」を押してから「Ctrl」+「V」か、ノードを右クリックし、出てきたメニューから「Clone」を選択することで、コピペが出来ます。
5.Load LoRA ノードとCLIP Text Encode(Prompt) ノードを繋ぐ
Load LoRA ノードの “Clip” から CLIP Text Encode(Prompt)の “Clip” へと繋ぎます。
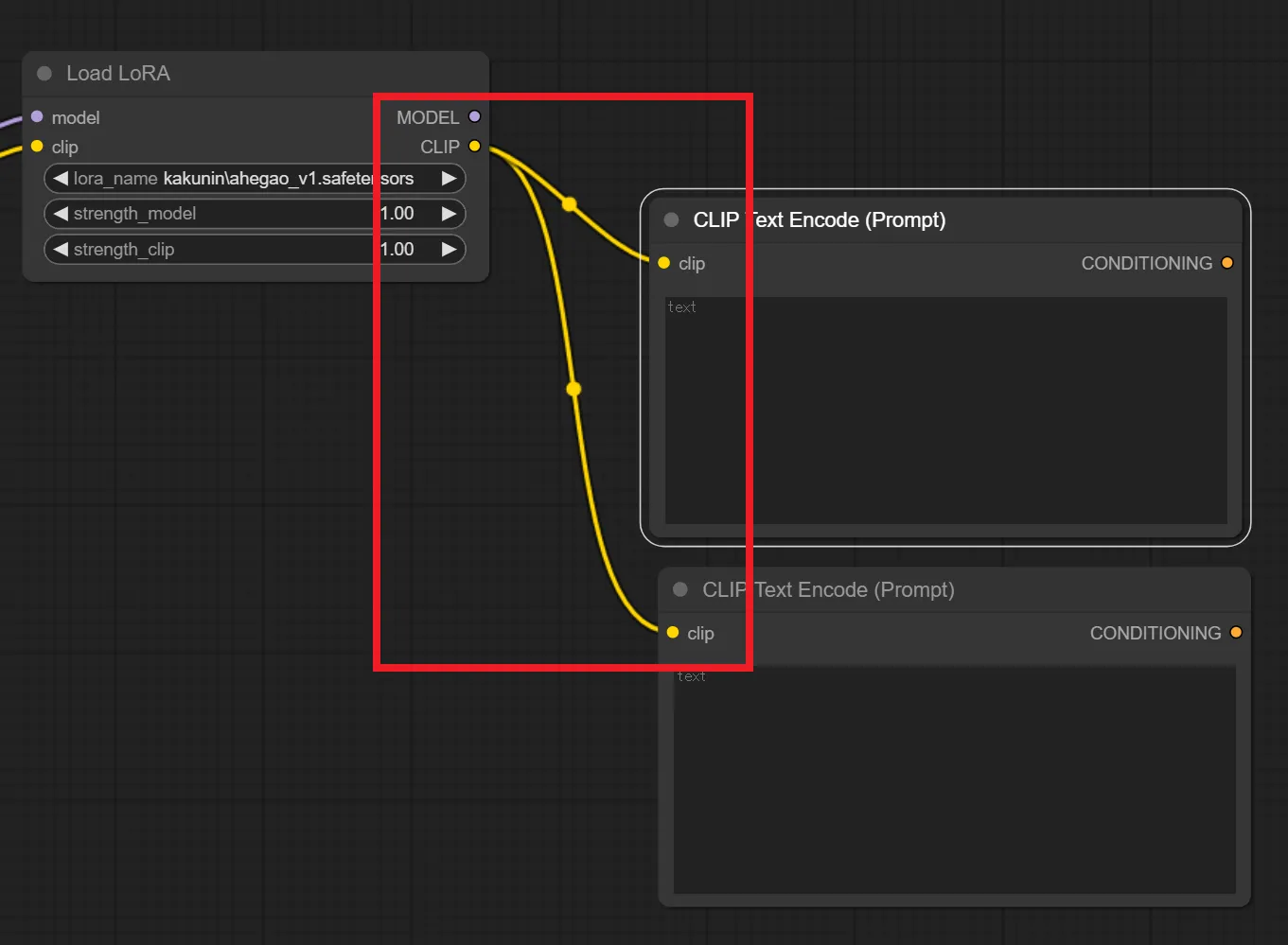
これでLoRAを適用できます。
6.KSampler ノードを追加する
生成時の設定を入力する為のノードである「KSampler」を追加します。
設定項目はA1111版webuiでも同じような箇所があるので、説明は不要ですね。
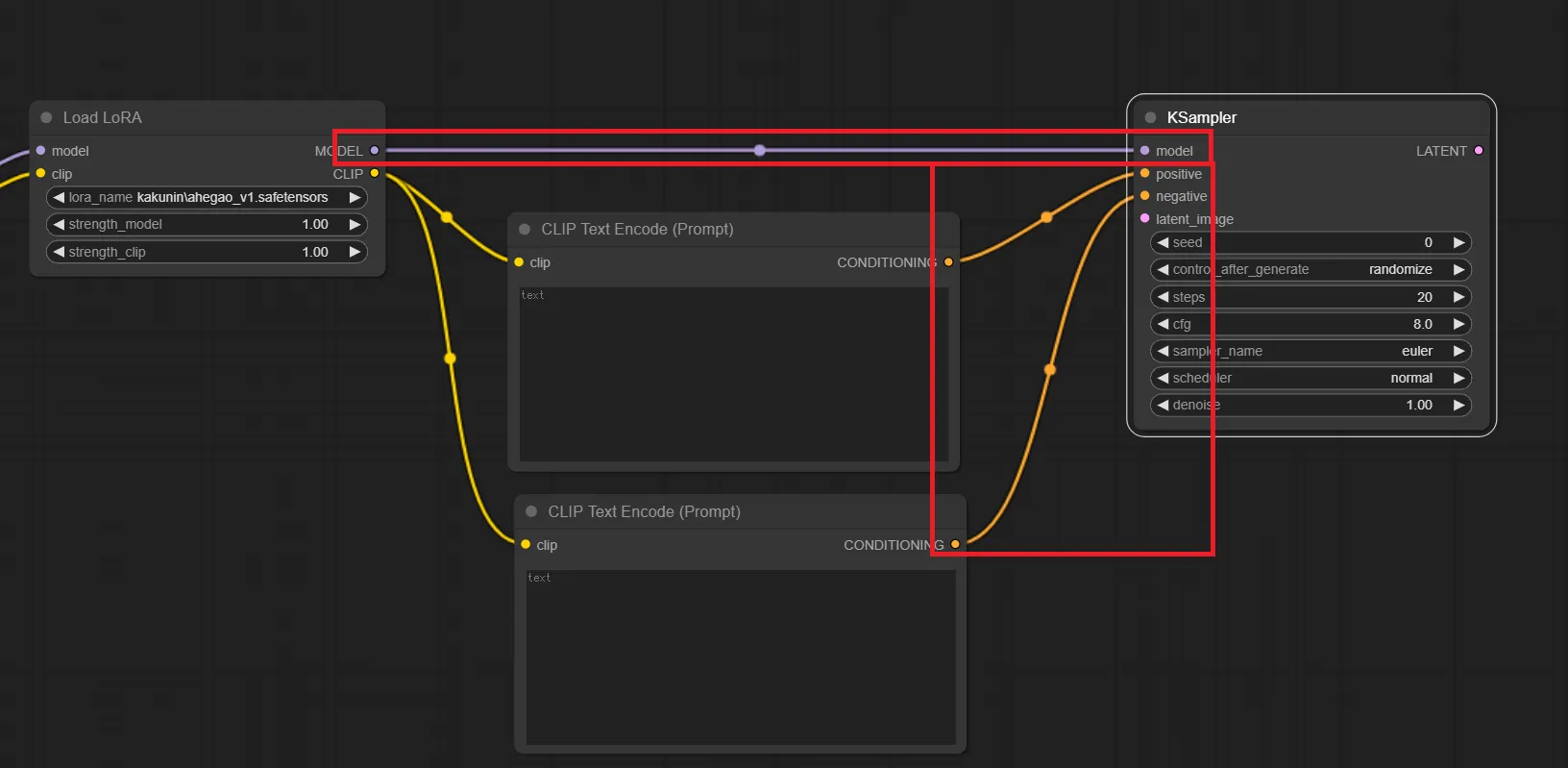
7.KSamplerを各ノードと繋ぐ
Load LoRAの “MODEL” から KSamplerの “model” へと繋ぎ、CLIP Text Encode(Prompt) の “CONDITIONING” から KSampkerの “positive” もしくは “negative” へと繋ぎます。
文字通りですが、ポジティブプロンプトとして使いたいCLIP Text Encode(Prompt)をpositiveへ、ネガティブプロンプトとして使いたいCLIP Text Encode(Prompt)はnegativeへ繋ぎます。
8.Empty Latent Image ノードを追加する
このノードは生成する画像サイズとバッチサイズを指定できます。
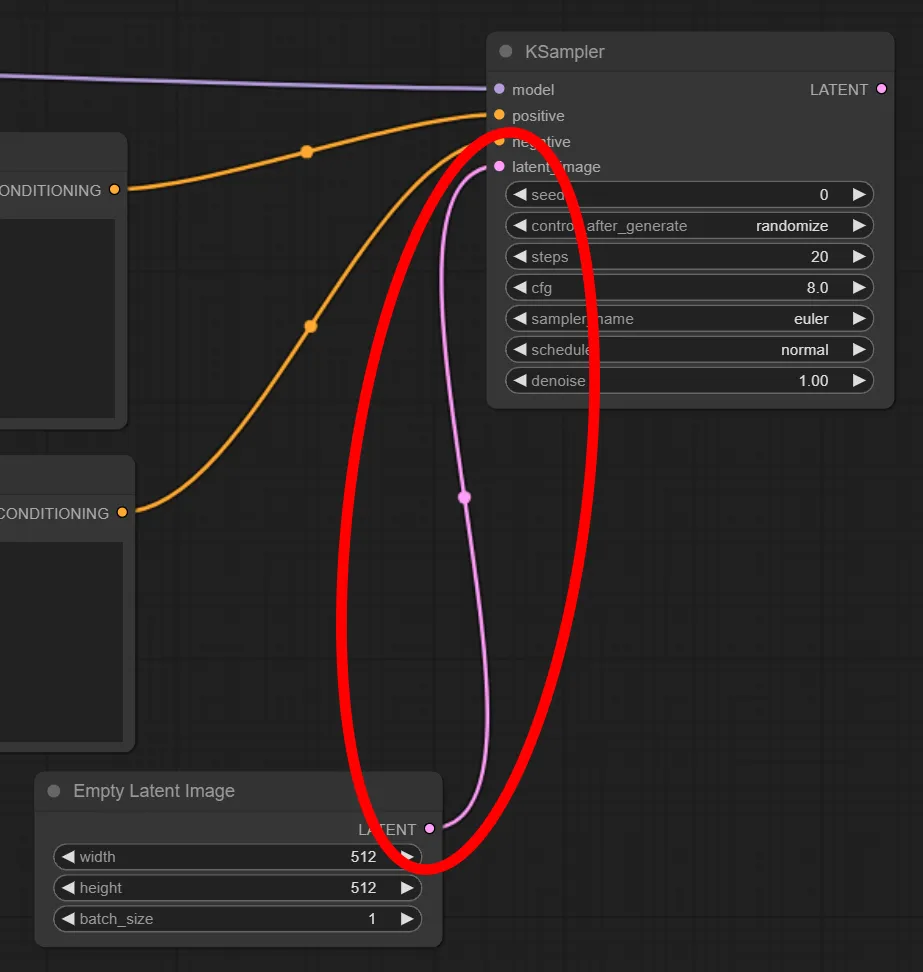
9.Empty Latent ImageをKSamplerと繋ぐ
Empty Latent Image の “LATENT” から KSampler の “latent_image” へ繋ぎます
10.VAE Decode ノードを追加する
KSamplerで生成しますが、その段階ではまだlatent画像という状態で、その状態では画像を見ることが出来ません。なのでそれを見れる形式(pixel画像)へ変換する必要があります。その役割がこのVAE Decodeです。

11.KSamplerとVAE Decodeを繋ぐ
KSampler の “LATENT” と VAE Decode の “samples” へ繋ぎます。
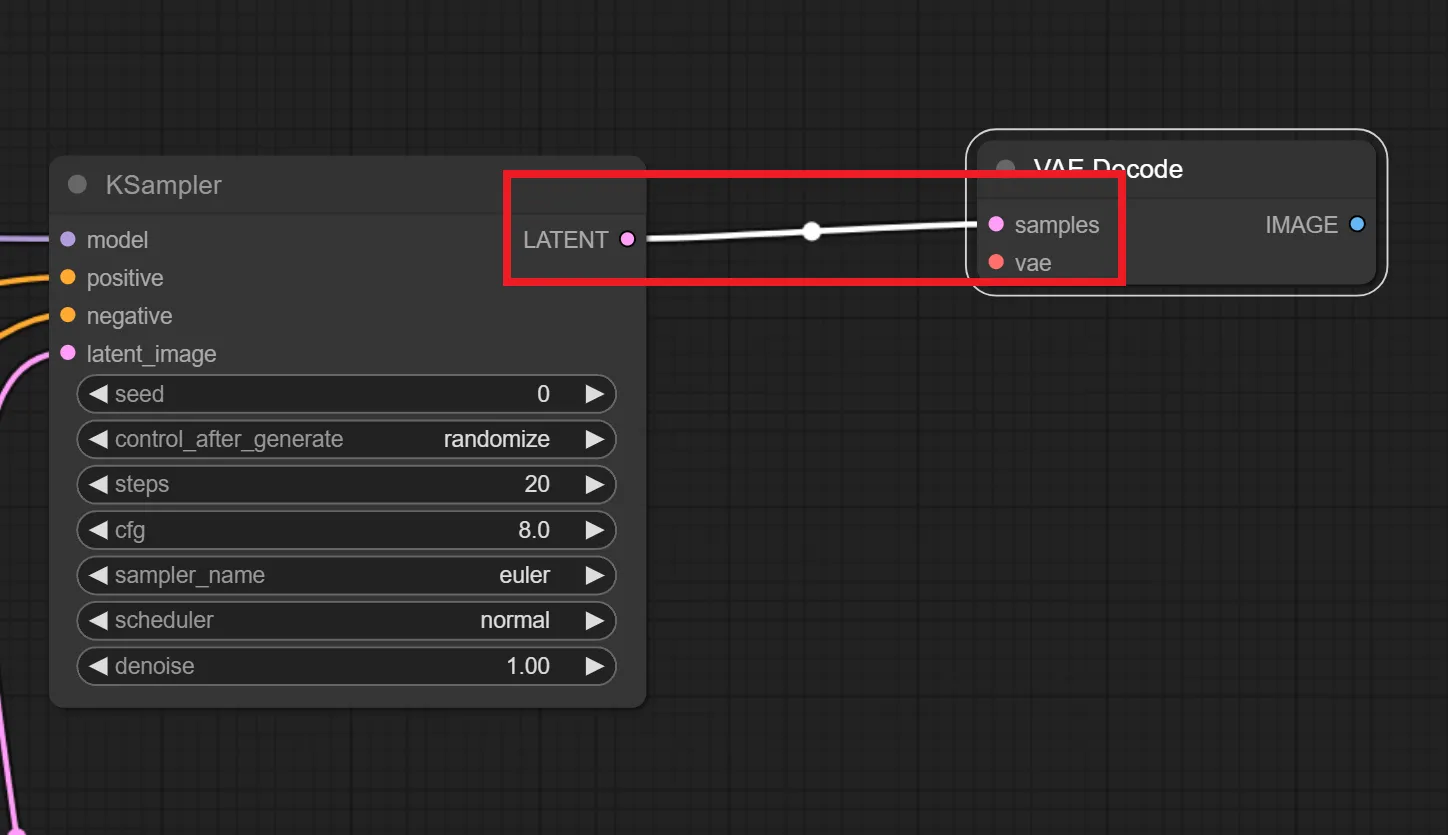
12.Load VAE ノードの追加
これは必須ノードではないですが、A1111版webuiでVAEを指定している方の方が多いと思うので、この記事では使用します。
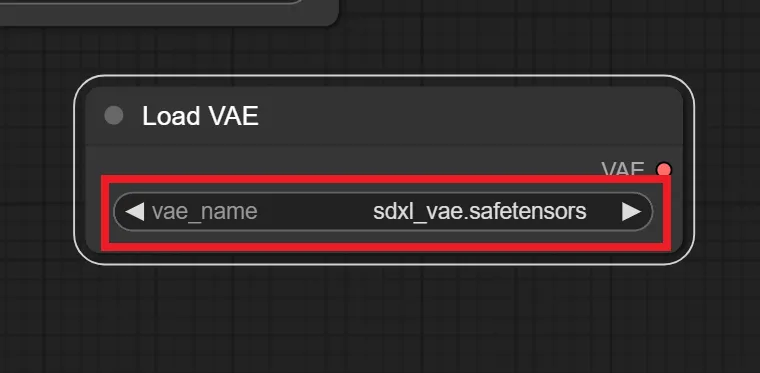
赤枠で囲った部分をクリックすることで、VAEを切り替えられます。
13.Load VAEとVAE Decodeを繋ぐ
Load VAE の “VAE” と VAE Decode の “vae” を繋ぎます。
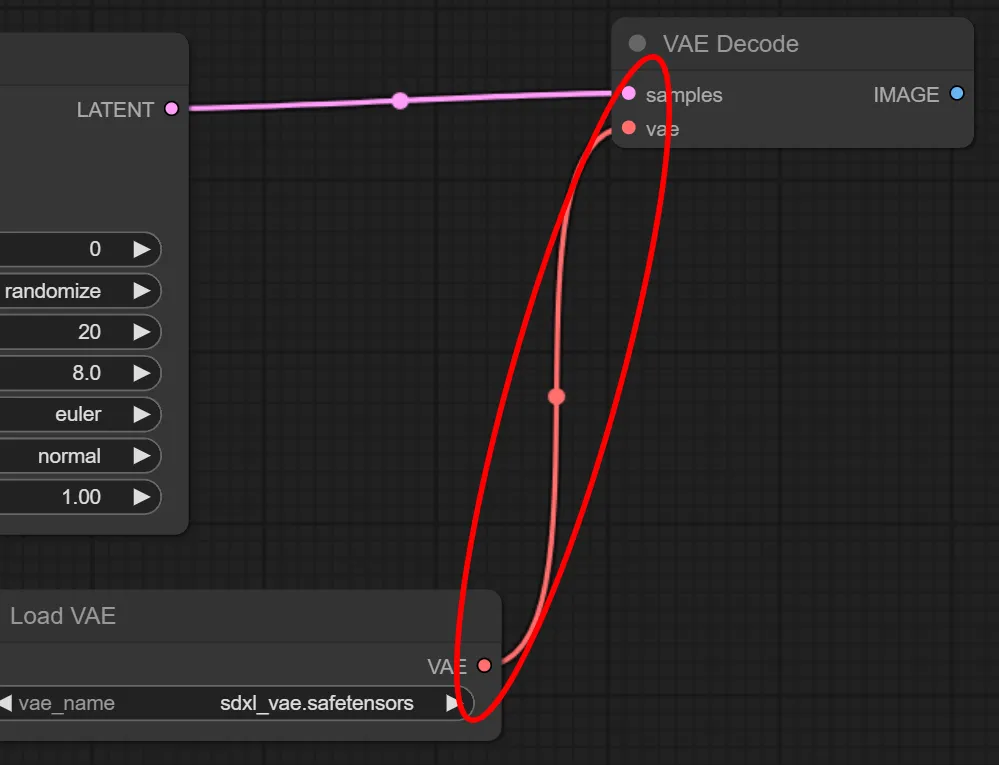
もし、Load VAE ノードを使用しない場合はLoad Checkpoint の “VAE” から VAE Decode の “vae” へと繋ぎます。
13.Preview Image、もしくはSave Image ノードを追加する
VAE Decodeで処理された画像を実際に見る為、保存する為のノードを追加します。
見るだけであればPreview Image ノードを追加、保存したければSave Image ノードを追加してください。
また、Preview Image ノードでも気に入った画像が生成された時は、Preview Imageノード上を右クリックして「Save Image」をクリックすることで保存できます。
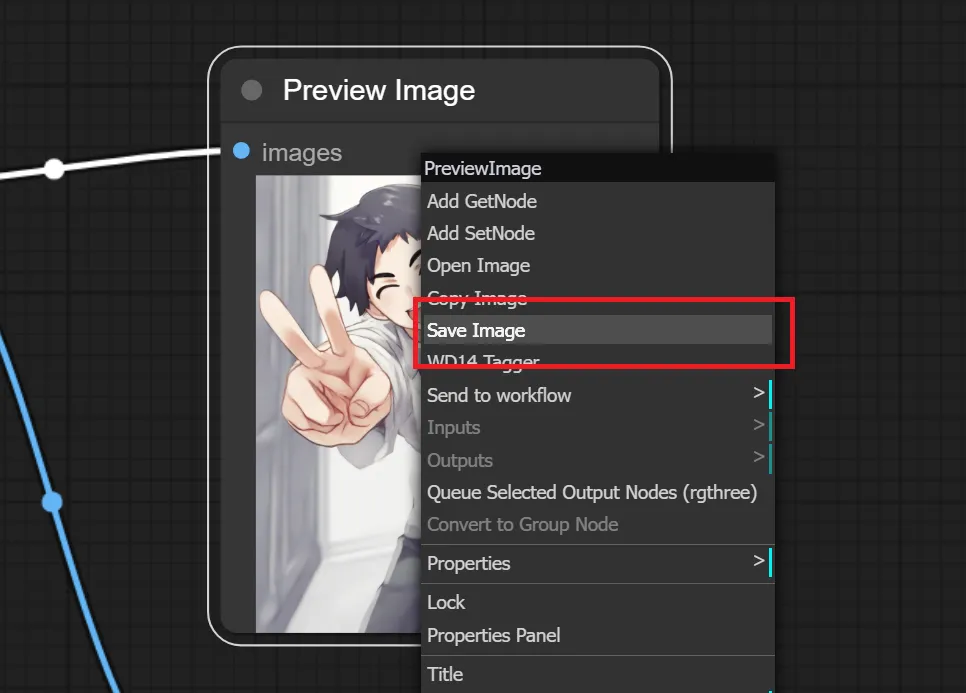
14.VAE DecodeとSave Image/Preview Imageを繋ぐ
VAE Decode の “IMAGE” と Save Image/Preview Image の “images” を繋ぎます。
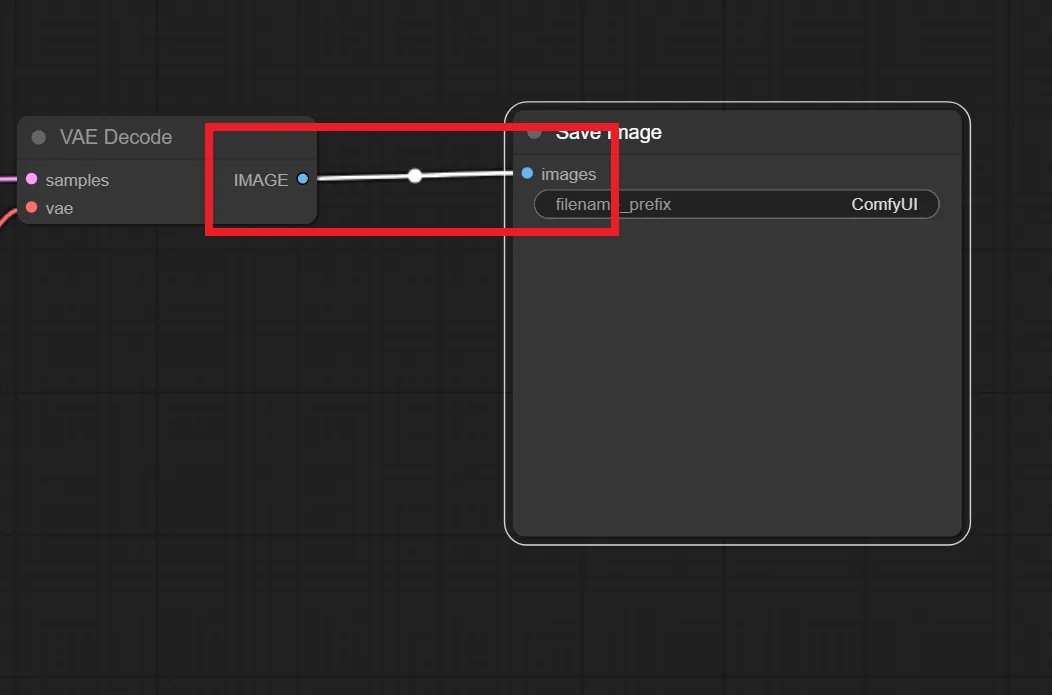
これで基本的なtxt2imgが出来るようになりました。
今回はワイルドカードも使用するので、ここからワイルドカード用のノードの追加と、既存ノードの変更をしていきます。
15.ImpactWildcardProcessor ノードを追加
A1111版webuiでは、そのままプロンプト欄にワイルドカード用のプロンプトを記入すれば良いのですが、ComfyUIではLoRAと同じように専用のノードを追加しなければなりません。
それがImpactWildcardProcessorです。
以降、プロンプトはImpactWildcardProcessorに入力していきます。
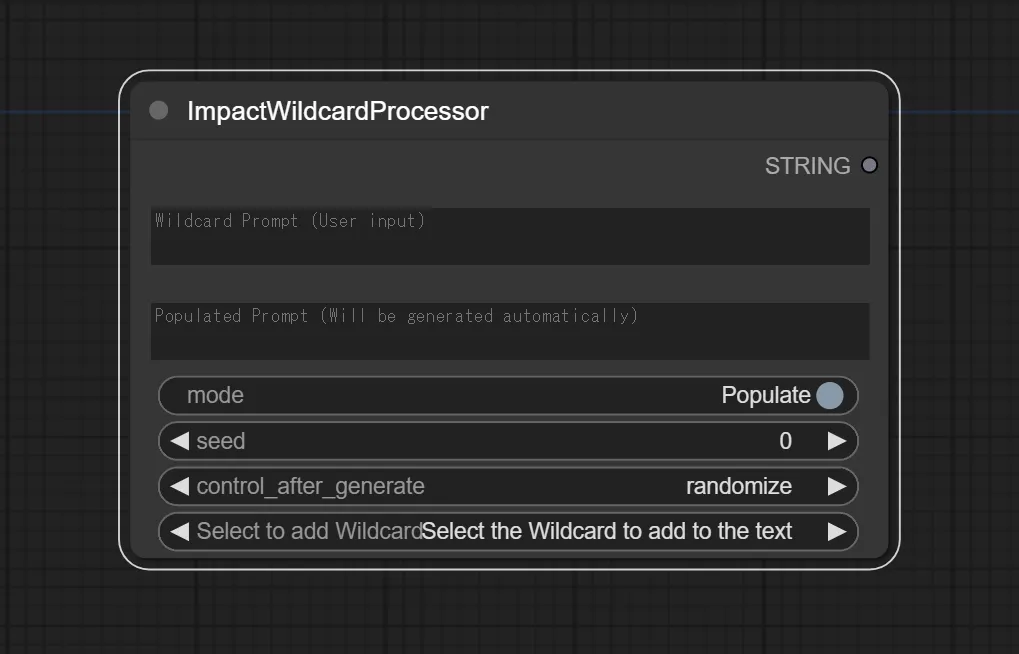
16.CLIP Text Encode(Prompt)を入力用へ変更する
ワイルドカードの効果を適用したいCLIP Text Encode(Prompt)ノードを右クリックし、「Convert Input to Widget」→「Convert text to Widget」をクリックします。
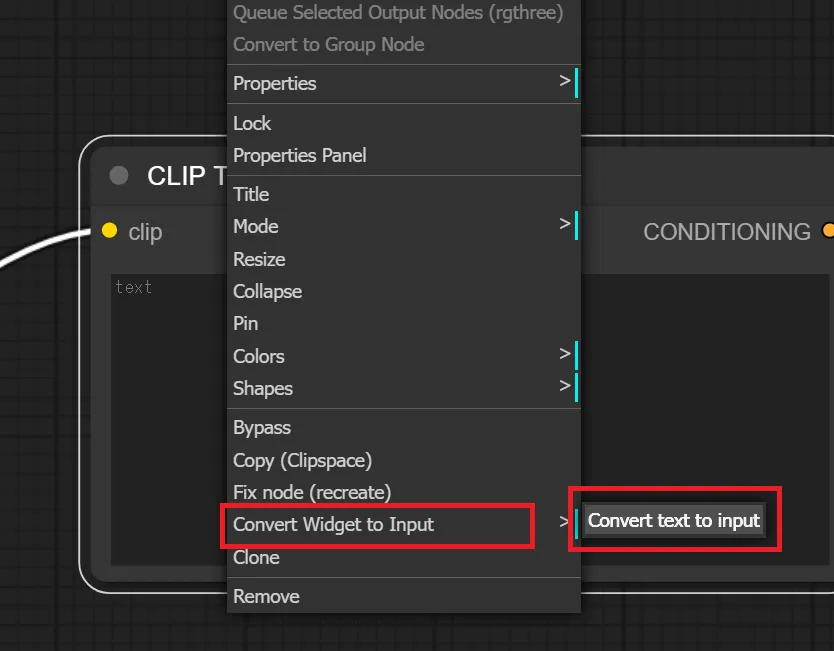
すると、以下のように変わります。
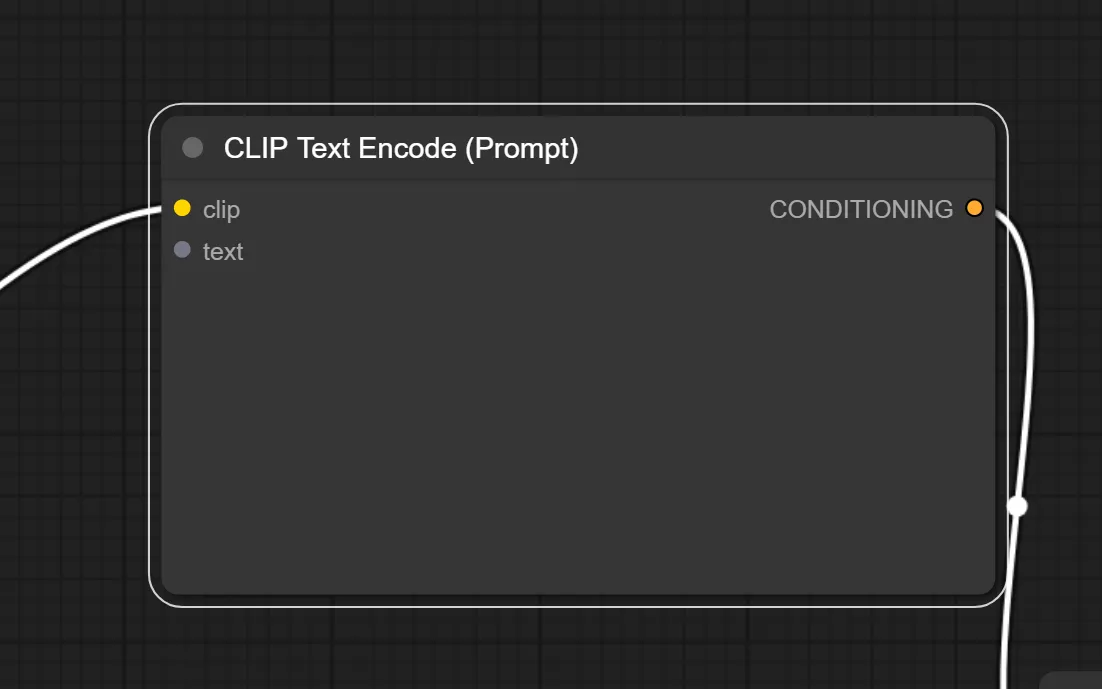
17.ImpactWildcardProcessorと CLIP Text Encode(Prompt)を繋ぐ
ImpactWildcardProcessor の “STRING” と CLIP Text Encode(Prompt) の “text” を繋ぎます。
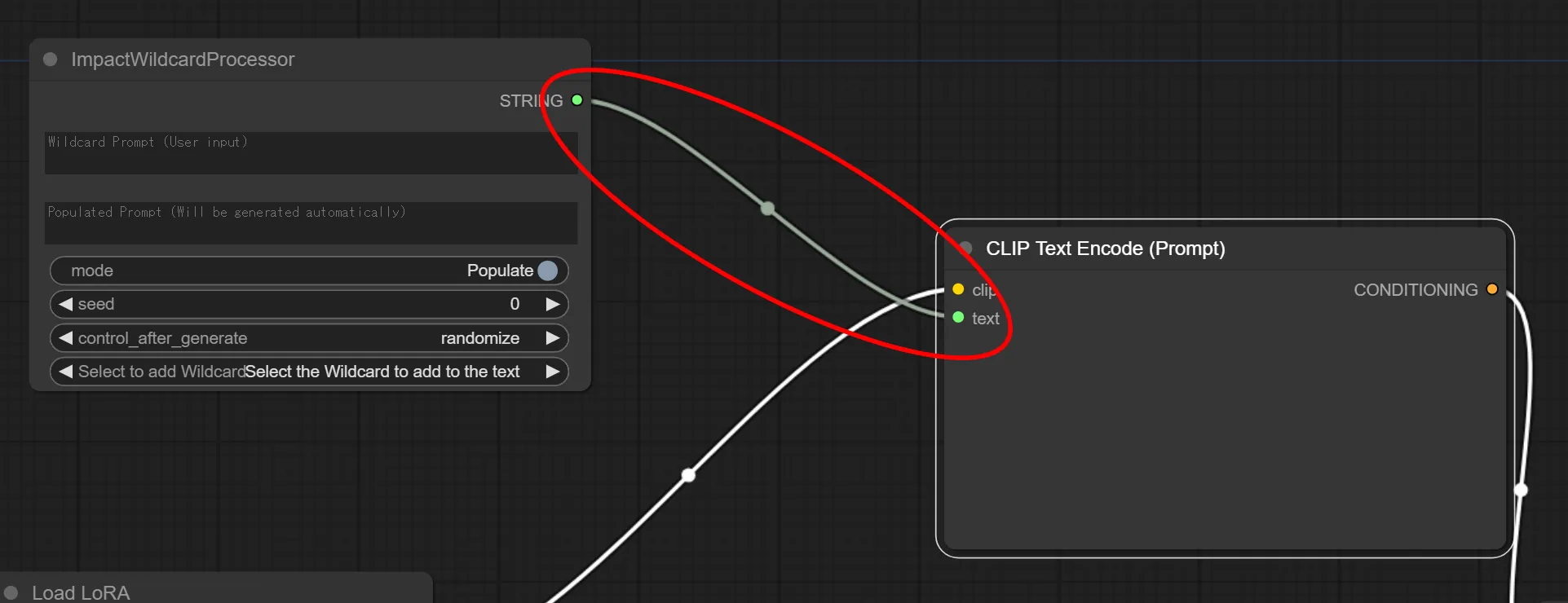
これでワイルドカードを使用したtxt2img処理の完成です。
スポンサーリンク
set,get ノードの設定
このノードは必須ではないですが、使用するとワークフローが見やすくなるので使用することをおすすめします。
set,getノードについて説明すると、任意のノードの設定を格納、呼び出し出来るノードです。
これにより、ワークフローをスッキリさせる事が出来ます。
また、この記事ではset,getノードを使用しています。
1.Set ノードの追加
まずはset ノードを追加します。
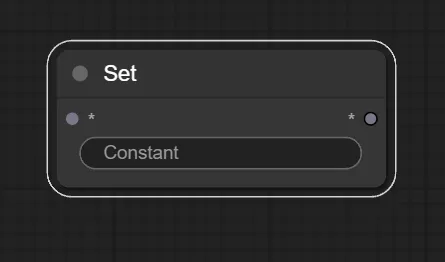
2.Set ノードを任意のノードと繋ぐ
格納したいノードとSetノードを繋ぎます。
今回はtxt2imgで生成した画像を次の工程で行うimg2imgの元画像として使いたいので、VAE Decode の “IMAGE” と Set の “*” を繋ぎます。
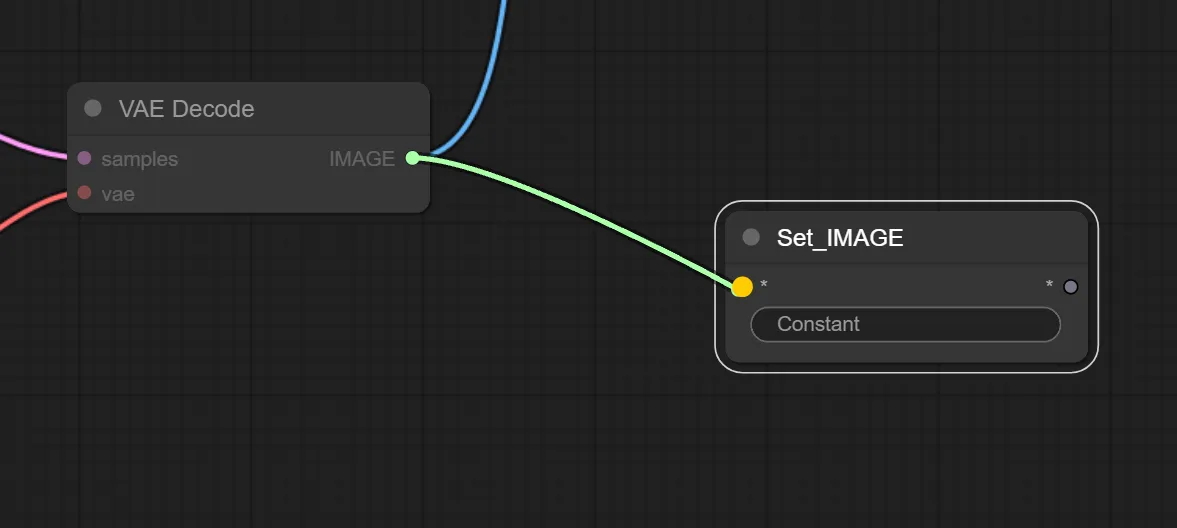
そうすると、Setノードが以下のように変更されるので、赤枠で囲った「Constant」に任意の名前を付けます。ここで付けた名前がGetノードで読み出す時に必要になります。
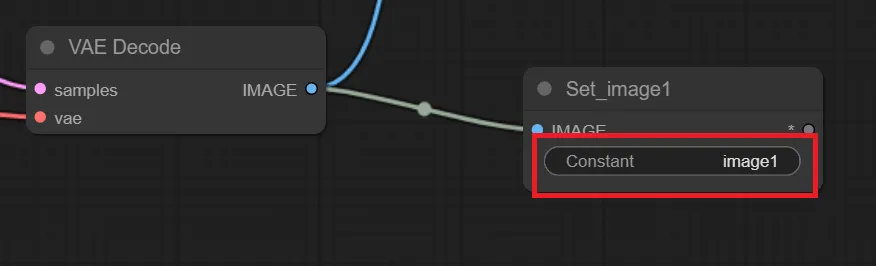
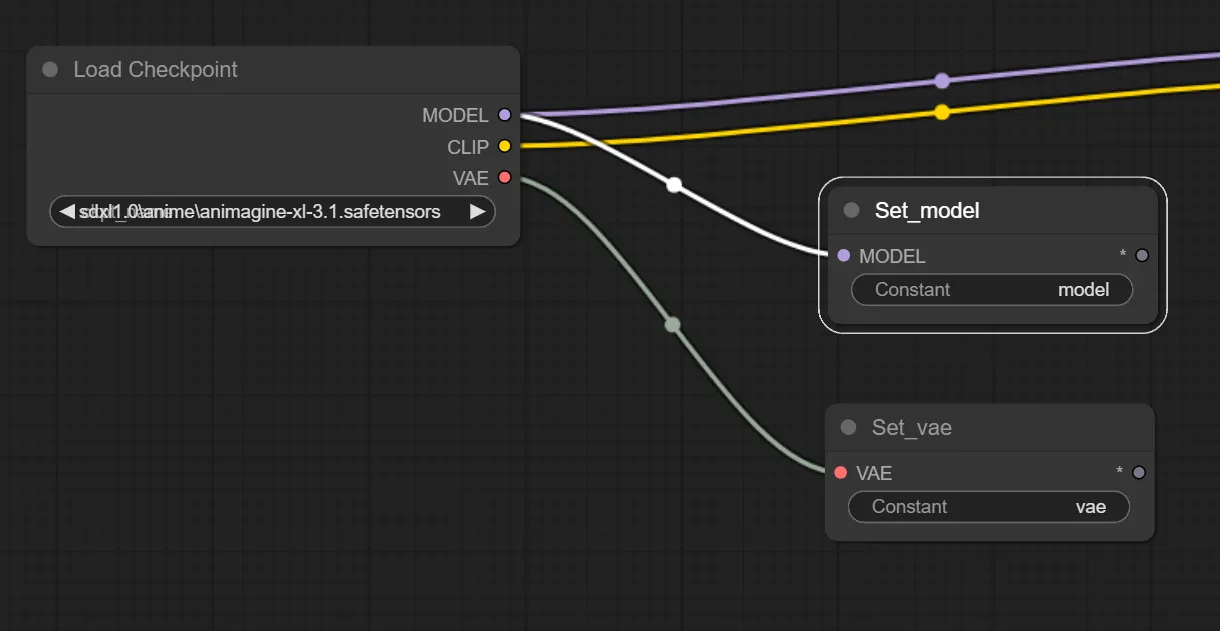
また、注意点ですがSetノードに格納できる項目は1つのみです。なので、Load Checkpointの”MODEL”と”VAE”の項目を格納したい場合は、以下のようにSetノードを2つ追加し、それぞれを線で繋ぐ必要があります。
img2img部分の構築
img2img部分を作成していきます。また、この項目は前項の「txt2img部分の構築」が済んでいる事を前提として進めていきます。
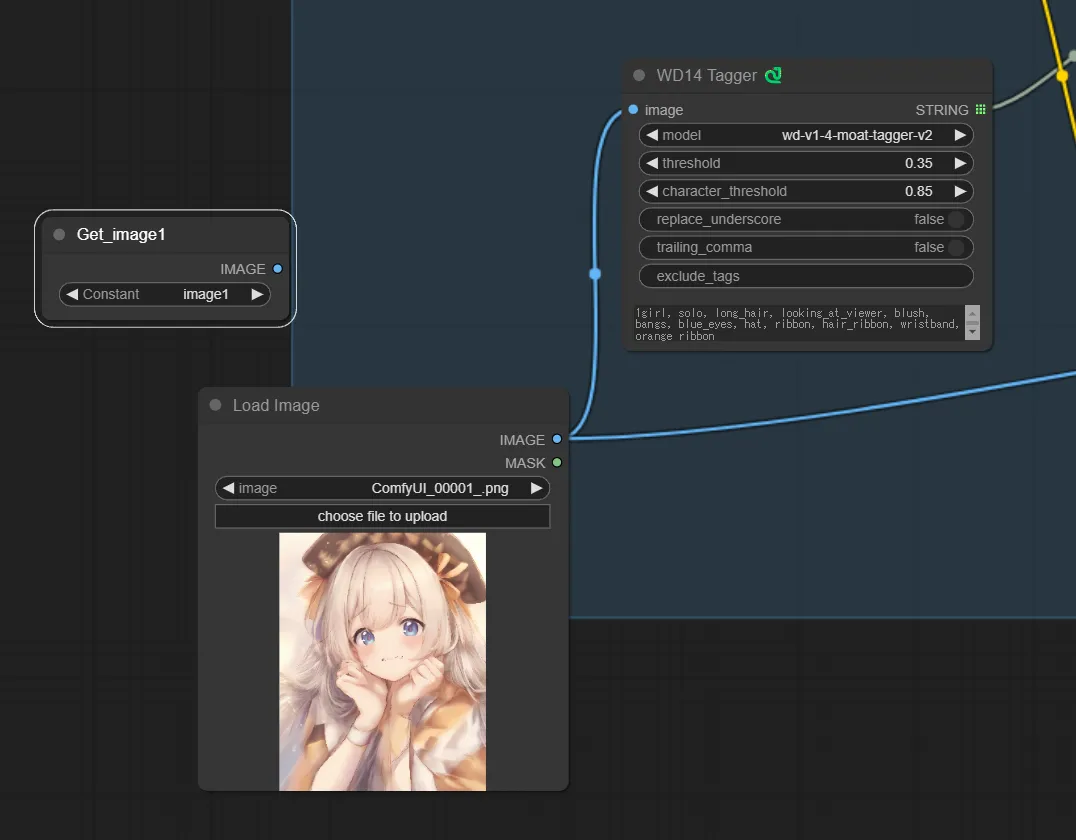
今回はWD14 taggerでタグを解析し、それをプロンプトとして使う為、WD14 taggerノードを使用します。
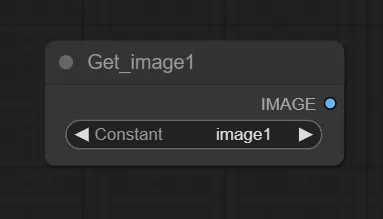
1.Getノードの追加する
txt2imgの最後に追加したSetノードに格納した画像を呼び出すためにGetノードを追加します。
追加したGetノードのConstantは、生成画像を格納したSetノードで命名した名前を選択します。
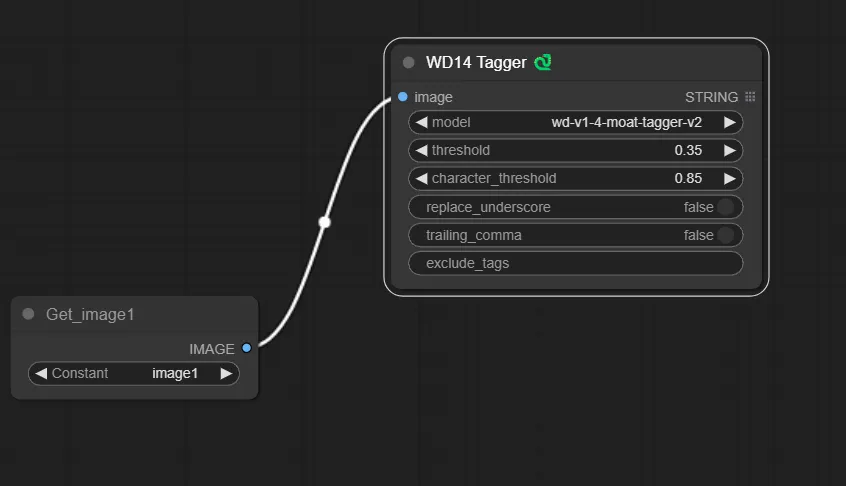
2.WD14 taggerノードの追加する
画像からdanbooruタグを解説する為のノード、WD14 taggerを追加し、先ほど追加したGetノードと繋ぎます。
3.CLIP Text Encode(Prompt) ノードを追加する
ポジティブプロンプト用とネガティブプロンプト用でCLIP Text Encode(Prompt)を2つ追加し、WD14 taggerで解説したタグを格納するため、ポジティブプロンプト用のCLIP Text Encode(Prompt) ノードを右クリックし「Convert Input to Widget」→「Convert text to Widget」を選択します。
次にポジティブプロンプト用のCLIP Text Encode(Prompt)とWD14 taggerを繋ぎます。
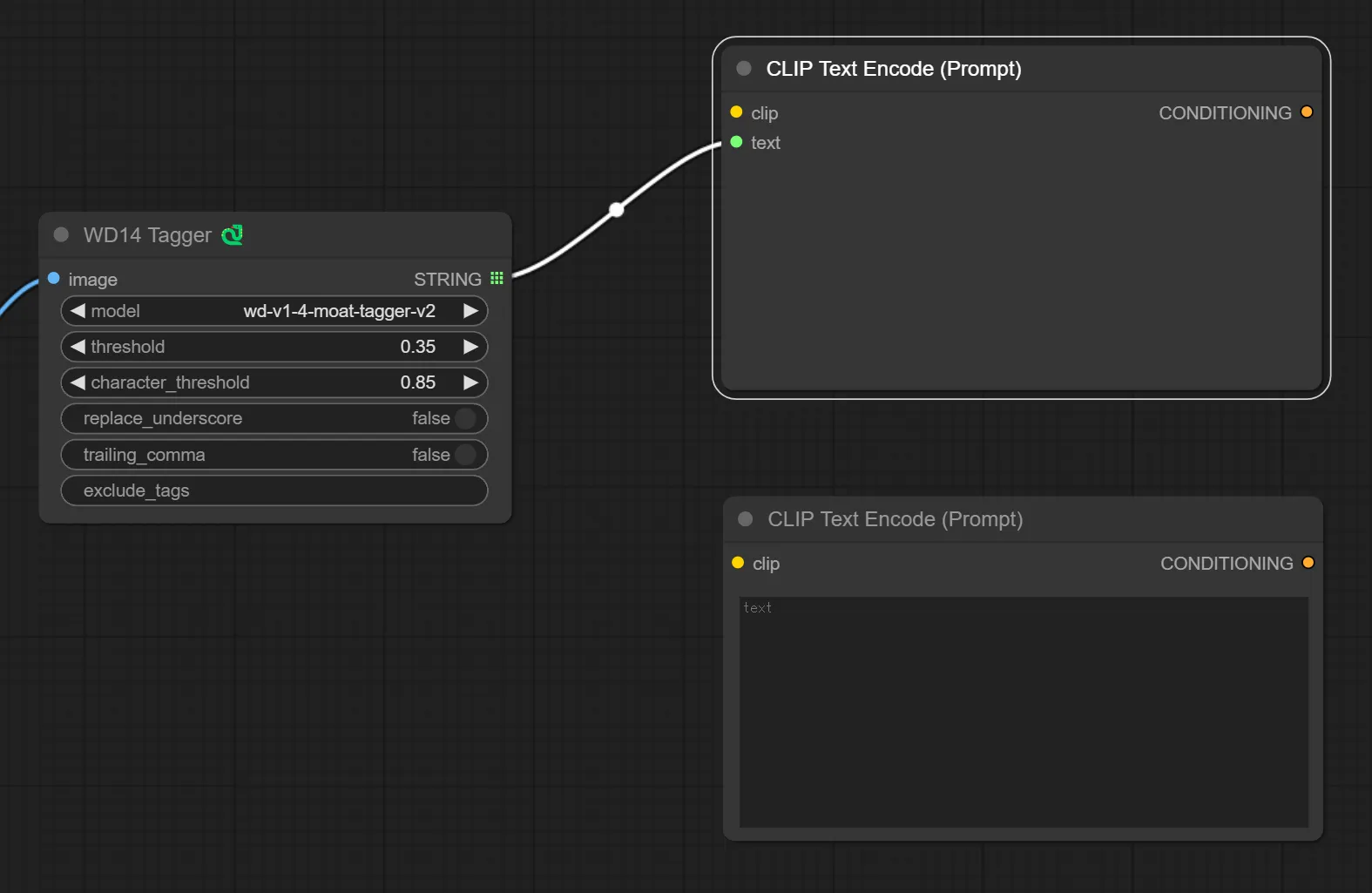
これで、WD14 taggerで解析したタグがプロンプトとしてCLIP Text Encode(Prompt)ノードへ格納されます。
4.Load Checkpoint ノードを追加する
Load Checkpoint ノードを追加し、Load Checkpointの “CLIP” と CLIP Text Encode(Prompt)の “clip”を繋ぎます。
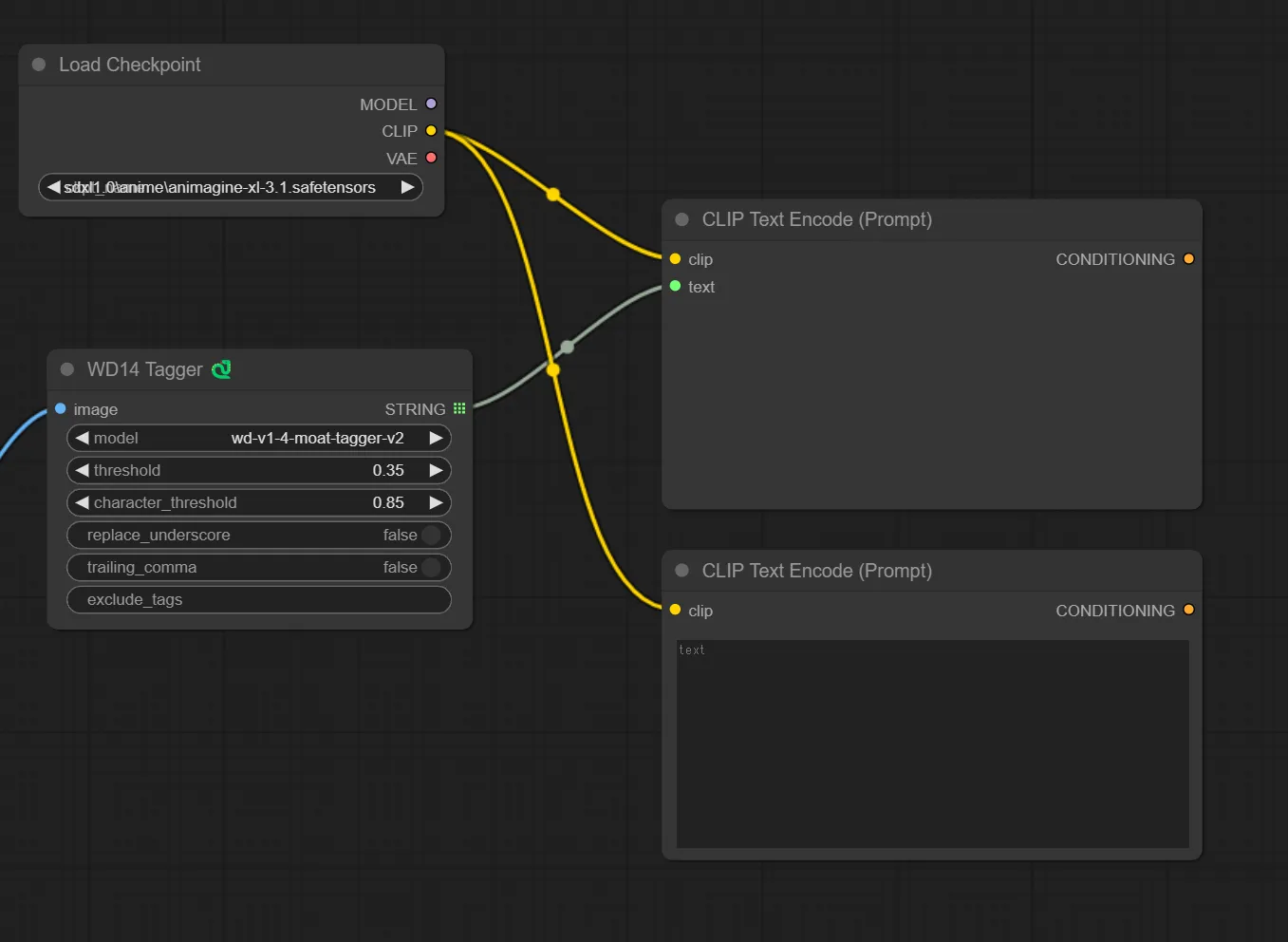
LoRAを使用する場合は、txt2img部分の構築で行ったように、Load LoRA ノードを追加して同じように繋いでください。
5.KSampler ノードを追加する
KSamplerノードを追加して、Load Checkpoint と CLIP Text Encode(Prompt)をKSamplerと繋ぎます。
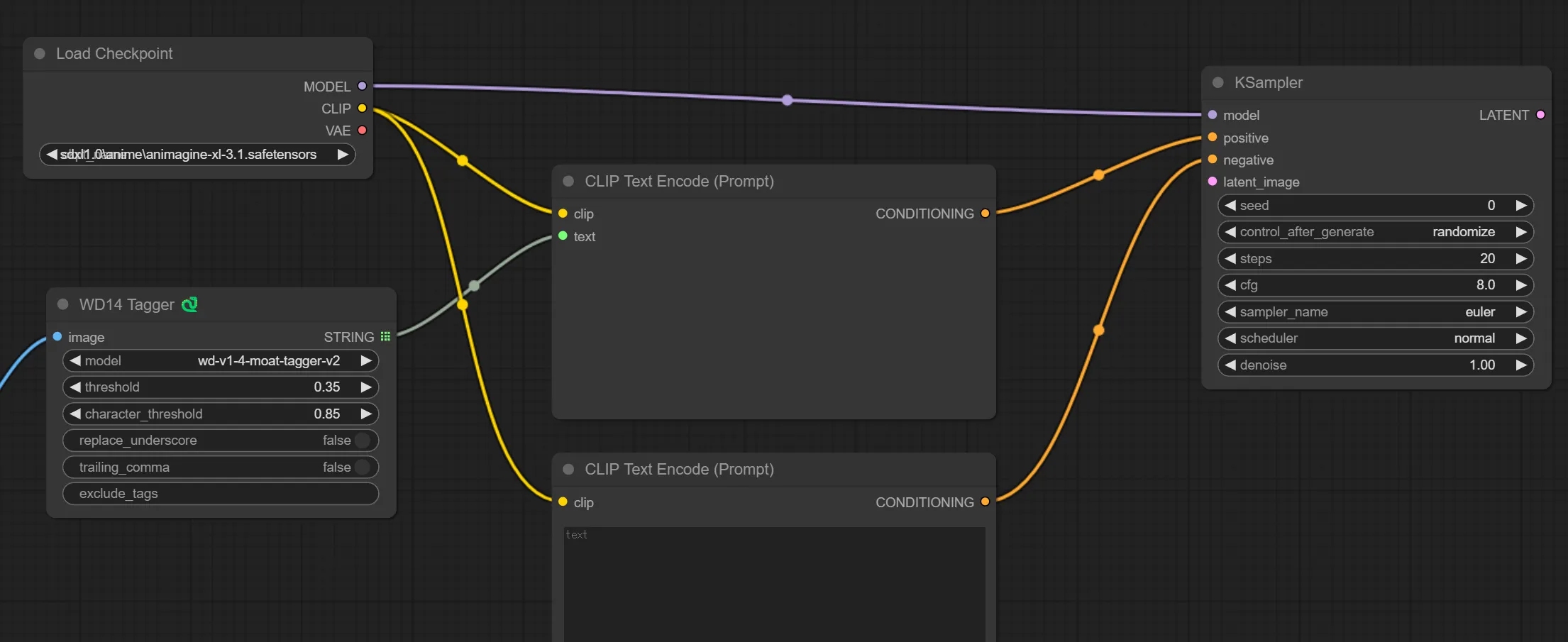
6.VAE Encode ノードを追加する
pixel画像をLatent画像へ変換するノードであるVAE Encodeを追加し、最初に追加したGetノードと繋ぎます。

7.VAE EncodeとKSamplerを繋ぐ
VAE Encode ノードと KSampler ノードを繋ぎます。
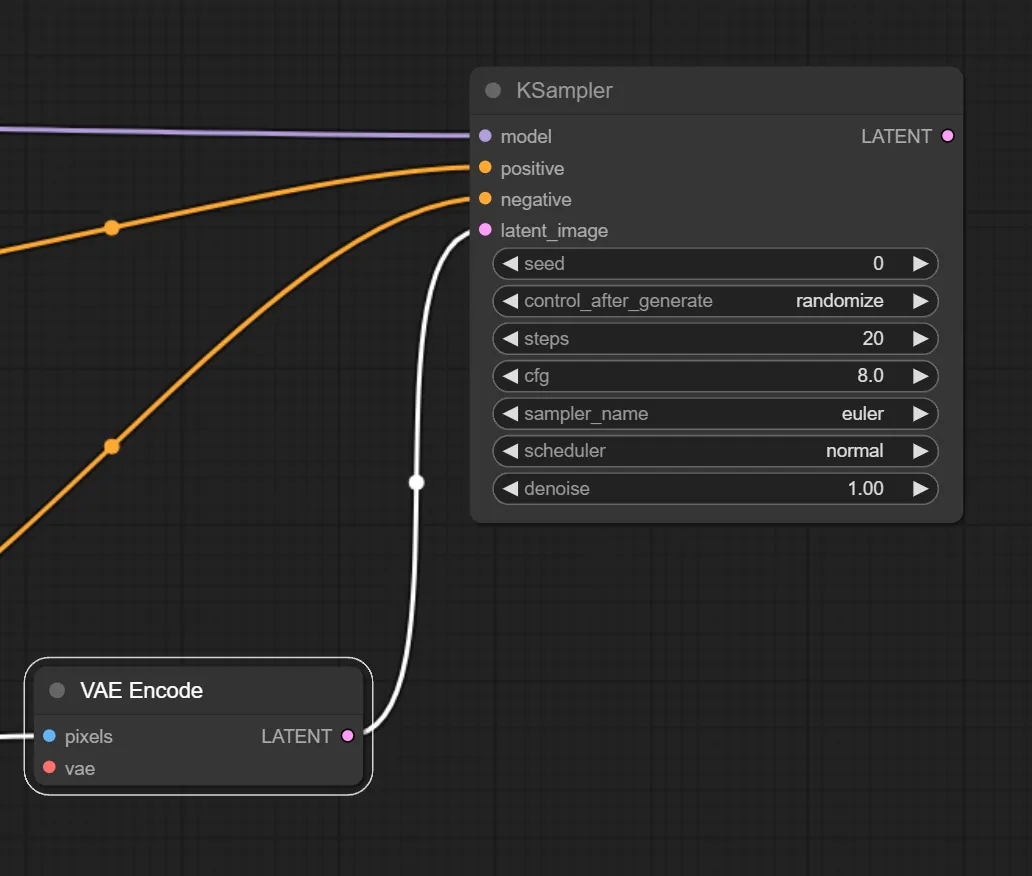
これでimg2img処理を施す元画像の読み込みが出来るようになりました。
7.pixel画像へ変換するノードなどを追加する
あとはtxt2imgの時と同じで、VAE Decodeノードと必要に応じてPreview ImageノードやSave Imageノードを追加しましょう。
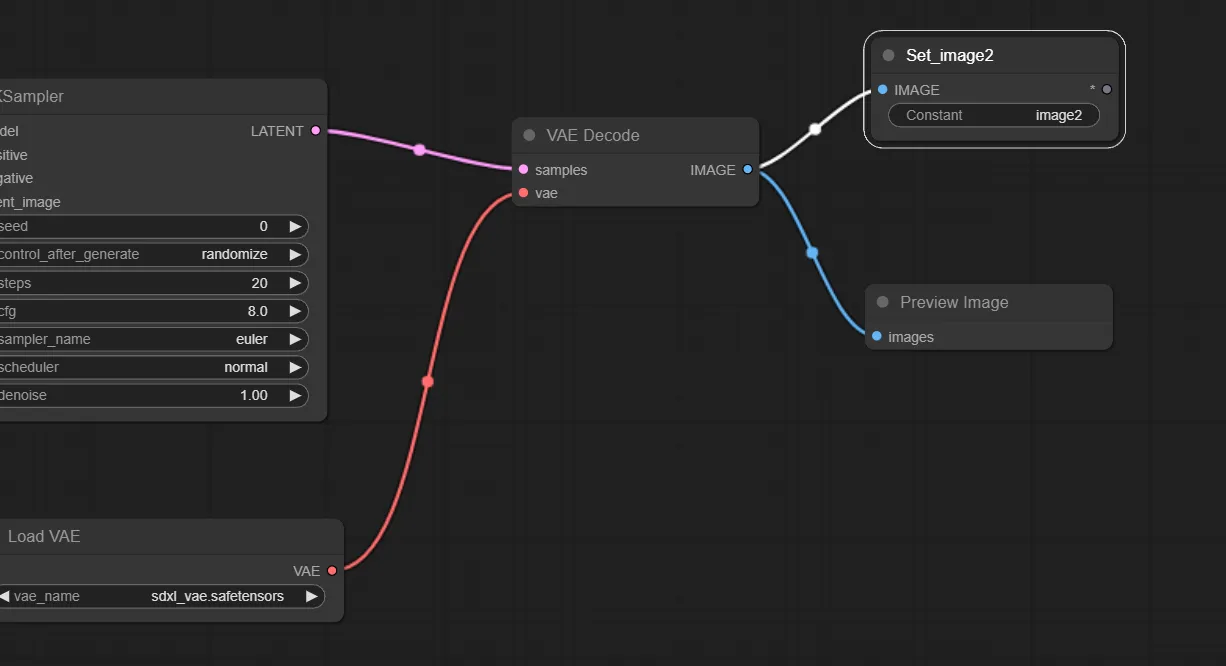
ここでは、次工程でFaceDetailer処理を施す為、Setノードにimg2imgで生成した画像を格納しています。
FaceDetailer部分の構築
それでは、顔の修正を行うFaceDetailerを使用する部分を作成していきます。
1.FaceDetailerノードの追加
まずは大本となるFaceDetailerノードを追加します。
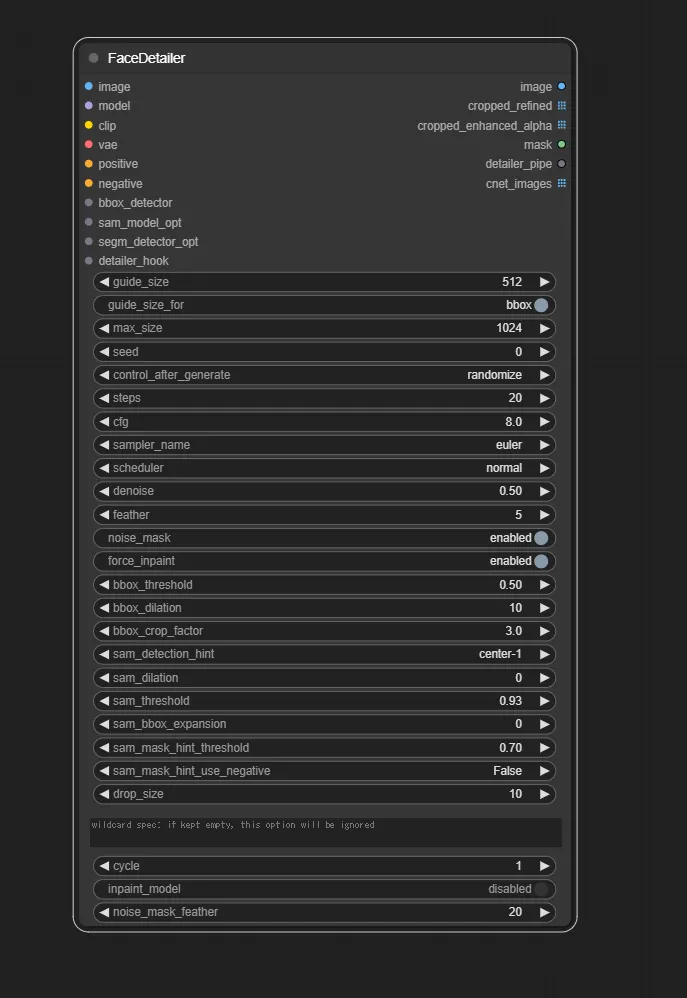
設定項目や入力部も多いですが、上から1つずつ接続していきましょう。パラメーターはデフォルトでも十分使えるので、今回はデフォルトの設定でやっていきます。
2.入力部”Image”への接続
まずは一番上の”Image”へ必要ノードを接続していきます。
この箇所は、顔を修正したい画像を読み込ませる箇所なのでimg2imgで生成した画像を読み込ませます。なので、接続するノードはimg2imgで生成した画像を呼び出したGetノードを追加します。
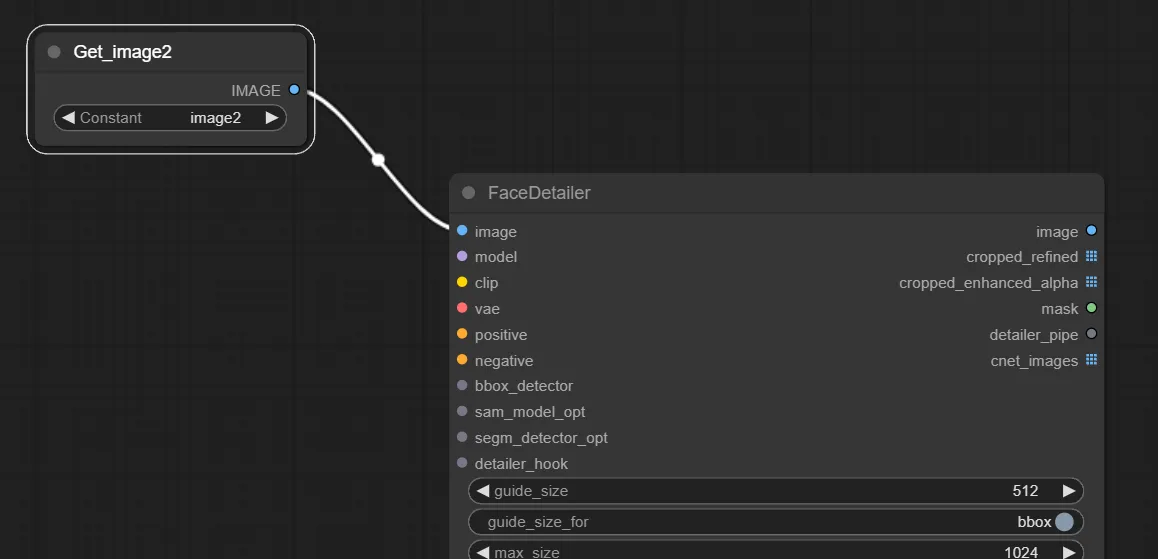
3.入力部”model”、”clip”、”vae”、”positive”、”negative”への接続
この箇所への入力はtxt2imgでもimg2imgでも行っているので説明は割愛します。
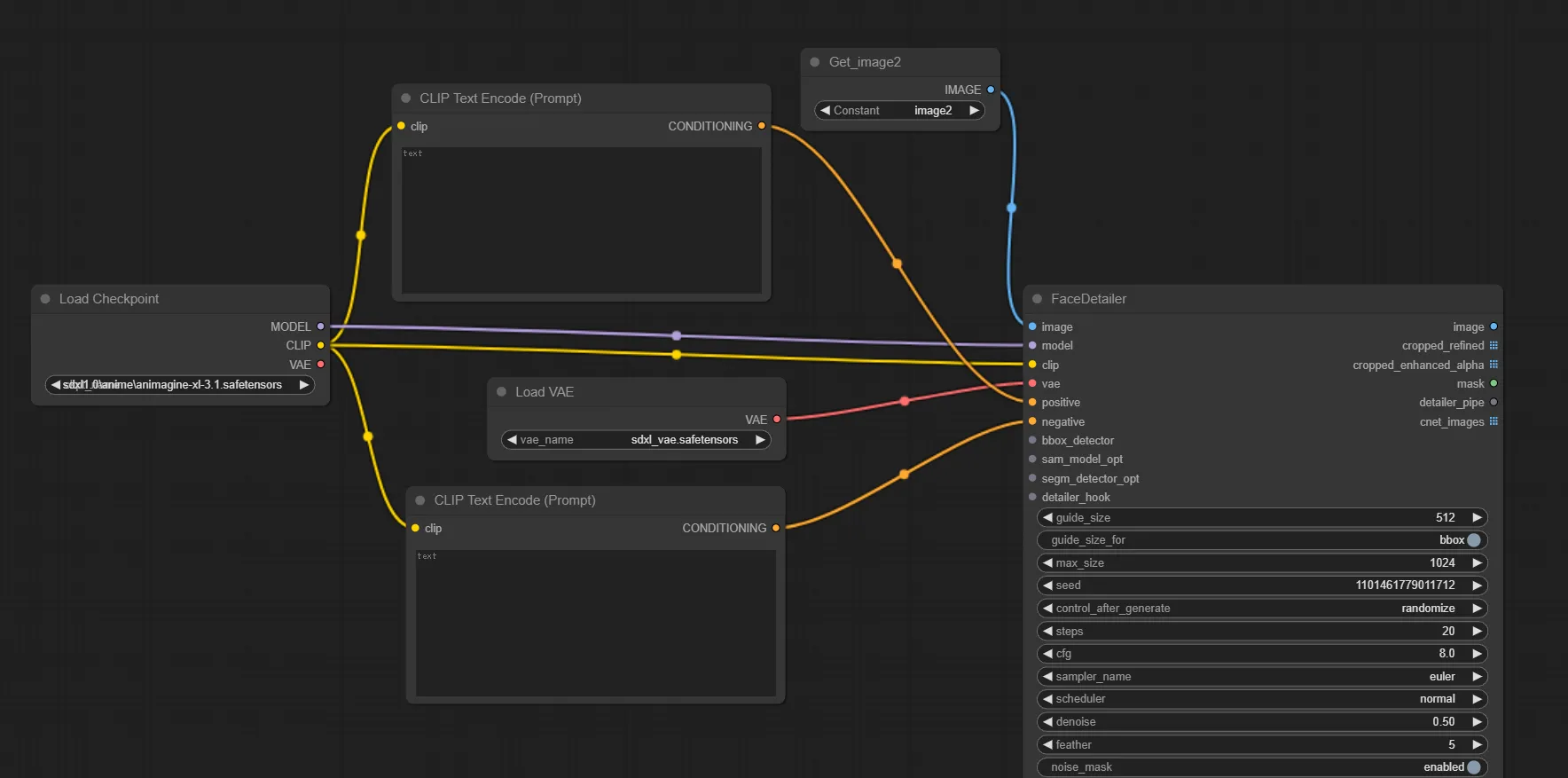
3.入力部”bbox_detector”への接続
UltralyticsDetectorProvider ノードを追加し、接続します。
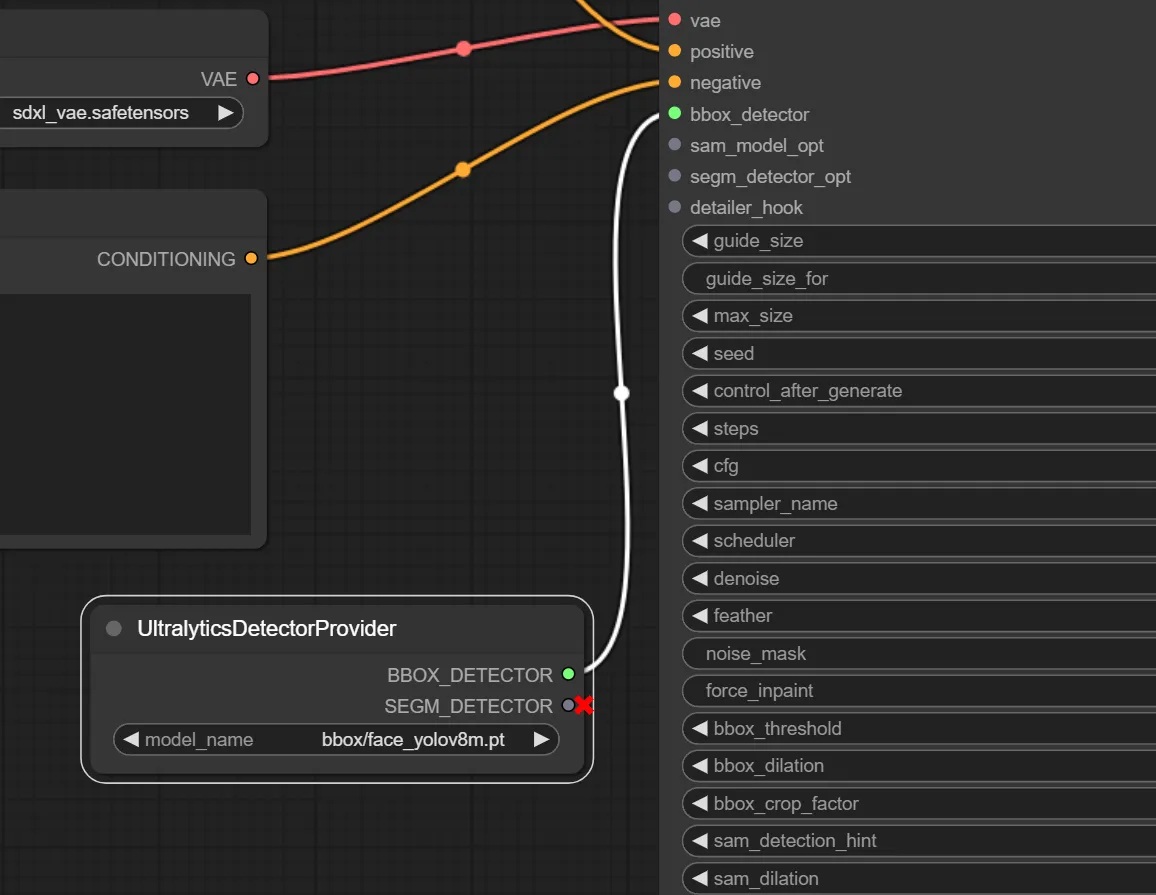
このノードで顔の検出モデルを指定します。ここで指定するモデルを手の検出モデルに変更することで、手の修正を行うことも出来ます。
これで、入力部の接続は完了です。
4.出力部”image”の接続
出力部にある”image”ですが、これはtxt2imgやimg2imgの時と同じです。Preview ImageやSave Imageノードと繋ぎましょう。
FaceDetailer前と後の比較方法
FaceDetailerで処理する前と処理した後で、どこがどういう風に変わったのかを確認する方法です。
FaceDetailer前と後の画像をそれぞれ保存して見比べても良いですが、ワークフロー上で比較する為のノードがあるので、そのやり方を紹介します。
1.Image Comparer (rgthree) ノードを追加
Image Comparer (rgthree) ノードを追加したら、”image_a”と”image_b”に比較した画像をそれぞれ接続しましょう。
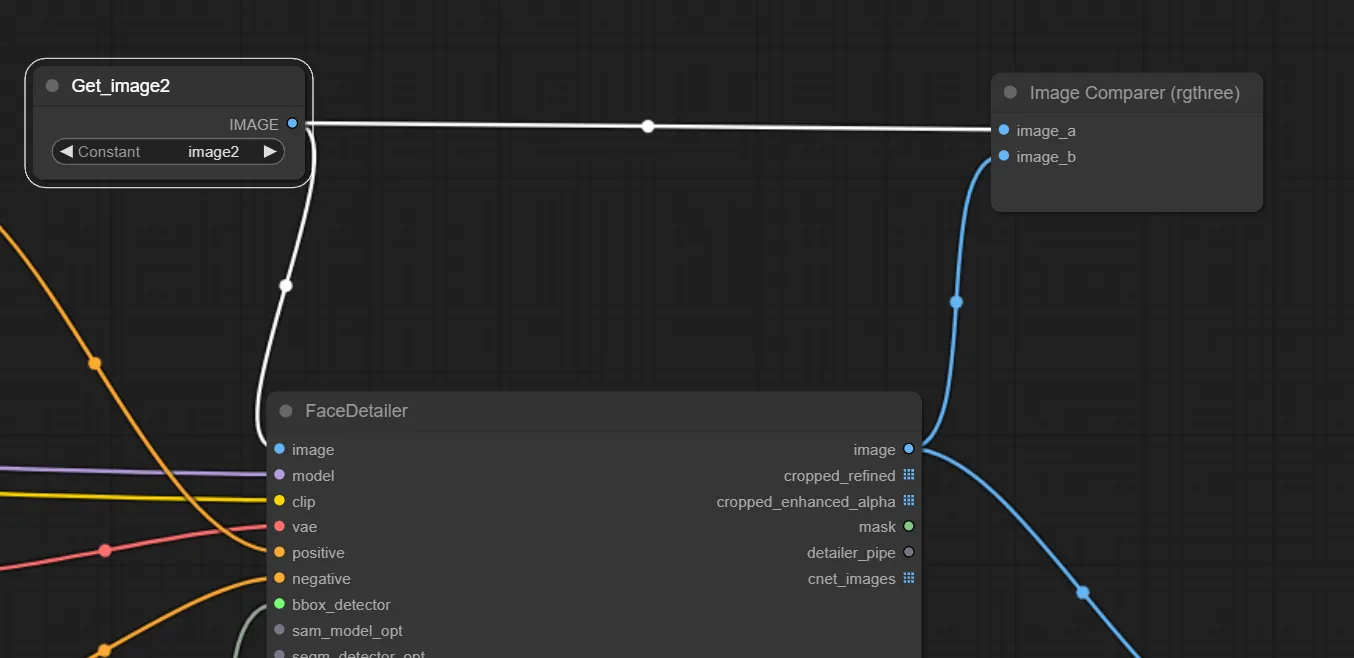
ここでは、FaceDetailer前後の画像を比較したいので、GetノードとFaceDetailerを接続しています。
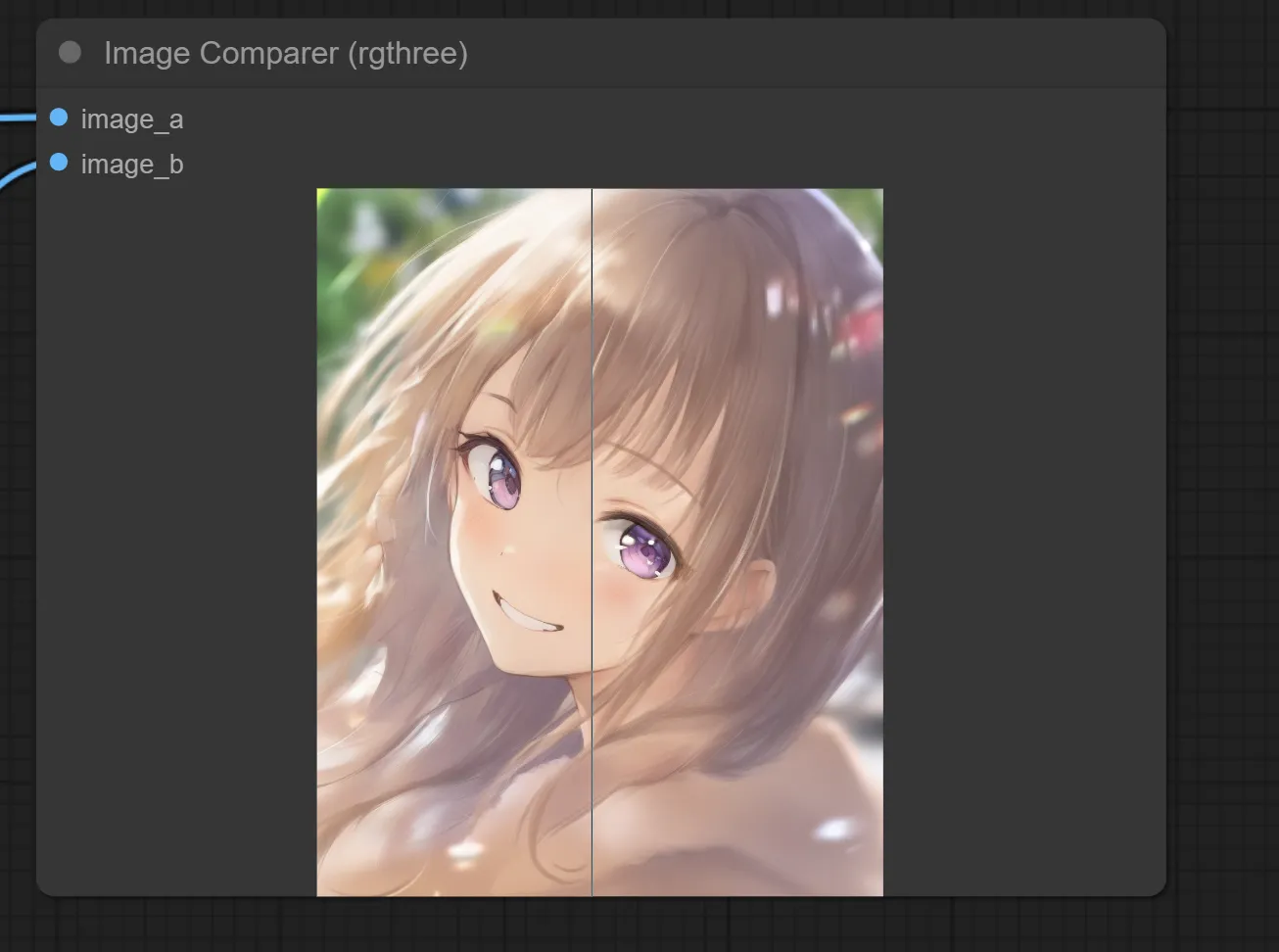
2.比較画像の確認
マウスを表示された画像の上で左右に動かせば確認できます。
右が”image_a”の画像、左が”image_b”の画像です。
3.おまけ
今さら言うのもなんですが、img2img処理とFaceDtailer処理の順番を逆にした方が良いですね。
こういう処理の順番を変えたいという時にもSet/Getノードが約に立ちます。通常時であれば線を繋ぎ変えなければならず、ノードの配置によっては大変な作業になりますが、Set/Getノードで管理していればそれぞれの名前を変更するだけで対応できます。
ここまでのワークフローで言うと、FaceDetailer時のGetノードで読み込む名前を”image1″へ変更し、Setノードの名前を”imagev2″など別な名前へ変更。
次に、img2img時のGetノードを先ほど変更した”imagev2″へ変更。
これだけで順番を変更できます。
ただし、次項のアップスケール部分の説明はこの変更を行わない状態で行いますので注意してください。
アップスケール部分の構築
それではアップスケール部分を作成していきます。
1.Load Upscale Model ノードを追加
まずは、アップスケール用のモデルを読み込む為のノード、Load Upscale Model ノードを追加します。
2.Upscale Image (using Model) ノードの追加
次にUpscale Image (using Model) ノードを追加し、入力部の”upscale_model”には先ほど追加したLoad Upscale Modelを、“image”には読み込む画像を接続します。
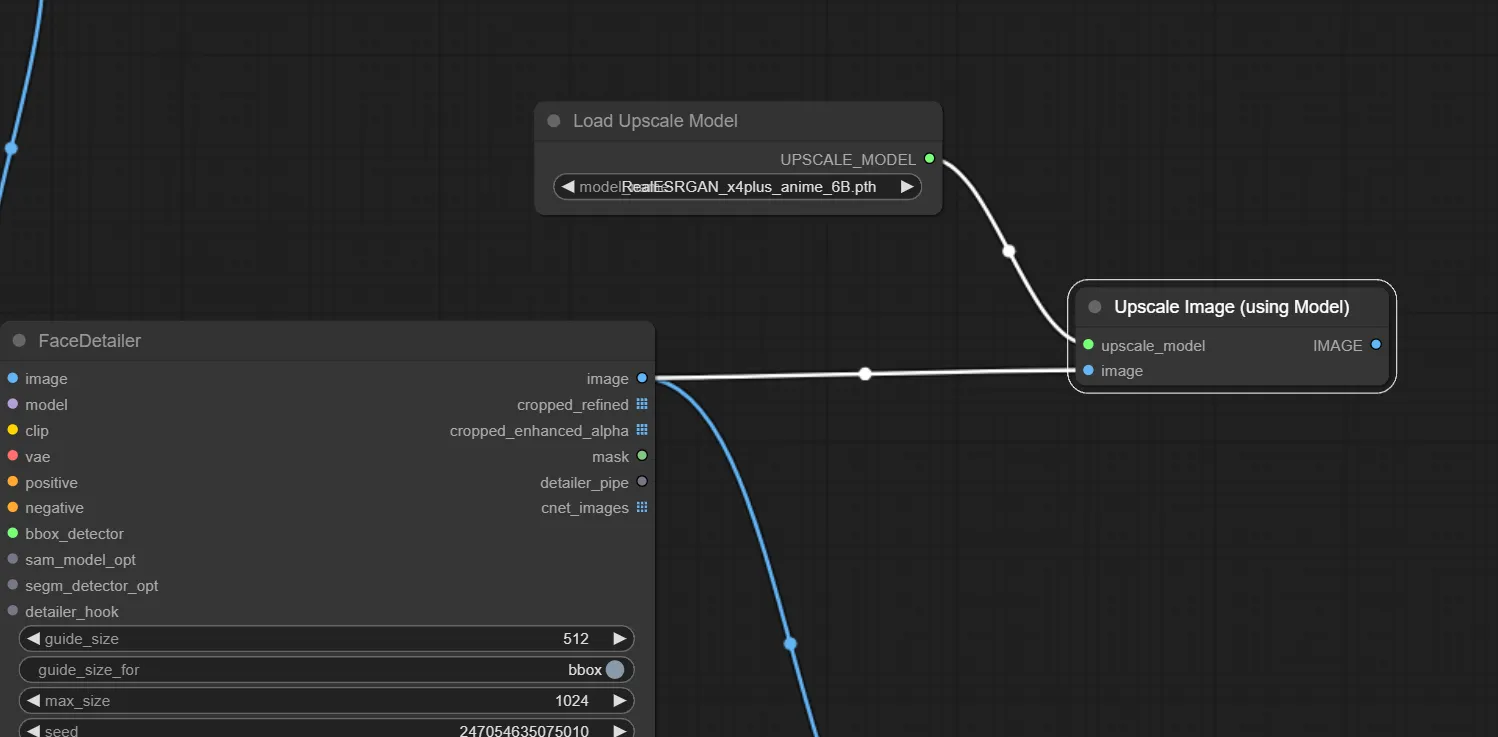
今回はFaceDetailer処理をした画像をそのまま使いたいので、FaceDetailerの出力部の”image”を接続します。
ちなみに、アップスケールだけであればこれで完成なので、Upscale Image (using Model) の出力部”IMAGE”からSave Image ノードに接続してやればアップスケール処理された画像を保存することが出来ます。
ただし、その場合はLoad Upscale Model ノードで指定したモデルに予め設定された倍率でアップスケールされることになります。
3.Upscale Image By ノードの追加
前述した通り、アップスケールするだけであればUpscale Image ノードまでで可能です。ですが、A1111版webuiのように倍率を指定するにはこのUpscale Image By ノードが必要です。
このノードを追加したらUpscale Image (using Model)ノードと繋ぎます。
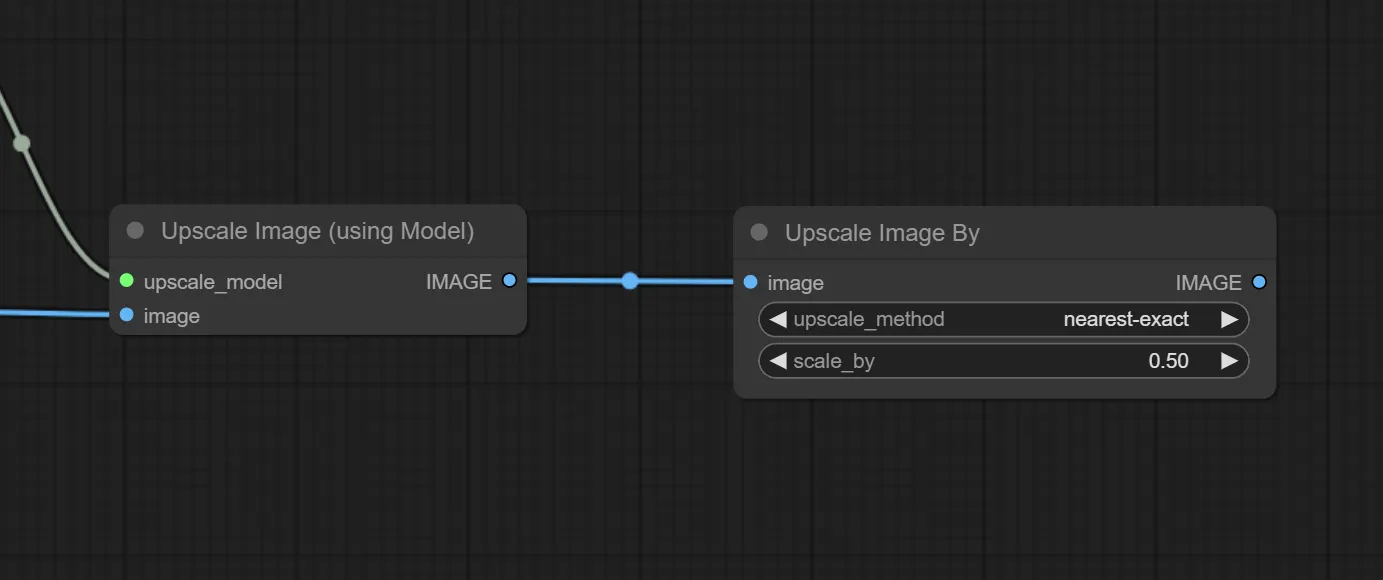
scale_byの設定を変更することで拡大倍率を変更できます。今回はアップスケール用のモデルに設定された倍率が4倍で、生成画像は2倍にしたいので0.50を指定します。
upscale_methodはお好みで設定してください。
この状態でもアップスケールは完了しているので、このままSave ImageでもOKです。ただ、せっかくなのでTile Diffusionも使用してみようと思います。
4.VAE Encode (Tiled) ノードの追加
pixel画像をlatent画像へ変換する為、VAE Encode (Tiled) ノードを追加します。VAE Encode ノードでも良いですが、VAE Encode (Tiled) の方が読み込みが速いのでおすすめです。
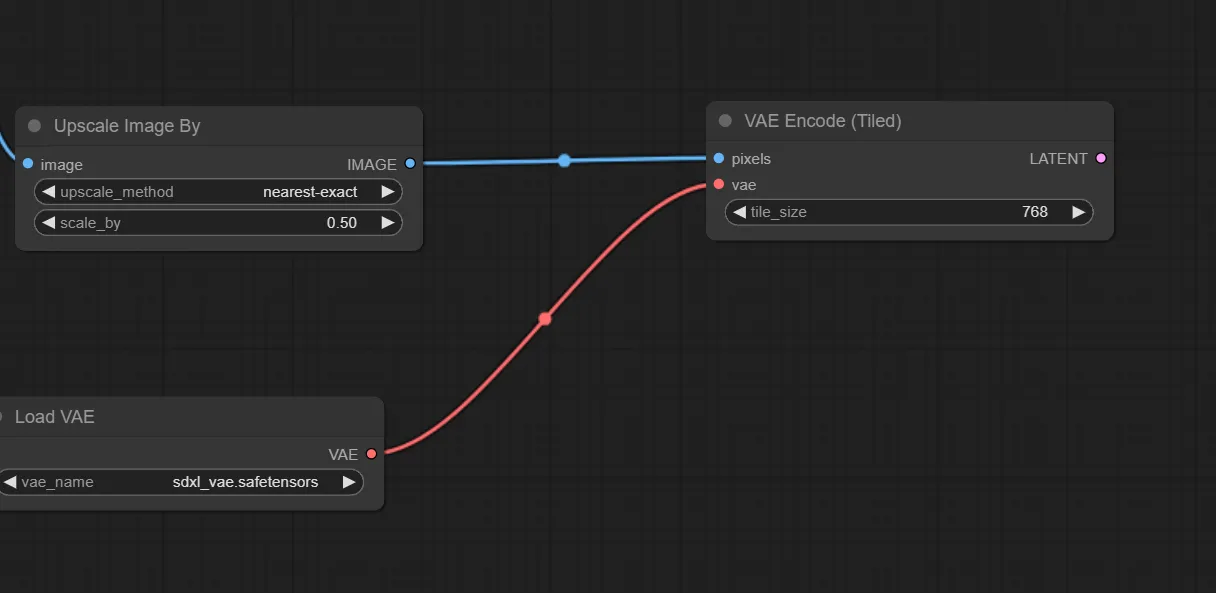
入力部 “vae” への接続は今までと同じです。
5.KSampler ノードを追加
KSampler ノードを追加し、入力部 “latent_image”へ先ほど追加したVAE Encode (Tiled) を接続します。”positive” と “negative” にはCLIP Text Encode (Prompt)をそれぞれ接続してください。
“model” は別なノードを経由する為、まだ接続しません。
6.Tiled Diffusion ノードの追加
Tiled Diffusion ノードを追加し、入力部 “model” にLoad Checkpoint出力部の “MODEL” を接続し、Tiled Diffusionの出力部 “MODEL” をKSampler入力部の”model”へ接続します。
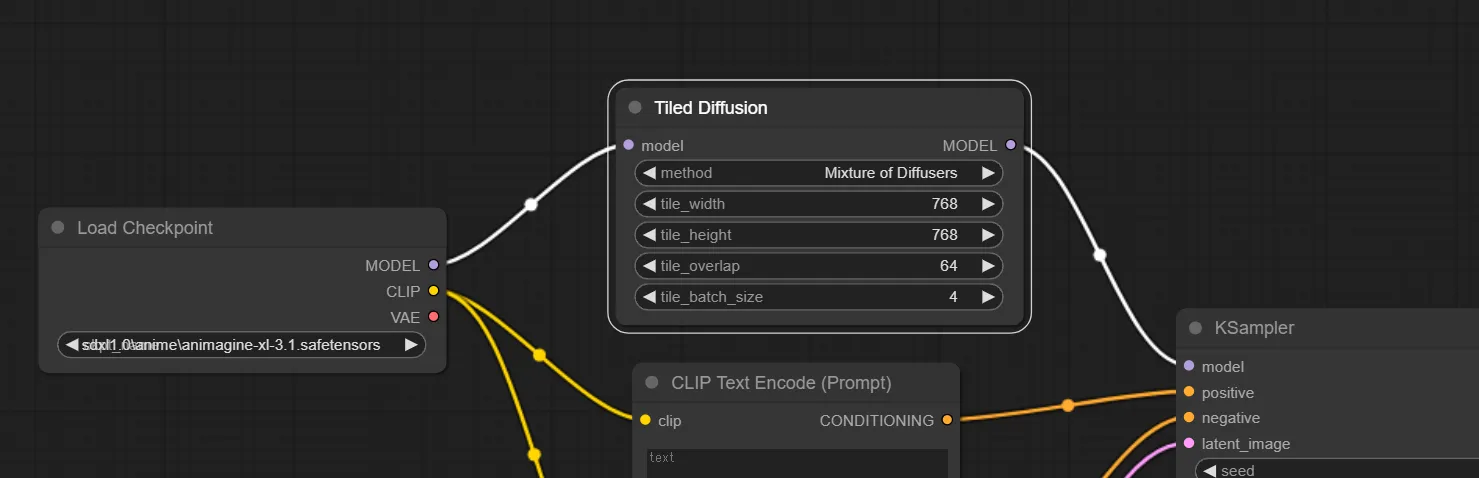
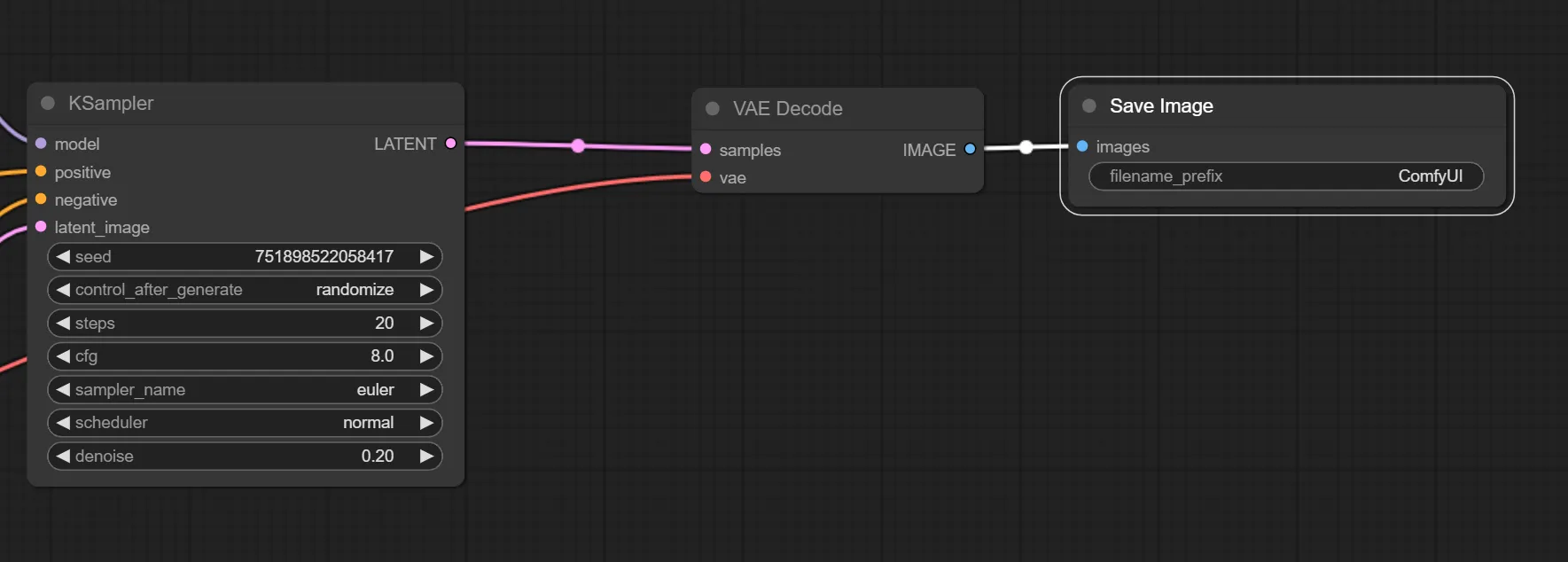
7.VAE EncodeとSave Image ノードを追加
あとはVAE EncodeとSave Imageを追加して完成です。
おまけ:画像を読み込んでimg2imgを行うワークフロー
今回はtxt2imgにて生成した画像をimg2imgでの元画像として指定しましたが、元画像を予め用意し、それを読み込む方法も書いておきます。
ベースとなるワークフローは、前述したimg2imgのものを使います。
1.Load Image ノードを追加
Load Image ノードを追加し、Get ノードと置き換える。
これだけです。読み込む画像はchoose file uploadをクリックして選択します。
おまけ2:グループを作成して見やすい画面にする
この記事では、txt2img、img2img、FaceDetailer、アップスケールの4つに分けて作成しました。
ですが同じ画面に4つの処理が混在していると、ゴチャゴチャしていて見にくいですね。
そこで、少しでも見やすくする為にグループを作成してみましょう。
1.グループに入れたいノードを選択する
ノードの選択は単体であればクリックするだけ、複数のノードを選択する場合は「Ctrl」を押しながらクリック、または「Ctrl」を押しながらマウスをドラッグ&ドロップで一気に選択することが出来ます。
ここではtxt2img用のノード群を選択しています。
選択したら、何もないところで右クリックします。注意点ですが、ノードの上で右クリックではなく、なにもないところで右クリックです。
右クリックで出てきたメニューから「Add Group For Selected Nodes」をクリックします。
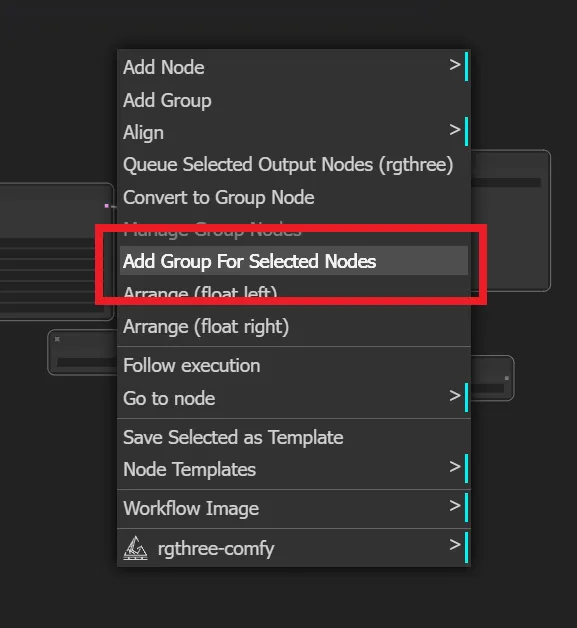
これでグループを作成できました。
グループ名の変更は、グループ内のなにもないところで右クリックし「Edit Group」→「Title」から出来ます。
最後に
A1111版webuiと同じ機能を使用する場合でも、めんどくさい手順になりますが、自由にノードを配置してワークフローを作成出来るので、使えるようになれば効率が段違いなのがComfyUIですので、是非とも食わず嫌いはせずに触ってみてください。
それでは!
スポンサーリンク

コメント