
X(旧Twitter)のAIであるGrokにも画像生成機能が追加され、それに使用されているモデルがFLUX.1なのだとか。
なので今回は、画像生成AIのFLUX.1をローカル環境で動かす方法を書いていきます。
ここで1つ注意してほしいのが、Grokに実装されたモデルは、恐らくFLUXの[pro]と呼ばれるモデルだと思いますが、こちらのモデルは配布されていないので、この記事では配布されている[dev]というモデルで進めていきます。
なので、Grokに実装されている画像生成と全く同じクオリティの画像が生成される訳ではありませんので、ご注意ください。
それでは手順を解説していきます。
ComfyUIの導入
現在はForgeなどでも動かせるようになっているようですが、最新の画像生成AIにいち早く対応するのはComfyUIのことが多いので、ComfyUIで動かしていきます。
導入についての記事は別であるので、そちらを参照してください。
【AIイラスト】ComfyUIの導入と使い方を解説【stable diffusion】
また、もう導入してあるという方は、FLUXに対応しているバージョンか確認してください。
最新のバージョンであれば問題ありません。
この記事で使用しているComfyUIのバージョンは2514、githubのコミットハッシュで言うと[75b9b5]なので、それ以降のバージョンであれば問題ないと思います。
スポンサーリンク
必要モデルのダウンロード
それではモデルファイルをダウンロードしていきます。
モデルファイル
FLUX.1-dev
ファイル名 : flux1-dev.safetensors
上記のファイルをダウンロードし、以下のフォルダへ保存します。
ComfyUI/models/unet
FLUX.1-schnell (メモリが32GB以下の場合はこちら)
もし、使用しているPCのメモリが32GB以下なのであれば、こちらのモデルをダウンロードしてください。
ファイル名 : flux1-schnell.safetensors
CLIPモデルファイル
CLIPモデルは3種類ありますが、必要なのでは2つです。
ファイル名 : clip_l.safetensors
このファイルは必須になっているので絶対ダウンロードしましょう。
ファイル名 : t5xxl_fp16.safetensors
ファイル名 : t5xxl_fp8_e4m3fn.safetensors (メモリが32GB以下の場合)
上記のファイルは使用しているPC環境によってダウンロードするファイルが異なります。
メモリが32GB以上であればfp16の方を、32GB以下であればfp8の方をダウンロードしてください。
保存場所は以下の通りです。
ComfyUI/models/clip
VAEファイル
ファイル名 : ae.safetensors
最後にVAEファイルをダウンロードします。
保存場所は以下の通りです。
ComfyUI/models/vae
ComfyUI ワークフローの構築
ワークフローを作成するのがめんどくさいと言う方はワークフローファイルの配布項目にて、基本となるワークフローを配布しているので、そちらをダウンロードし使用してください。
スポンサーリンク
ワークフロー構築
1.デフォルトのワークフローを消去する
起動時に表示されているワークフローを消去し、真っ新な画面にします。
消去するには、右側「Clear」と書かれたボタンをクリックします。
2.「Load Diffusion Model」「DualCLIPLoader」ノードを追加する
「Load Diffusion Model」ノードと「DualCLIPLoader」ノードを追加します。
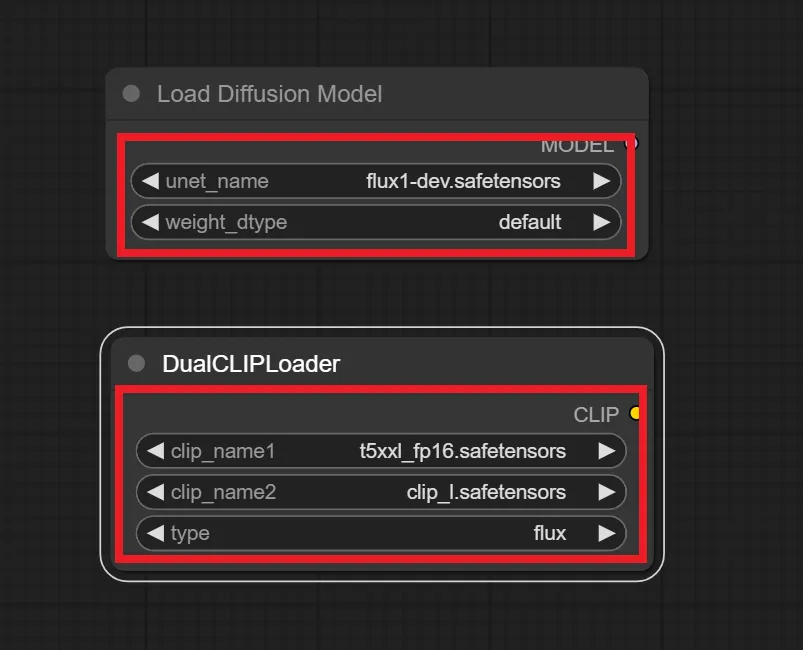
設定は赤枠で囲んだようにしてください。
3.「CLIP Text Encode (Prompt)」「BasicScheduler」「BasicGuider」ノードの追加
「CLIP Text Encode (Prompt)」「BasicScheduler」「BasicGuider」の3つのノードを追加したら、下記の画像のようにノードを繋いでください。
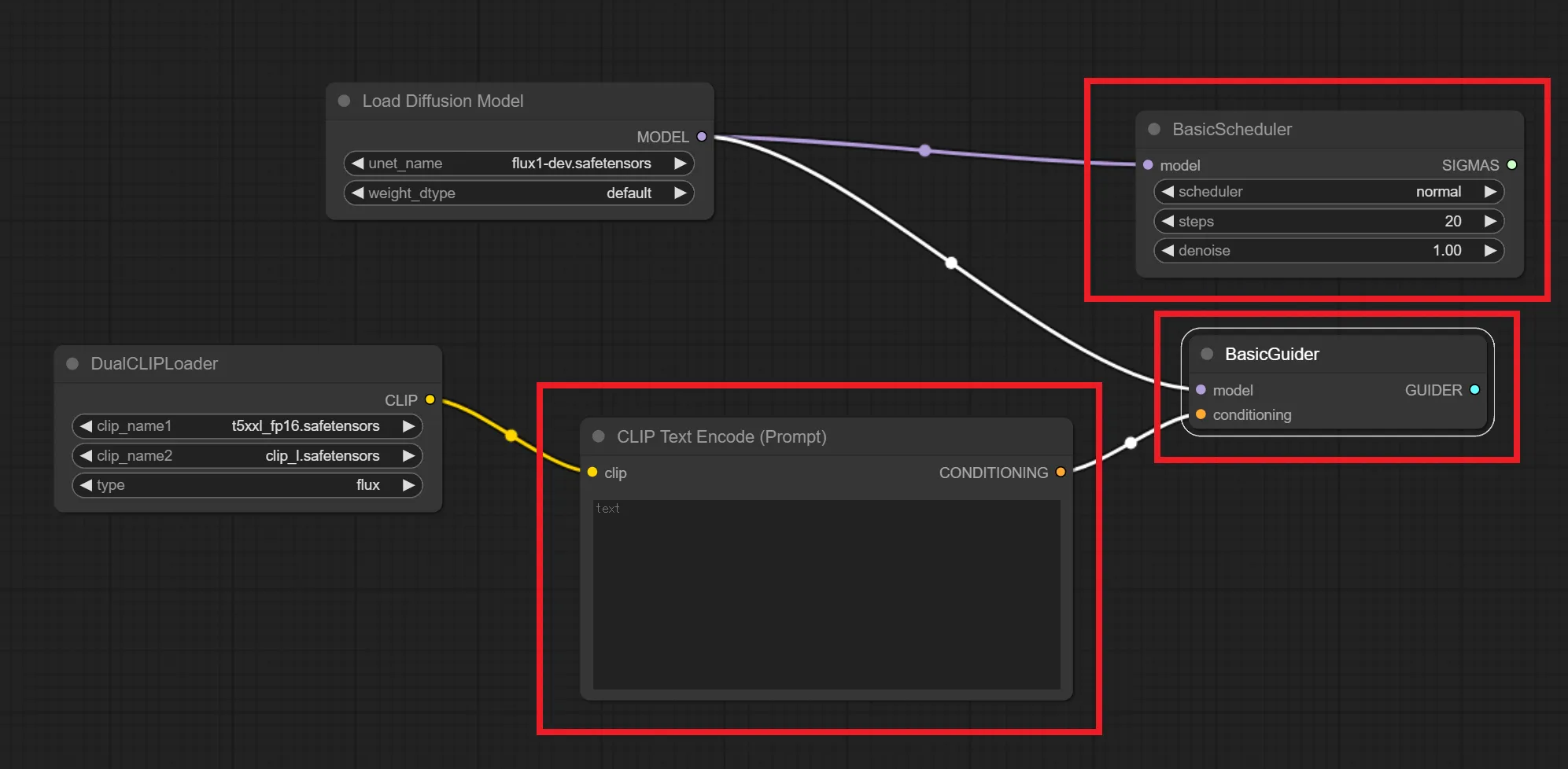
「Load Diffusion Model」ノードの”MODEL”から「BasicScheduler」と「BasicGuider」ノードの”model”へ繋ぐ
「DualCLIPLoader」ノードの”CLIP”から「CLIP Text Encode (Prompt)」ノードの”clip”へ繋ぐ
「CLIP Text Encode (Prompt)」ノードの”CONDITIONING”から「BasicGuider」ノードの”conditioning”へ繋ぐ
4.「SamplerCustomAdvanced」ノードの追加
「SamplerCustomAdvanced」ノードを追加したら、以下のようにノードを繋げてください。
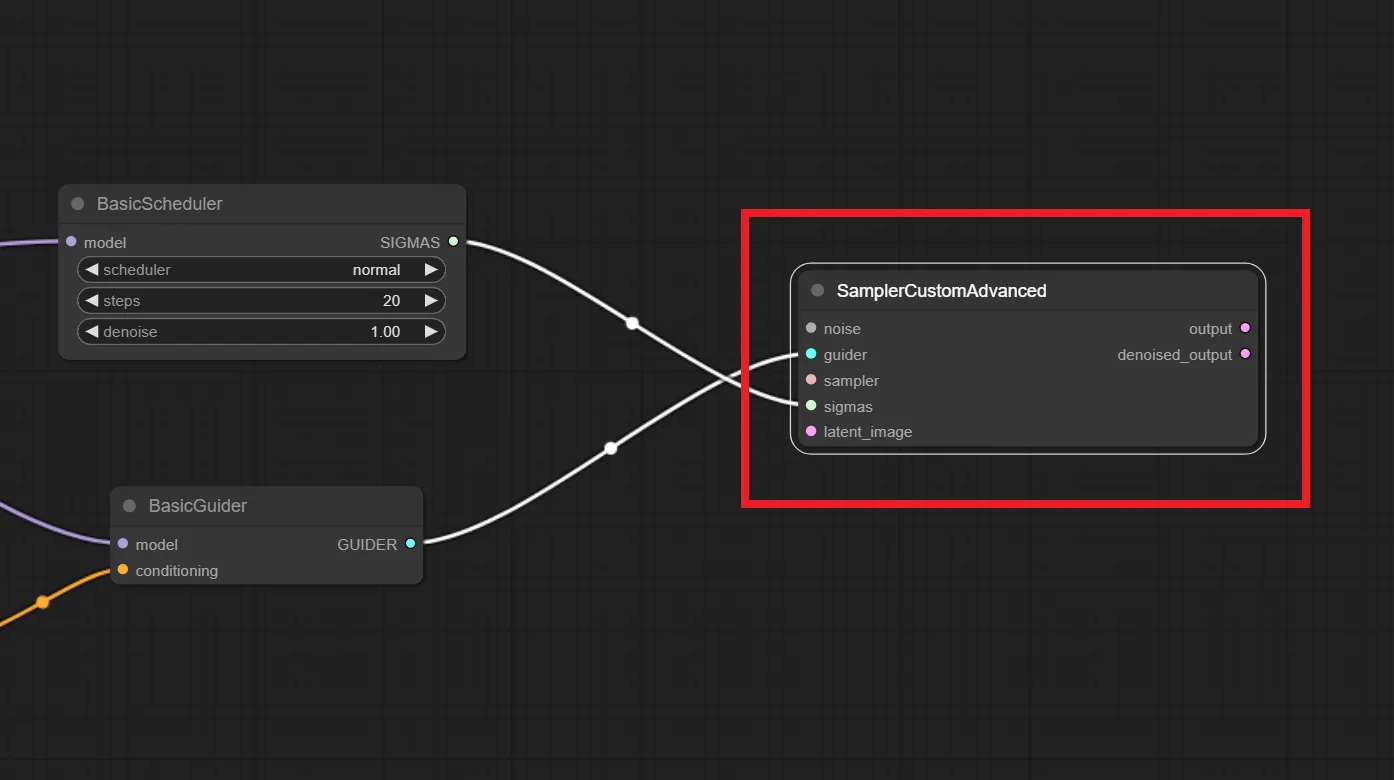
「BasicScheduler」ノードの”SIGMAS”から「SamplerCustomAdvanced」ノードの”sigmas”へ繋ぐ
「BasicGuider」ノードの”GUIDER”から「SamplerCustomAdvanced」ノードの”guider”へ繋ぐ
5.「RandomNoise」「KSamplerSelect」「Empty Laten Image」ノードの追加
「RandomNoise」「KSamplerSelect」「Empty Laten Image」の3つのノードを追加したら、以下のように繋げてください
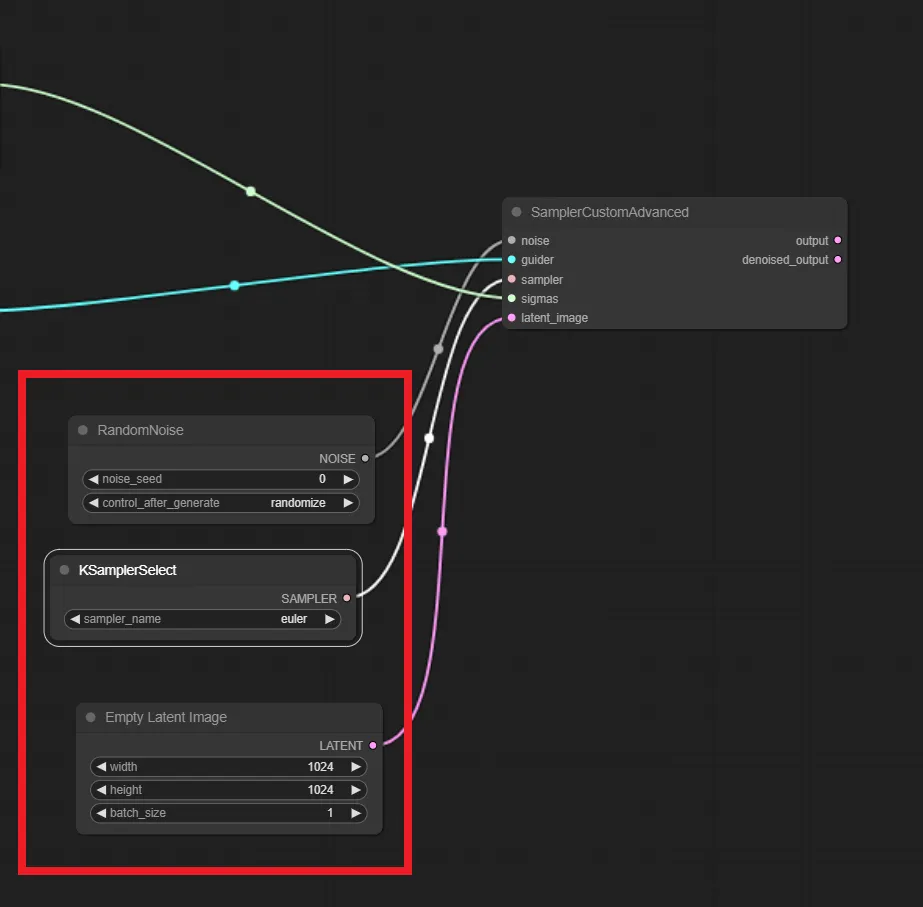
「RandomNoise」ノードの”NOISE”から「SamplerCustomAdvanced」ノードの”noise”へ繋ぐ
「KSamplerSelect」ノードの”SAMPLER”から「SamplerCustomAdvanced」ノードの”sampler”へ繋ぐ
「Empty Laten Image」ノードの”LATENT”から「SamplerCustomAdvanced」ノードの”latent_image”へ繋ぐ
6.「VAE Decode」「Load VAE」ノードの追加
「VAE Decode」「Load VAE」の2つのノードを追加したら、以下のように接続してください。
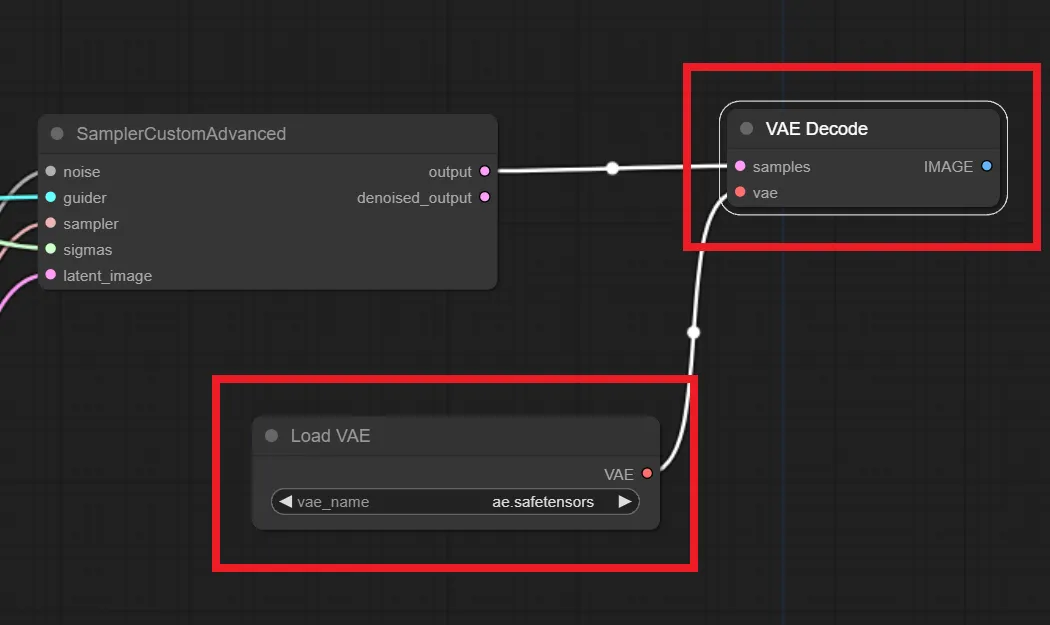
「SamplerCustomAdvanced」ノードの”output”から「VAE Decode」ノードの”samples”へ繋ぐ
「Load VAE」ノードの”VAE”から「VAE Decode」ノードの”vae”へ繋ぐ
7.「Preview Image」 or 「Save Image」ノードの追加
最後に、「Preview Image」 または「Save Image」ノードを追加して以下のように接続してください
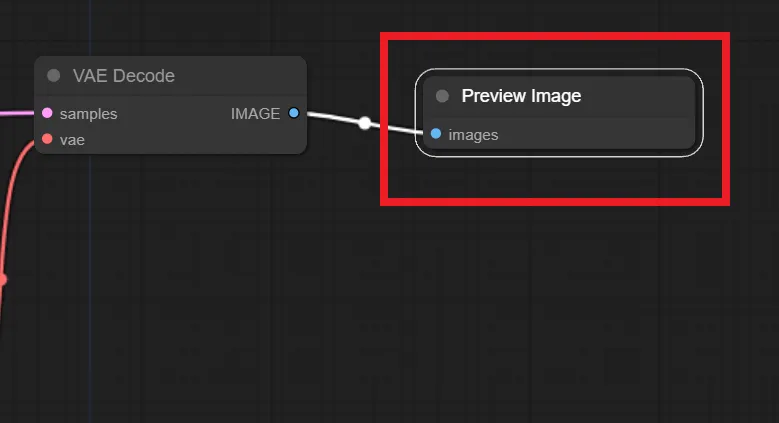
「VAE Decode」ノードの”IMAGE”から「Preview Image」ノードの”images”へ繋ぐ
また、「Preview Image」と「Save Image」の違いですが、「Preview Image」 は、ComfyUI上で生成された画像を確認し、気に入った画像であれば手動で保存するノードで、「Save Image」は生成された画像を全て、指定されたフォルダに保存するノードです。
「Preview Image」はワークフローのテストとして生成する時に使うようなノードなので、基本的には「Save Image」を使うのが良いでしょう。
ワークフローファイルの配布
構築がめんどくさいという方は、以下のリンクから.jsonファイルをダウンロードし、ComfyUIの画面にドラッグ&ドロップしてください。FLUX用のワークフローが読み込まれます。

ノードの設定項目
それでは、追加したノードで、設定を変更する箇所を説明していきます。
Load Diffusion Model
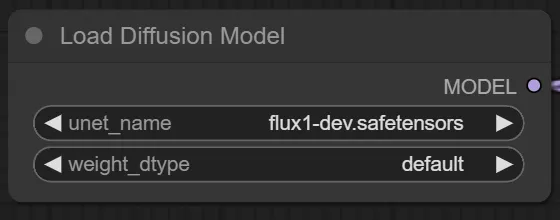
使用するモデルファイルを指定します。
unet_nameにはFLUXのモデルファイルを指定してください。
weight_dtypeは基本defaultでOKです。
DualCLIPLoader
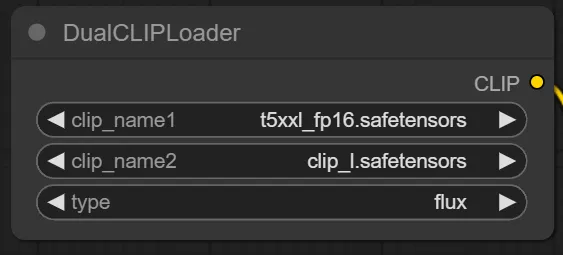
CLIPファイルを指定します。
clip_name1にはt5xx_fp16.safetensorsを指定します。
clip_name2にはclip_l.safetensorsを指定します。
typeはfluxを指定します。
CLIP Text Encode (Prompt)
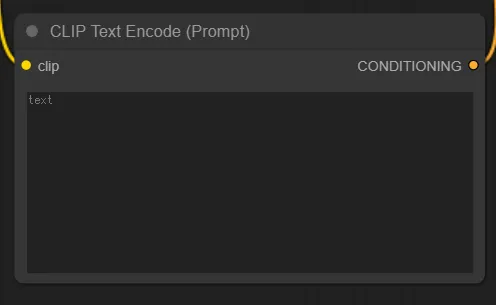
これは言わずもがな、プロンプトを入力するノードです。
BasicScheduler
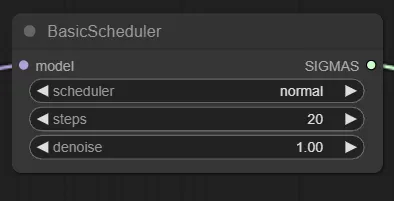
スケジューラーやステップ数、ノイズ強度を指定できます。
通常のtxt2imgであれば”denoise”は1.00で良いので、変更するとしたら”scheduler”と”steps”の2箇所になると思います。
RandomNoise
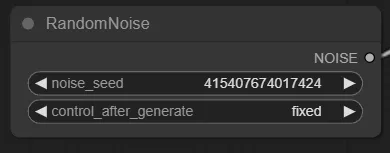
シード値を決めるノードですね。
noise_seedはシード値のことです。
control_after_generateは、連続で生成する時にシード値をどのように変更するかを指定する項目です。基本的には”randomize”で良いでしょう。
KSamplerSelect
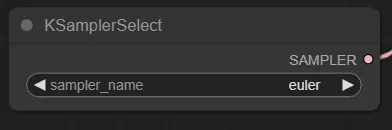
サンプラーの指定です。お好きなのを選択してください。
Empty Latent Image
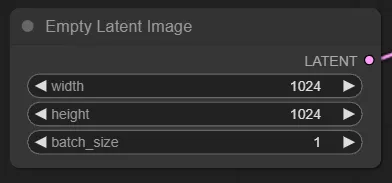
生成される画像のサイズの指定と、バッチサイズを指定できます。
Load VAE
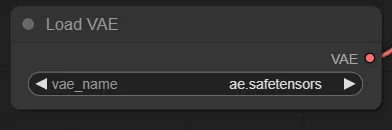
VAEを指定するノードです。ae.safetensorsを指定します。
スポンサーリンク
生成してみよう
これで生成準備が整いました。
それでは早速プロンプトを入力して生成してみましょう。

ちなみに、上記の画像のプロンプトに“anime illustration”というようなワードを追加するとイラスト風の画像が生成されます。

ちなみに、アニメ系モデルで使用されるプロンプト、所謂danbooruタグでプロンプトを入力すると”anime illustration”など指定しなくてもイラスト風の画像が生成されます。

最後に
ローカルで動かせる画像生成AIの種類も増えてきましたね。
FLUXはまだアニメ系モデルも無くLoRAなどもありませんが、現状でもクオリティの高い画像を出せるので、派生モデルにも期待ですね。
それでは!



コメント